由于self-Attention太贵,出现了2个方案:
这两个方案一个是linear-Attention,从复杂的核函数入手,试图将self-Attention从二次复杂度转换为线性复杂度。例如Minimax、Qwen3-Next都是这条路线。
另一个方案是Native Sparse Attention(NSA),将完整的注意力进行稀疏化,使其可以用更少的计算完成常规self-Attention近似的效果。一个典型的使用就是DeepSeek V3.2-Exp。
二者通过不同的方案,最终目的都是降低计算复杂度or降低kv cache的使用。
DSA(NSA)
DeepSeek V3.2-Exp使用的的DeepSeek(Dynamic?) Sparse Attention[1,2]。这个方案是由DeepSeek的ACL 2025 best paper(NSA)发展而来,该方案当时被cursor的CEO看好,也是最近被热议的下一代llm的方向之一。
Aman Sanger(联合创始人):希望他们下一个模型能用上。这种注意力机制的可扩展性很好,据说效果比传统注意力更好。核心原理是把注意力分成三部分。一部分是滑动窗口注意力,主要关注最近发生的内容,比如最近 4000 个 Tokens。剩下两部分则是分块注意力。它会每隔一段 Token,把那段内容作为一个 “块” 的 key 和 value 保存下来,然后 query 会去关注这些块。之后再从这些块里选出最相关的前 K 个,最后对这些块做全局注意力。我觉得这种做法很酷,因为它确实能很好地在很长的上下文里做检索。
NSA其实就是多组注意力的集合,他们能做到更稀疏(也就更快、更节省kv cache,V3.2的kv cache大概可以节约80%(相较于v3)),同时在性能也可以保持。
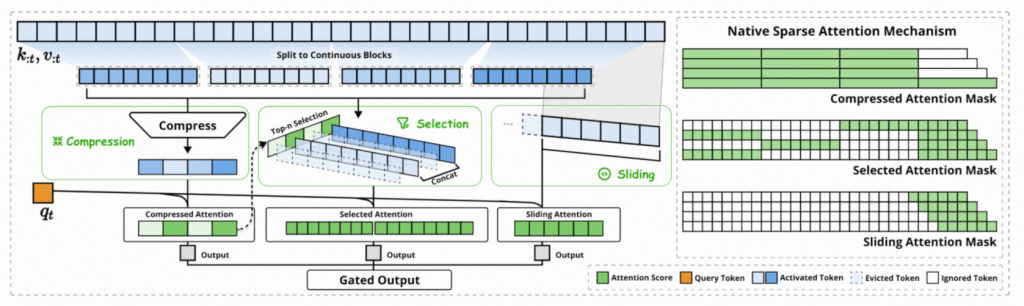
而DSA在NSA的基础上做了一定的取舍,去掉了compression分支,也取消了滑窗。直接在V3的基础上新增了一个Indexer(Lightning Indexer)。主要动机其实是为了方便进行continue pretraining。
在介绍V3.2之前,我们先回看一下V3的结构。
Deepseek
DeepSeek V3使用了MLA并在14.8T token进行训练,同时,也使用创新的使用了MTP来进行训练。
