前言
虽然DeepSeek R1为大家提供了一个使用强化学习来完成推理能力的路线,但是最关键的技术和细节往往被隐藏,因此社区内还没有复现他们的结果。
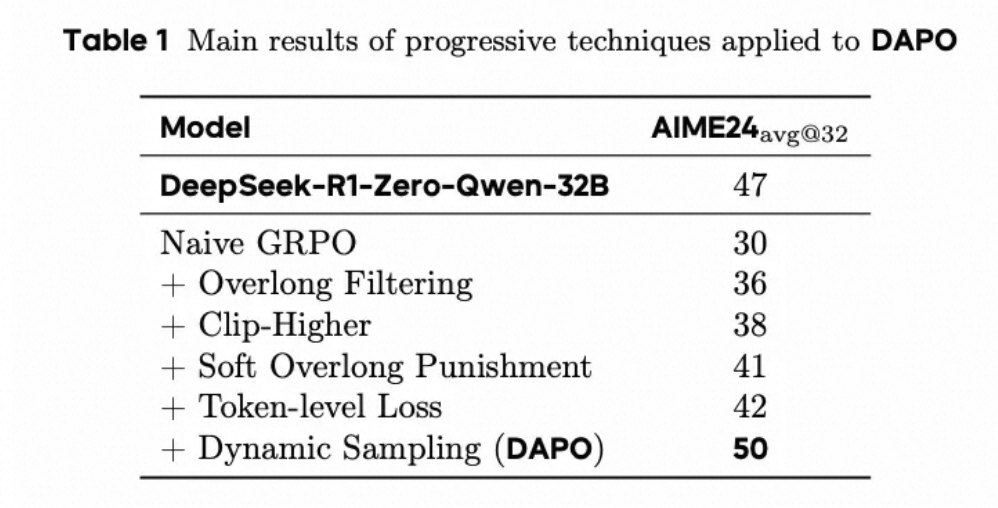
字节跳动Seed+清华大学提出了解耦裁剪和动态采样策略优化(Decoupled Clip and Dynamic sAmpling Policy Optimization,DAPO)算法,并且开源了相关代码和论文,该系统在AIME2024上达到了50分。

主要的改进为:
- 新增裁剪偏移(Clip-Shifting),促进系统多样性并且允许自适应采样。
- 动态采样(Dynamic Samping),提高训练效率和稳定性。
- Token级策略梯度损失(Token-Level Policy Gradient Loss),这在长CoT RL场景中至关重要。
- 溢出奖励塑造(Overflowing Reward Shaping),减少奖励函数的噪音并且稳定训练。
前置知识
PPO
PPO的算法流程主要有5个步骤:
- 生成文本(Rollout):策略模型为不同的prompt生成大量的样本。
- 获取分数(Reward):使用奖励模型为每个样本进行打分。
- 计算优势(Generalized Advantage Estimation,GAE,广义优势估计):计算每个单词选择的优势与劣势,考虑奖励和价值函数的预测。
- 优化LLM(策略更新):更新LLM模型以最小化PPO损失。
这个损失函数主要有以下几个部分:
- 奖励:鼓励更高的奖励,他能推动模型生成更高分数的样本。
- 限制(剪切目标):他能防止策略在一次更新中变化过大,保持训练稳定性。
- KL惩罚:如果新策略与旧策略偏差太大,就会进行惩罚,进一步增加模型训练的稳定性。
- 熵奖励:熵用来衡量生成文本的“随机性”和“多样性”。增加熵可以鼓励模型更多的探索,它有助于防止模型过早的进入“确定”模式,从而防止过拟合的发生。
为什么是GAE?
