<Bert>、<NSP>、<zero-shot>
论文解读仅代表个人观点,才疏学浅,如有错误欢迎指正,未经授权禁止转载。
论文原文:https://arxiv.org/abs/2109.03564
这是一篇尚未收录的文章,目前在arxiv下,根据改论文github更新显示,该仓库不久后会有一个较大更新,猜测是论文录用以及实验补充。
摘要
近年来,很多实验都表明NSP是一个失败的预训练任务,相较于MLM任务,NSP任务过于简单,因此在模型训练上并没有什么明显的提升,训练过程中NSP的acc很快就会达到90%甚至更高。
因此例如Roberta、Albert等,均将NSP任务做了不同程度的修改。
但是本文揭示了Bert的NSP一个其他用途,通过该方式,我们可以以zero-shot或者few-shot的方式进行例如文本分类、完形填空等任务,从而获得更多的伪标签以作后续的模型训练。
方法
本文的方法如下,对于不同的任务,在第二句输入不同的选项,通过Bert的NSP输出判断选项是否“合理”。
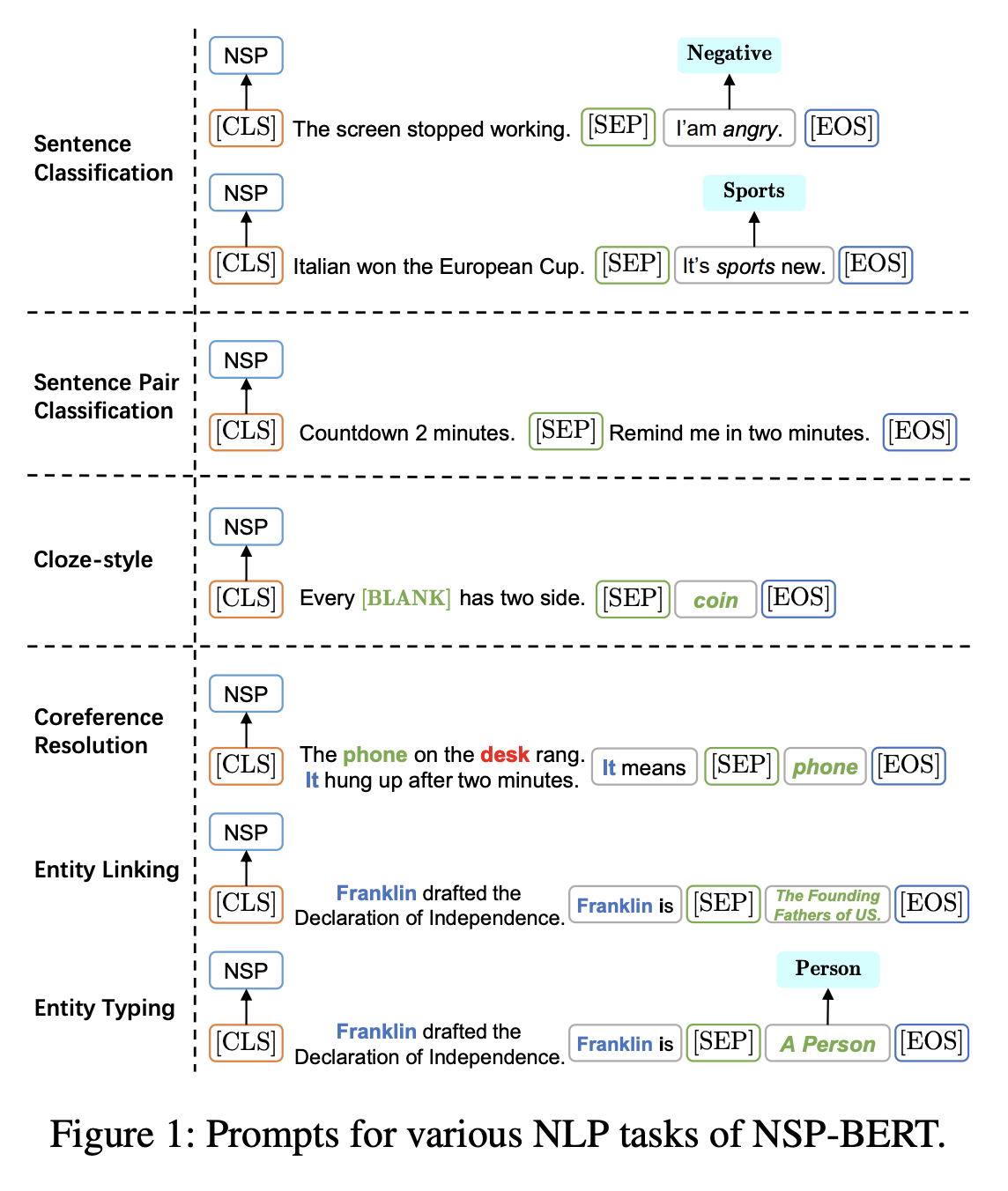
实验
等全文发表后补足。
结论
等全文发表后补足。
总结
其实这篇文章已经出现过一段时间了,同时处于“尚未发表”的状态, 是一个又新又旧的论文,之所以冷饭热炒拿出来,就是因为最近可能需要一些“伪标签”类似的数据标注,做了一下相关的实验,拿出来整理汇总一下。
下面是我的实验部分。
实验代码比较简单,因为就是基于原生Bert的NSP结果(以下实验结果均基于zero-shot)。
import os
os.environ['TF_KERAS'] = '1'
from bert4keras.tokenizers import Tokenizer
from bert4keras.snippets import sequence_padding
from bert4keras.models import build_transformer_model
texts = [
['梅西超越贝利成为南美射手王', '这是一篇体育新闻'],
['梅西超越贝利成为南美射手王', '这是一篇音乐新闻'],
['梅西超越贝利成为南美射手王', '这是一篇娱乐新闻'],
['贾斯汀比伯发布新单曲', '这是一篇体育新闻'],
['贾斯汀比伯发布新单曲', '这是一篇音乐新闻'],
['贾斯汀比伯发布新单曲', '这是一篇娱乐新闻'],
]
model = build_transformer_model(
config_path='./chinese_L-12_H-768_A-12/bert_config.json',
checkpoint_path='./chinese_L-12_H-768_A-12/bert_model.ckpt',
with_nsp=True
)
tokenizer = Tokenizer('./chinese_L-12_H-768_A-12/vocab.txt')
batch_token_ids = []
batch_segment_ids = []
for text in texts:
token_ids, segment_ids = tokenizer.encode(text[0], text[1])
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
output = model.predict([batch_token_ids, batch_segment_ids])对于文本分类任务,论文使用的是prompt形式的输入(idx:0越大代表next的概率越大):
['梅西超越贝利成为南美射手王', '这是一篇体育新闻'],0.99795,0.00205