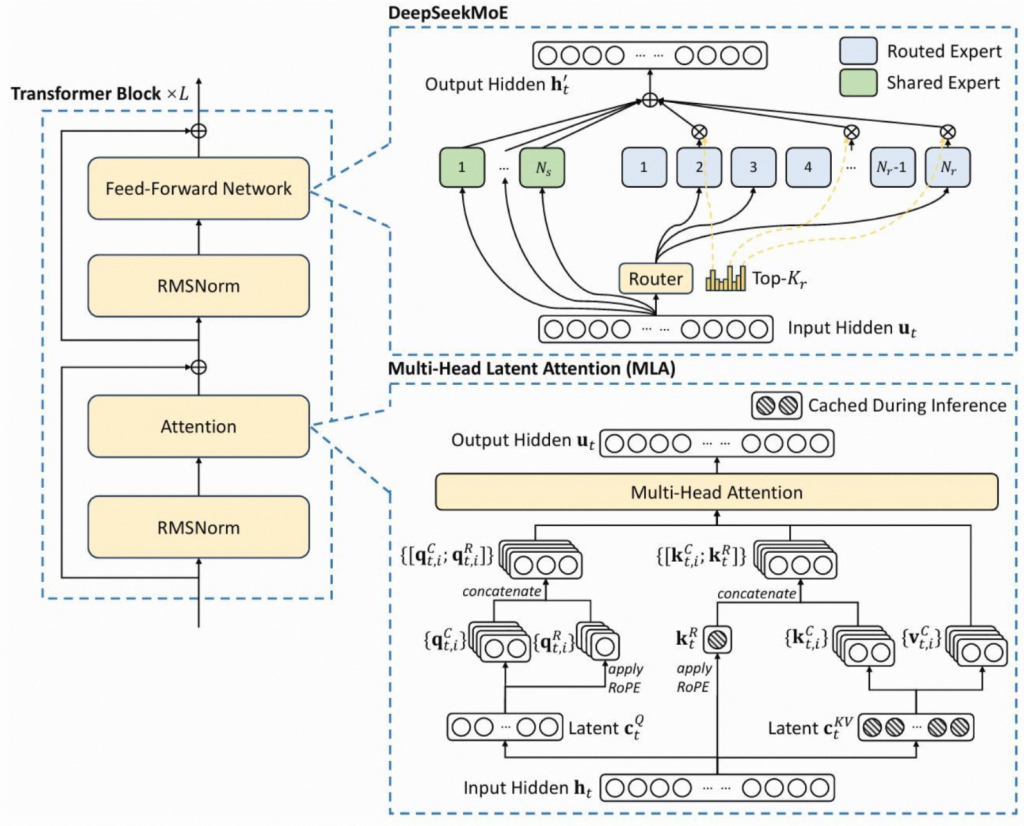
具体来说,我们观察MLA的具体实现,由于RoPE的复杂度也比较高,因此我们可以看到首先对q、kv进行了2次lora变换(红框内),主要目的是分离出两组参数,只对其中一组较小的q/k进行RoPE操作,因此可以再一定程度上加快运算速度。
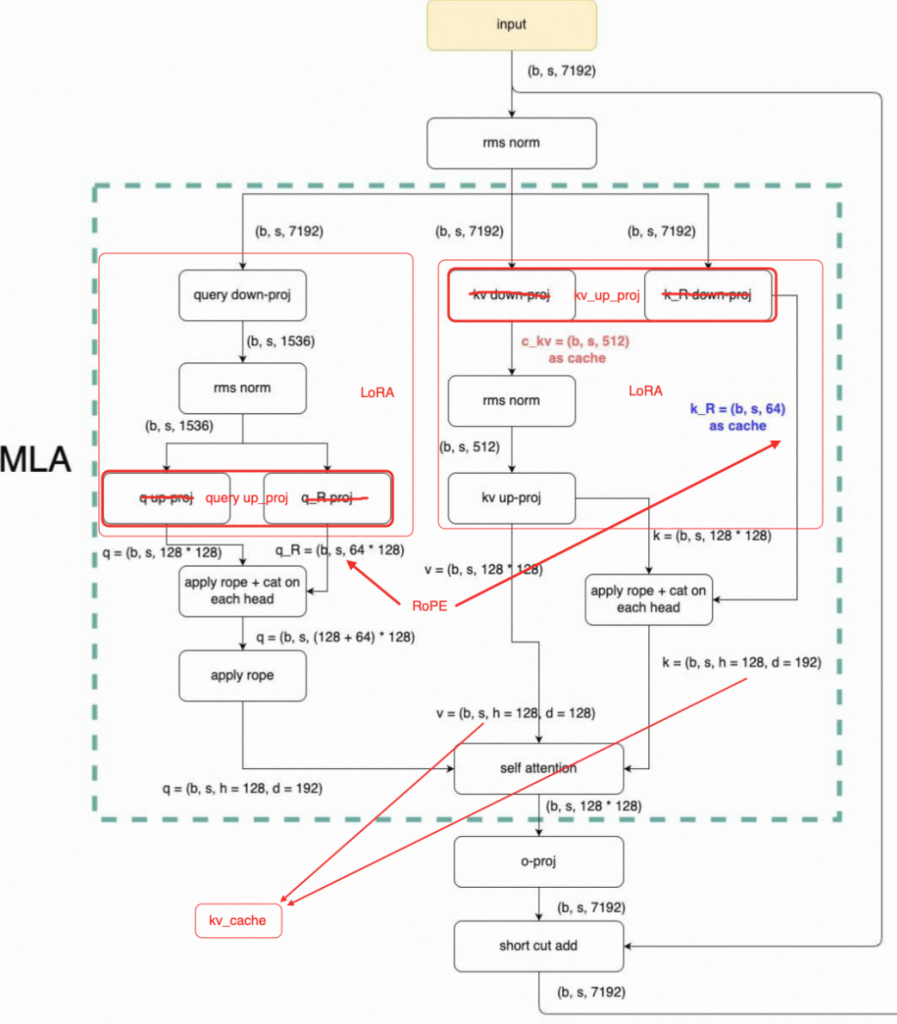
而v 3.2,进行了2处更改。可能是考虑到continue training的需求,实际上V3.2并没有使用一开始提到的NSA,而是使用了一个DSA,他是在V3的基础上进行continue training完成。
改动主要有以下两点:
- 通过数学恒等变换,将kv_cache前移。相比v3的完整cache,v3.2使用了低秩cache,进一步节省了kv cache开销。在解码时,通过恒等变换,使用两个小cache即可完成推理(计算换存储)。
- 引入NSA的Indexer和top k select,选择重要的topk token进行运算,mask掉其余位置的Attention。
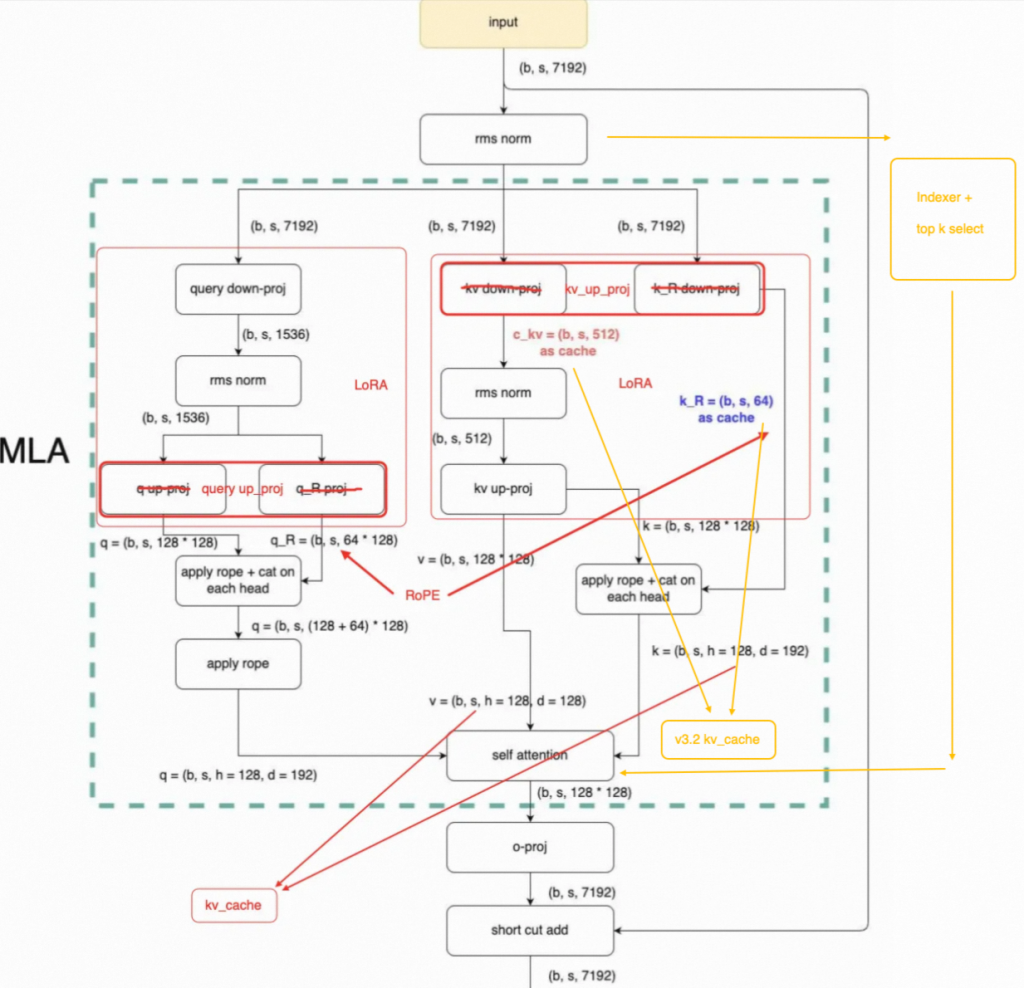
v3.2相比v3,推理效率进一步提升。但是主要提升的点是cache的节省。
Linear Attention
Linear的核心思路是通过改变矩阵的惩罚顺序,将 (QKᵀ)V 转换为 Q(KᵀV),实现复杂度从 O(N²d) 到 O(Nd²) 的根本性突破。
说到Linear Attention就不可避免的必须提到Linear RNN。Linear RNN里的线性指的是去掉传统RNN中的非线性依赖,从而支持并行计算(卷积或者parallel scan);而线性attention里的线性指的是去掉softmax,从而降低原来序列长度平方的计算开销。
尽管两者的出发点不同,在decoder-only架构的背景下,Linear Attention + causal mask可以表达成Linear RNN的形式,只是状态空间从以往的向量变成了矩阵,可以看成是一种扩大状态空间的做法。线性注意力本质上是一个具有矩阵值状态的线性 RNN。
我们知道很多优秀的Linear模型例如Mamba、Based等,我们将以RWKV(线性rnn)和 DeltaNet(线性attention)为例继续介绍,二者都是Linear Attention中较为典型且优秀的代表。