- 蒙特卡洛(MC)—— 高方差,低偏差:想象一下等到整个文本生成后再获得奖励,然后将该奖励分配给文本中的每一个单词。足球赛,信用分配问题,对单个动作的信号非常嘈杂。高方差,学习速度慢。
- 时间差分(TD)—— 低方差,高偏差:在每一个动作后都给予一个奖励,信号不那么嘈杂,学习速度更快。但是,我们只是局部地判断,并不是所有的贪心解厚实最优解,因此会有偏差,可能会陷入局部最优解,错过更优秀的方案。
- GAE —— 平衡:广义优势估计(GAE)就像“多步 TD”。它考虑了多个步骤(单词)上的奖励,平衡了方差(MC)与偏差(TD)之间的权衡。就像不仅在结束时给予奖励,还在价值函数预测的指导下,为沿途的“小步骤”给予奖励。
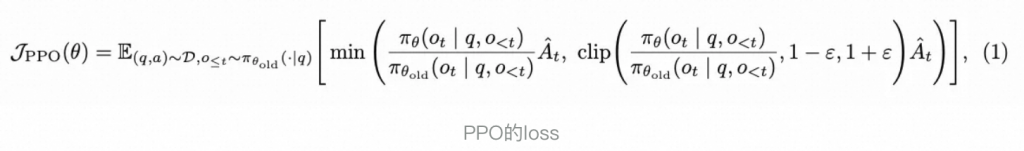
DPO
直接告诉LLM,response A > response B。
DPO的损失包括:
- 使用类似于文本分类的交叉熵相似的loss来增加首选项的logits和概率,同理,降低非首选项的logits和概率。
- 保持和参考模型(例如sft模型)相对接近。
GRPO
GRPO是一个更简洁的PPO算法。他去掉了Value模型,使算法由4个模型缩小为3个,降低了显存需求并且提高了训练速度。
那么如何解决缺失的value模型呢?GRPO通过对同一个prompt,使用LLM进行n次采样,计算一个平均得分来估计value(GRAE)。
整体训练流程为:
- 生成响应:对同一个prompt生成一组响应。