['梅西超越贝利成为南美射手王', '这是一篇音乐新闻'],0.08799,0.91201
['梅西超越贝利成为南美射手王', '这是一篇娱乐新闻'],0.86283,0.13717
['贾斯汀比伯发布新单曲', '这是一篇体育新闻'],0.93378,0.06622
['贾斯汀比伯发布新单曲', '这是一篇音乐新闻'],0.99938,0.00062
['贾斯汀比伯发布新单曲', '这是一篇娱乐新闻'],0.99727,0.00273可以看出,整体来说,第一条被预测为体育,第二条被预测为音乐/娱乐。个人认为这两个都还算对。
但是我发现,zero-shot模式下,一个字符的变化就可能会对结果产生很大的影响:
['梅西超越贝利成为南美射手王', '这是一篇娱乐新闻'],0.86283,0.13717
['梅西超越贝利成为南美射手王。', '这是一篇娱乐新闻'],0.04528,0.93378但是值相对不是很高,通过卡阈值或者few-shot可以缓解这一问题。
同时,我还尝试了不同的prompt方式与不是用prompt:
['梅西超越贝利成为南美射手王', '这句话是关于体育的'],0.72072,0.27928
['梅西超越贝利成为南美射手王', '这句话是关于音乐的'],0.00951,0.99049
['梅西超越贝利成为南美射手王', '这句话是关于娱乐的'],0.05801,0.94199
['贾斯汀比伯发布新单曲', '这句话是关于体育的'],0.02010,0.97990
['贾斯汀比伯发布新单曲', '这句话是关于音乐的'],0.82243,0.17757
['贾斯汀比伯发布新单曲', '这句话是关于娱乐的'],0.11396,0.88604
['梅西超越贝利成为南美射手王', '体育'],0.99745,0.00255
['梅西超越贝利成为南美射手王', '音乐'],0.02688,0.97312
['梅西超越贝利成为南美射手王', '娱乐'],0.09481,0.90519
['贾斯汀比伯发布新单曲', '体育'],0.01490,0.98510
['贾斯汀比伯发布新单曲', '音乐'],0.99447,0.00553
['贾斯汀比伯发布新单曲', '娱乐'],0.97993,0.02007可以看出对于样本2,更换prompt方式后,音乐类别与其他类别的区别更加明显,同时对于不使用prompt的结果,和原文prompt方式结果分布基本一致。说明整体来说NSP-Bert有效,但是有一些依赖于prompt方式。
而在意图识别上,
['ok谢谢', '没有'],0.96902,0.99990
['ok谢谢', '谢谢'],0.99990,0.00010
['ok谢谢', '再见'],0.98421,0.01579
['ok谢谢', '好的'],0.99227,0.00773
['ok谢谢', '这句话的意图是“没有”'],0.94576,0.05424
['ok谢谢', '这句话的意图是“谢谢”'],0.99984,0.00016
['ok谢谢', '这句话的意图是“再见”'],0.98268,0.01732
['ok谢谢', '这句话的意图是“好的”'],0.98432,0.01568可以发现如果卡一下阈值,基本都判断对了——至少这句话没有“没有”的意图,也可以发现,一个好的prompt提示,可以拉大不同标签之间的差距。
至于其他的例如完形填空的能力,由于bert4keras不支持不切分字符,SEP要自己改,我嫌麻烦哈哈哈,就暴力测试了一下
['每一个什么都有两面', '硬币'],0.44779,0.55221
['每一个什么都有两面', '汽车'],0.04262,0.95738从结果上看,Bert依然“知道”硬币有两面。
0 条评论