正如我们之前对Linear Attention的初步介绍中(【论文】一个基于状态转移的高效推理框架)提到的,Linear Attention之所以没有取代self Attention,罗列除了几个可能的原因,现在我们重新整理Linear Attention的优缺点:
优点:
- 低时间复杂度。Linear顾名思义,将复杂度由平方复杂度降为线性复杂度,节省了宝贵的计算时间。
- 低空间复杂度。在节省时间的同时,Linear由于不会对每个token都进行一些缓存,空间复杂度O(n)。Linear只会有一些固定的缓存空间,既常数项O(1)的空间复杂度。
- 长序列任务。Linear的长文本能力较为优秀相比self-attention更容易做到32k、100k甚至更长的长度。这使得Linear Attention相比self Attention就具有更多的可能性。例如高分辨率图片解析&生成、高采样率的视频理解和生成、长序列TTS、长时间用户历史行为等的想象空间更大。
- 具备TTT特性(Test Time Training)。由于所有的状态都被存储在一个状态矩阵中,因此可以模拟梯度下降的策略来更新这个状态矩阵,也就做到了在推理中训练。增强了长序列任务的可靠性。
优点显著,缺点同样显著。主要有:
- 信息有损压缩。由于所有的状态都被存储在一个状态矩阵中,信息有损压缩,当序列长度远超隐藏状态的容量时,这种压缩就会产生信息丢失,这种丢失对于需要精确召回的特定任务(如检索)是致命的。
- 对prompt敏感,没有回顾机制。同样是由信息压缩导致的,假设一个输入序列 [text,question],由于在早期不确定任务性质,因此模型往往不知道什么信息需要被压缩,什么(例如输入一个阅读理解题,但是实际问模型有多少个数字),会导致无效信息被压缩,造成性能下降。因此纯Linear模型往往对prompt很敏感,必须要问题前置。
- 注入性。Linear Attention可能具有注入性。简单说就是由于取消了Softmax,采用 ReLU,因此对于不同的x可能会有同一个y的情况。如下图对于不同的q1/q2/q3,都有相同的向量表示。这会对模型的性能造成负影响。
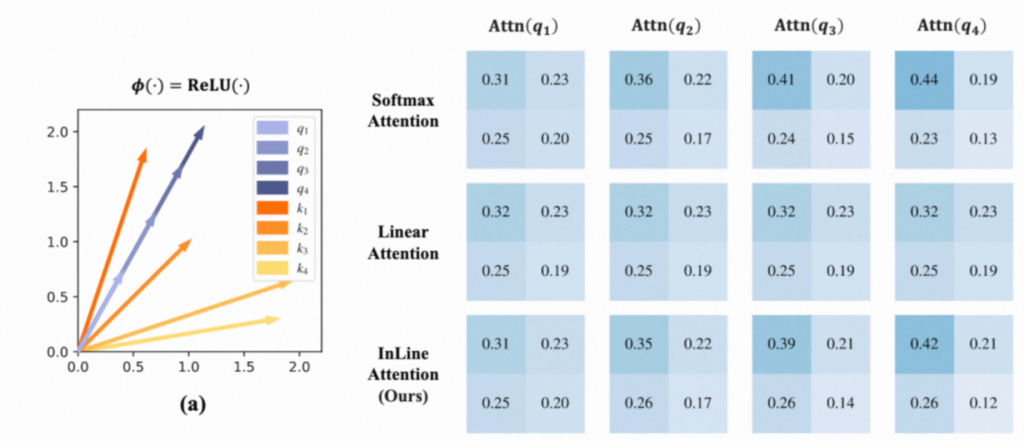