- 组内进行打分:使用Reward model对每个样本进行打分。
- 计算组内相对优势(GRAE):通过比较并且归一化每个response在组内的平均奖励来计算优势。
- 优化策略(PPO优化):使用loss对LLM进行更新。
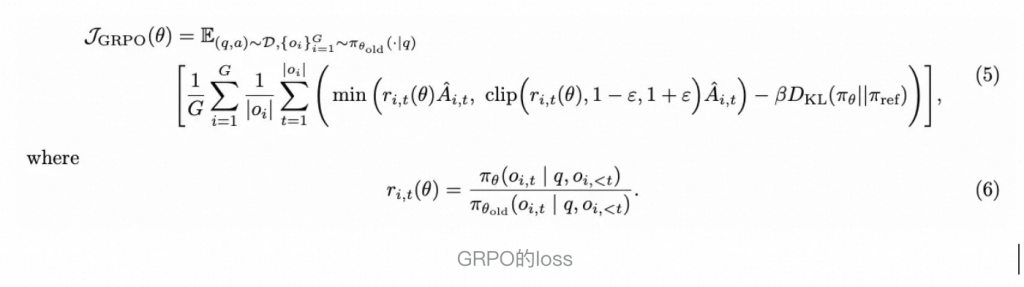
DAPO
主要改进
移除KL散度
由于常规RLHF模型的目的是对齐,需要和原模型不能有较大的偏差,但是对于Long CoT模型,首先任务上就有较大的分布转移,因此有KL散度是一个较差的约束。
我们的实验也证明了去掉KL散度(系数0)性能是有一定的提升的。
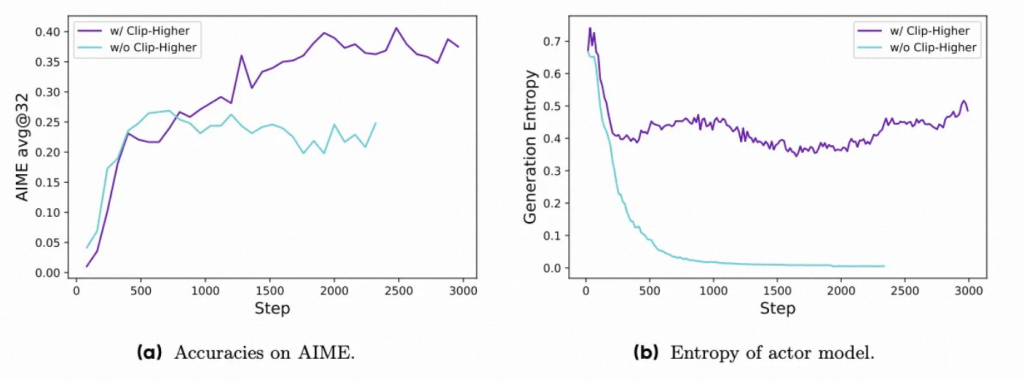
裁剪偏移(Clip-Shifting)
熵坍缩现象现象,导致某些组生成的结果几乎相同,限制了探索。(Entropy Collapse(熵坍塌):在强化学习训练中,模型输出的概率分布变得过于集中,导致探索能力下降,多样性降低的现象。可以理解为模型变得“懒惰”,只倾向于选择少数几个高概率的动作,而忽略了其他可能的动作。)
为什么clip的机制会影响概率?准确来说,是限制了低概率Token的概率增长,从而限制了多样性。
具体来说,clip 机制抑制了低概率Token的增长,它们可能永远无法成为高概率Token,因此模型更倾向于维持原有的高概率Token(高概率Token更容易保持高概率或继续增加),而不是探索新的Token,导致生成的内容缺乏多样性。DAPO将下裁剪范围εlow设置为0.2,上裁剪范围εhigh设置为0.28,从而在保持稳定性的同时提升策略的多样性。
