开一个新坑,这个坑主要用来总结一些FAQ和遇到的一些有趣的结论。会慢慢的持续更新。
看到新的论文也会更新已有的FAQ。所以其实也不都是增量更新。
因为我会在notion先记,有时间了再整理到博客上,所以大概率很久更一次,一次更很多。因此:
有人催更请按1,有人提问请按2,有人讨论请按山,有人搬运请直接拨110!!
LLM更新太快了,实际上我是很希望有人跟我一起讨论一起成长的~快来
最近更新时间:2024.04.20
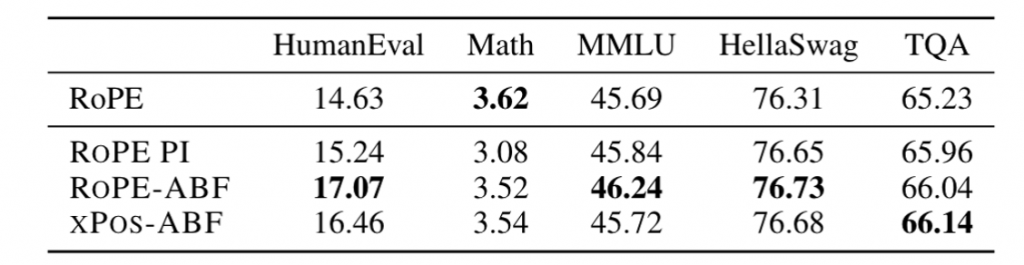
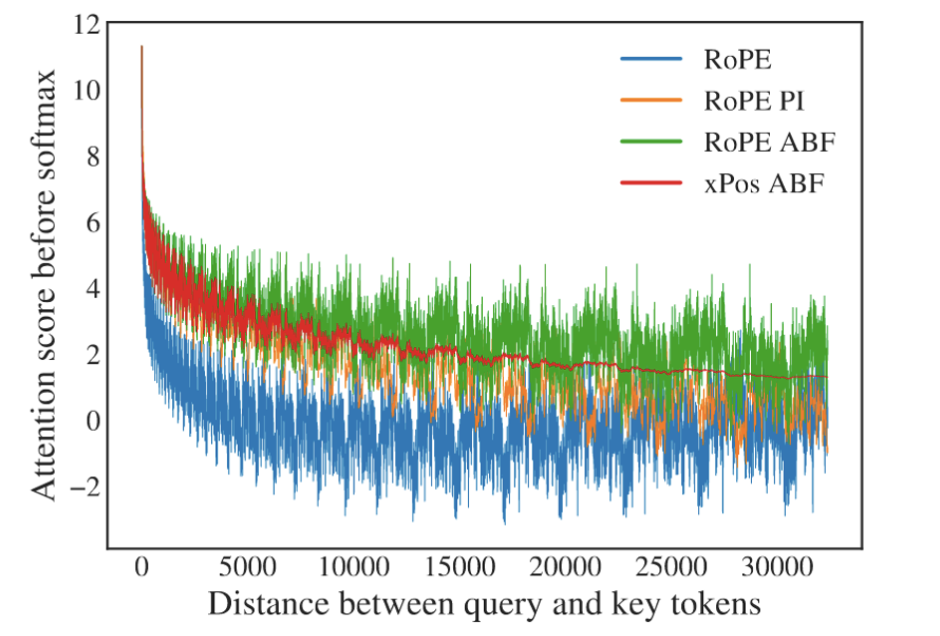
1.ALiBi和RoPE的区别?有什么性能优劣呢?
目前都说AliBi的外推性要好一些,有一些实验(eg:ALiBi自己的论文)也确实证明了这一点。但是Bloom的论文也说RoPE比Alibi的效果更好一点。
百川在7b和13b上使用了不同的位置编码,由于不具有可比性,也没有什么确切的信息来证明这一点。不过一些信息来看,似乎他们更相信ALiBi具有良好的外推性。
但是BTLM-3B-8K(http://arxiv.org/abs/2309.11568)的实验也说明,ALiBi只有在模型训练的比较差的情况下(少量token)才会增加模型的外推性,但是对于精细训练的模型来说,并不会具备多么好的外推性。但是ALiBi的loss确实会低一些(相同TFLOP的情况下,会低1%左右)。
Meta的一篇论文(http://arxiv.org/abs/2306.15595 )认为,RoPE会在一定程度上阻止注意力之间的远程交互,但是也提出了一些改进来缓解这个问题(increasing the “base frequency b” of ROPE from 10, 000 to 500, 000)。RoPE在远端引入了较大的震荡,这对于语言模型可能是不利的(http://arxiv.org/abs/2309.16039 and http://arxiv.org/abs/2212.10554 )。
2.权重衰减?层正则化?