- 注意力分散。Linear Attention很难做到像self Attention一样将大部分注意力集中在一个部位(比如几个token上),主要原因依然是由于softmax导致,由于没有映射,Attention score必须依靠神经元直接输出,因此很难出现极高值。这导致整体注意力比较分散。
- 训练效率问题。虽然Linear Attention的时间空间复杂度都比较低,但是由于矩阵运算具有特殊性,现在GPU对于矩阵计算的优化已经十分优秀。同时在causal的情况下,将Attention计算方式由左乘改成了右乘会出现不能用矩阵计算的问题,必须适应累加求和,这就导致了必须使用for循环而不能使用高效的矩阵运算,这限制了模型在训练阶段的效率。
以上这些缺点是原生Linear Attention具备的问题,现在越来越多的研究都在试图解决这些缺点,不过例如在之前paper weekly中介绍过的Lightning Linear Attention以及我们接下来要介绍的RWKVs、DeltaNet等,已经在逐步解决这些缺点。
Receptance Weighted Key Value(RNNs)
RWKV是一个典型的线性RNN模型,它和传统的Transformer模型的主要区别在于注意力层。
在RWKV中,自注意力(self attention)被替换为位置编码(Position Encoding)和TimeMix,而前馈网络(Feed-Forward Network,FFN)被替换为ChannelMix。这些改动使得RWKV在保持Transformer高效并行训练的同时,也能够在推理时保持较低的计算和内存复杂度。
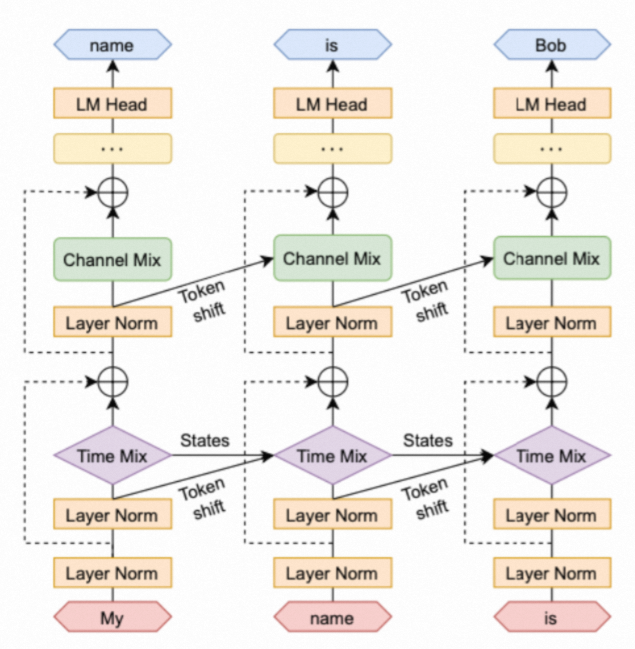
其中,Time-Mixing和Channel-Mixing的状态转移方程如下,

让我们抛弃数学语言,人话描述一下这个算子:他干的事是把前文和它有语义相关性的所有token拿过来,加权混合他们的embed信息,贡献给下一个token。
不过RWKV结构相对复杂,也一直在进行迭代,在最近的RWKV-8中,还添加了一个回顾机制,用来解决上文我们提到的对prompt敏感这一问题。回顾机制是指在一次前向传播中,显式地处理历史状态(或历史输入)并将其融入当前状态计算的过程。