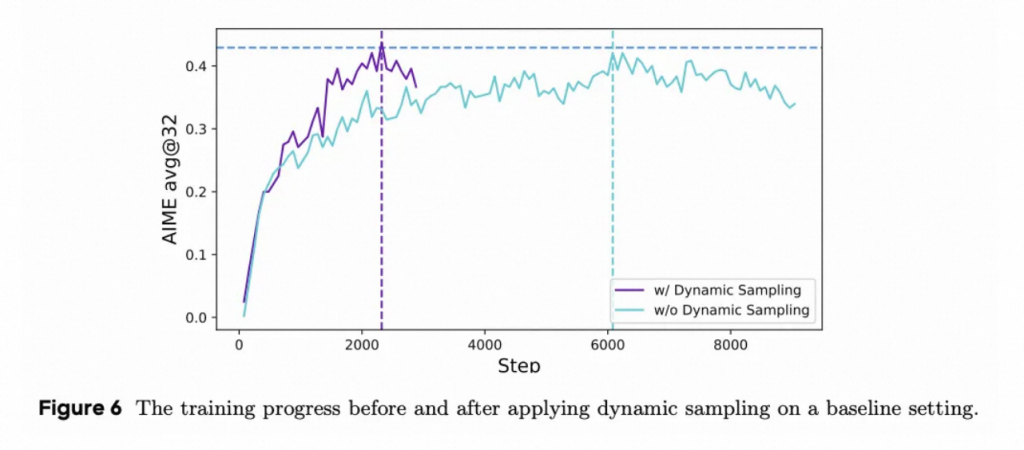
动态采样
现有的 RL 算法在某些提示的准确率等于 1 时通常会遇到梯度减少问题。例如对于 GRPO,如果特定提示的所有输出都是正确的,那么该组的结果优势为零。零优势导致策略更新没有梯度,这意味着每个批次中有效提示的数量不断减少,这可能导致梯度方差更大,并削弱模型训练的梯度信号。
因此,DAPO会过滤采样准确率为0和1的样本,直至样本内不完全为0和1。持续过滤全对/全错样本,实际上构建了一个「中等难度」训练集,这样可以保证每个 batch 中的样本都能对模型的训练产生积极作用,此外带来了训练效率的提升,更快地达到相同的性能。
Token级策略梯度损失
原始的 GRPO 算法采用样本级损失计算,这涉及首先在每个样本内按 Token 平均损失,也就是,每个样本对总Loss是等权的。
随后汇总样本间的损失。在这种方法中,每个样本在最终损失计算中被分配相同的权重。然而,这种损失降低方法在长思维链 RL 场景中引入了几个挑战。
由于所有样本在损失计算中被赋予相同的权重,较长响应中的 Token 对整体损失的贡献可能不成比例地低,这可能导致两种不利影响。
- 对于高质量的长样本,这种效应可能会妨碍模型学习其中与推理相关的模式。
- 对于低质量样本(过长的样本通常会表现出低质量的模式,如无意义的词语和重复的词汇)由于样本级损失计算无法有效地惩罚长样本中的这些不良模式,导致了熵和响应长度的非正常增加。