权重衰减(weight decay)和 Layer Normalization(LayerNorm)是两种不同的正则化技术,它们的目的和作用方式略有不同。
- 权重衰减: 权重衰减是一种通过修改损失函数来约束模型参数的正则化方法。它的主要目的是防止过拟合,通过对模型的权重参数添加 L2 正则化项,鼓励权重参数的值趋向于较小的值,从而降低模型的复杂性。权重衰减有助于使不同的权重更均匀,减少了模型对某些特定参数的过度依赖,降低了模型对训练数据的噪声敏感性。
- Layer Normalization: Layer Normalization 是一种归一化技术,通常用于深度神经网络中的每个层。它的主要目的是加速训练过程,改善梯度传播,以及减少训练中的内部协变量偏移(Internal Covariate Shift)问题。LayerNorm 将每个层的输入进行均值和方差的归一化,使得每个特征维度都有相似的统计特性,从而有助于网络的训练和泛化。LayerNorm 不是为了减小参数的值,而是为了使每一层的输出保持更稳定的分布。
在实践中,通常可以同时使用权重衰减和 Layer Normalization 来提高模型的性能。它们有不同的作用和效果,可以协同工作以改善模型的稳定性和泛化能力。权重衰减主要用于减小参数的值,降低过拟合风险,而 Layer Normalization 主要用于加速训练和改善梯度传播,提高网络的训练效率。
(2024.01.26更)
3.attention中,为什么需要Wq、Wk、Wv?既然是self-attention,直接x*x不就行了?
假如直接用 x和 x 做scale-dot就会到得一个对称矩阵,多样捕捉注意力的能力就会受限, i和j 位置之间的前后向注意力就会变得一样(matrix[i][j]==matrix[j][i]),而我们一般期望两个token在一句话中先后顺序也能反映一定的不同信息。
最重要的,这个对称矩阵的对角线上的值一定是本行最大的,(修正:这里并不一定是最大的,而是大概率是最大的),这样 softmax后对角线上的注意力一定本行最大,也就是不论任何位置任何搭配,每个token的注意力几乎全在自己身上,这样违背了Transformer用来捕捉上下文信息的初衷。所以乘上Wk、Wq、Wv后有三个好处:
- 增加了参数量,增加模型的表达能力。
- 加入了不同的线性变换相当于对x做了不同的投影,将向量x投影到不同空间,增加模型的泛化能力,不要那么hard。
- 允许某个token对其他位置token的注意力大于对自己的注意力,才能更好的捕捉全局位置的注意力
(2024.04.20更)
4.为什么需要多头?多头的目的是什么?
5.Flash Attention的作用,几个版本之间的区别是什么?
先说区别:
FA1:
from: https://arxiv.org/abs/2205.14135
flash attention主要是将QKVO计算拆块拿到了SRAM中(类似于cpu的cache,相比memory具有更快的吞吐),使用online safe softmax(也就是不需要完整通信,只通信几个值(max(x)和指数和),就可以等价于正常的全员softmax,详见https://www.zhihu.com/question/611236756/answer/3132304304)。
在反向传播时,重新计算Q*KT和softmax,使得整体运算都在SRAM之内,降低了HBM访问次数,显著提升了计算速度。
FA2:
from: https://arxiv.org/abs/2307.08691
由于GPU具备单独的矩阵运算单元(以A100 GPU为例,其FP16/BF16矩阵乘法的最大理论吞吐量为312 TFLOPs/s,但FP32非矩阵乘法仅有19.5 TFLOPs/s,矩阵单元的运算速度是非矩阵运算速度的16x),因此如果可以继续减少非矩阵运算,就可以进一步提升计算速度。
那么用途很明显是加快计算。FA相比其他的“加速”方案,抛弃了别人一直使用的降低模型TFlops的思路,改为通过提升TFlops降低吞度。有效的对模型的训练进行了加速。同时由于减少了中间激活值的缓存,在一定程度上还可以节省训练和推理中的显存占用。
1 条评论
思无邪 · 2024-05-11 22:27
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36
催更催更。
暗号123221