回顾机制是一个O(n)复杂度的后缀自动机,通过这个自动机模型在一定程度上可以回看,但是整体能力依然有限,不过这也提供了一个高效优雅的解决方案,为后续的工作了提供了一个切实可行的解决方案。
不过RWKV并没有解决训练效率问题,以及复杂的使用成本。
DeltaNet
传统的 Linear-Attention 模型通常采用简单的累加或带衰减的累加方式来更新隐藏状态。这种方式虽然简单高效,但可能不是最优的信息融合策略。
DeltaNet 提出了一种新的更新规则,其核心思想是,隐藏状态的更新应该使得模型能够更好地重构或预测未来的信息。具体来说,DeltaNet 的更新规则可以看作是在每一步都最小化一个局部的均方误差(MSE)损失。
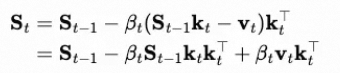
可以理解为:新状态=旧状态+误差。比如你在瞄准,现在偏左,那么新状态其实就是当前状态的偏左+向右的误差。因此,St-1 相当于“偏左”,v_t是target,那么二者差值就是“向右调整”,在给予一个适当的学习率,构成下一个状态。因为有这个自适应的学习率存在,实际上还可以做到状态的动态选择。
因此,DeltaNet的优势主要为:
- 采用 MSE 损失而非线性损失,提供更强的误差校正能力
- 动态学习率 β_t 实现自适应记忆更新
- 理论上等价于 Test-Time-Training (TTT) 的特殊形式
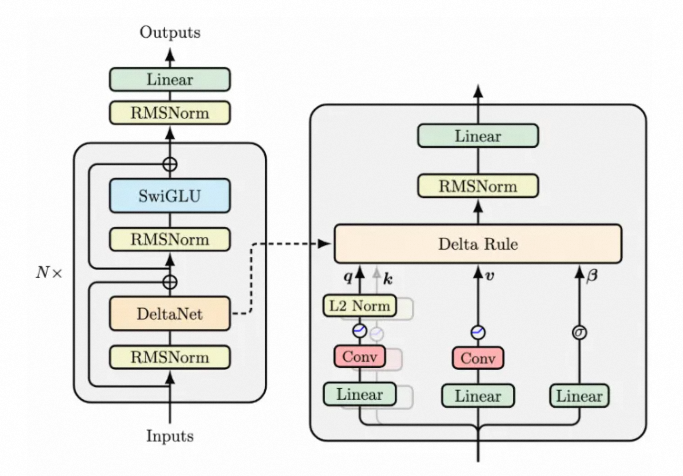
我们注意到,这个模型还是用了一个短卷积,这主要是用来捕获局部依赖,弥补模型全局注意力的不足的问题。
Qwen3-Next
介绍完了DeltaNet,介绍我们的重头戏Qwen3-Next,一个80A3B的极致稀疏的模型,设置了512个专家,在推理时使用1个共享专家和10个激活专家。仅对前25%的位置维度添加RoPE、时使用MTP(multi-token Prediction)进一步提高模型的训练效率与推理性能。
训练数据由Qwen3的36T训练数据均匀采样的一个15T子集构成。尽管在model card中提到,Qwen3-Next的吞吐能力是Qwen3的7~10倍,但是由于现有infra支持很弱,实际上Qwen3-Next目前的成本是显著大于同等尺寸的Dense模型的。这主要是因为目前Linear的基建相对较弱,还需要社区跟进相关算子的优化。