简单说,就是让token在不同长度的response里能够对loss中有相同的贡献。
因此,在loss计算时,去掉了sample的影响,直接对loss求均值,从而间接的达到了token级别loss计算的要求。
if use_token_level_loss:
pg_loss = verl_F.masked_mean(pg_losses, eos_mask)
else:
pg_loss = torch.sum(pg_losses * eos_mask, dim=1) / seq_len_per_sample
pg_loss = torch.mean(pg_loss)最终不管是acc还是长度变化,都变得更稳定了。
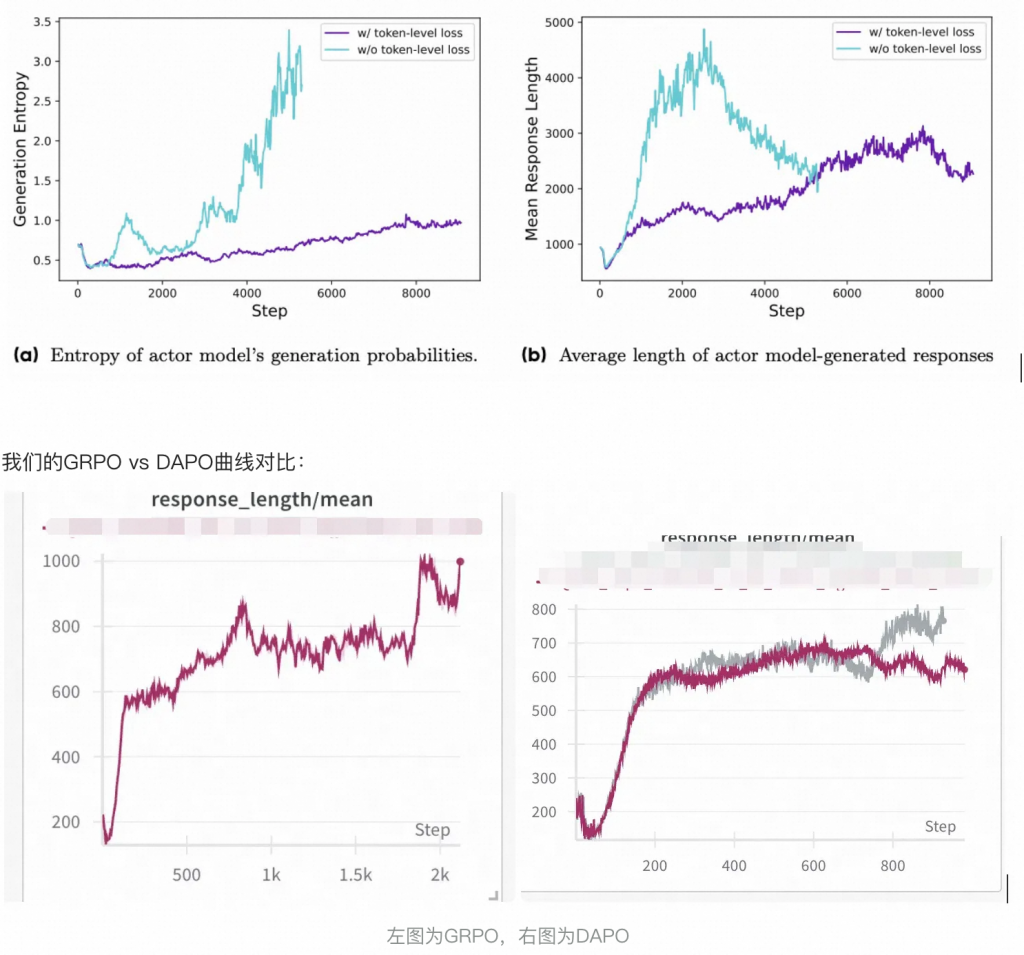
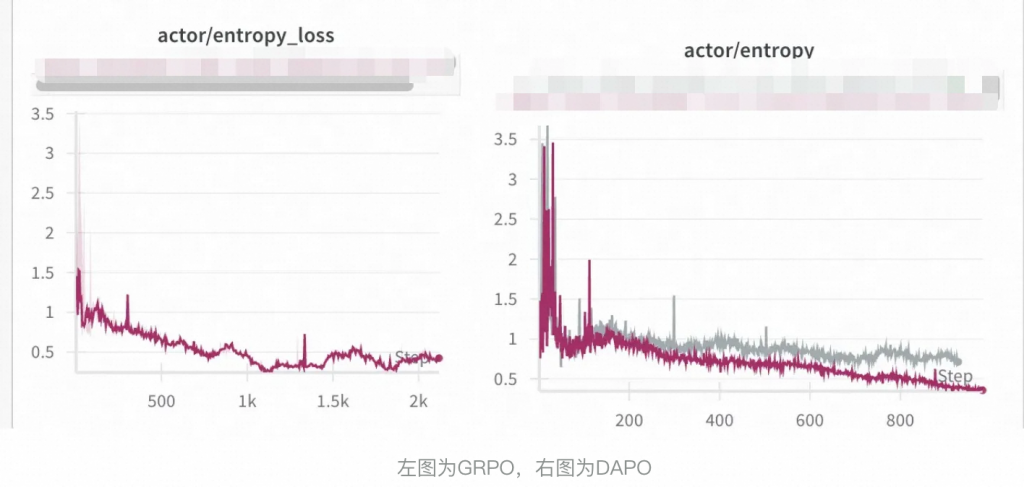
整体看,DAPO曲线上更加稳定。
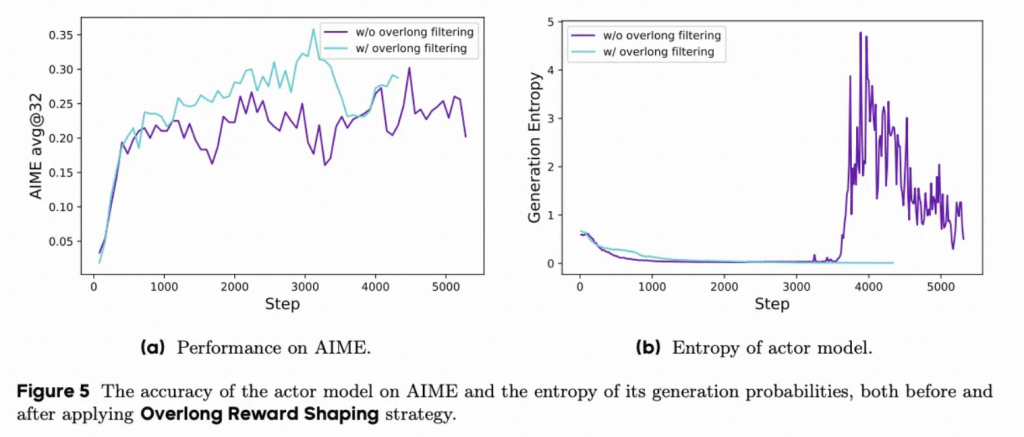
溢出奖励塑造
在loss中屏蔽对超长文本的惩罚。常规的做法是对超长的文本直接给一个负分Reward,但是这样可能会存在文本推理是高的,只不过由于各种原因(例如难题)超长了,但是这时候给一个负向Reward可能会对优化方向有一定影响。因此本文还对超长文本在loss级别进行了mask,防止他们影响优化方向。
同时给出软惩罚。当输出长度接近最大长度时,逐步给予长度惩罚,防止输出过长。

效果
最终效果,32B模型成功达到了50分的AIME效果。
0 条评论