Qwen3-Next在结构设计上比较保守,不像Minimax-01在87.5%的层中使用Linear Attention,Qwen3-Next在75%使用了Gated DeltaNet(GDN,在DeltaNet继续添加一个Gate,用来消除Attention sink)来进行长距离建模,25%使用了标准self-Attention来保留例如检索等关键能力,提升关键token的捕捉能力。

这个模型由于使用了很多的新技术例如Gate Attention、MTP、Zero-Centered RMSNorm、融合架构以及高稀疏MoE等,性能得到了显著提升,在激活3B的情况下,在部分核心指标上媲美Dense 32B。
总结
本文介绍了NSA和Linear(RNN)两个方案,
Linear流派,假设前文所有信息都可以通过只看一遍就被压到一个固定state里。因此长文下state能力不行,记不住信息,性能捉急。
sparse流派,例如nsa,假设前文有用的token至多只有k个,k是远小于n的常数。假设太强,更多的是基于经验,如果某时刻实际需要的token比k多,那就不行了。
同时,二者都没有“回顾前文所有语义相似的token”功能,也就是说都可能需要一个类似于RWKV-8的回顾机制来解决这一问题。
不过这一限制依然是对于纯Linear/sparse模型来说。目前的Linear模型也会在中间穿插标准self Attention来恢复一部分索引性能,而V3.2也并不是传统滑窗一类的的NSA,V3.2通过Indexer来构造Attention的稀疏性,用过Indexer来选择重要token来二次构造稀疏性,不过这个稀疏性并没有改变实际参与Attention运算的矩阵大小。
未来的形态,也可能依然是self Attention的某种改进。就像 It is easy to make a smart model cheap,but is hard to make a cheap model smart,目前Linear和NSA相比self attention依然是有一定的性能劣势,但是随着模型的发展,也仅仅在某些任务上存在一些劣势。但是更可能是二者的某种结合,毕竟Linear的想象空间足够大,性能优化的也差不多了,如果真的有无限上下文长度的一天,可能模型微调就消失了,同时一些高消耗的多模态任务也更容易落地。
0 条评论