之前对于bert的MLM任务一直都是模棱两可,今天对于实现细节进行了补全。
想看结论的直接拉到最后。
mlm的流程实际上是使用token,通过变换获得一个vocab size大小的输出,从而判断预测位置的单词。
其实一开始是在研究bert4keras时,发现输出的参数和我想象中的对不上啊,然后向下深究代码。最后在transorfmers中找到了结果。
本文就打算根据我的思路历程来编写。
最近在做bert4keras的文档,做到AutoRegressiveDecoder的时候遇到了之前的一个问题,当任务为lm或者unilm时,bert会被切换到mlm模式,也就需要对token进行预测。
增加的结构为:
__________________________________________________________________________________________________
Transformer-11-FeedForward-Norm (None, None, 768) 1536 Transformer-11-FeedForward-Add[0]
__________________________________________________________________________________________________
MLM-Dense (Dense) (None, None, 768) 590592 Transformer-11-FeedForward-Norm[0
__________________________________________________________________________________________________
MLM-Norm (LayerNormalization) (None, None, 768) 1536 MLM-Dense[0][0]
__________________________________________________________________________________________________
MLM-Bias (BiasAdd) (None, None, 21128) 21128 Embedding-Token[1][0]
__________________________________________________________________________________________________
MLM-Activation (Activation) (None, None, 21128) 0 MLM-Bias[0][0]
__________________________________________________________________________________________________
cross_entropy (CrossEntropy) (None, None, 21128) 0 Input-Token[0][0]
MLM-Activation[0][0]
我们可以看到,多出来了 MLM-Dense、MLM-Norm 、MLM-Bias几处。
那我就很奇怪,这个结构是怎么预测token的?MLM-Dense只是一个很基础的dense,768*768+768,bert4keras中代码如下:
if self.with_mlm:
# Masked Language Model部分
x = outputs[0]
x = self.apply(
inputs=x,
layer=Dense,
units=self.embedding_size,
activation=self.hidden_act,
kernel_initializer=self.initializer,
name='MLM-Dense'
)因此,输出还是768维度的,为什么可以和21128的MLM-Bias进行相加?
(傲,我突然发现可以从MLM-Bias后面的Embedding-Token[1][0] 发现猫腻,算了,先假装不知道)
百思不得其解,于是去查看transformers的源码。
transorfmers的torch实现:
class BertLMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = BertPredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states我们可以看到,初始化了一个BertPredictionHeadTransform和一个Linear, Linear 为hidden size * vocab size。
这里是不是科学了一点?最起码输出是一个vocab size大小的变量了,然后再加一个bias。
那我们现在看看 BertPredictionHeadTransform
class BertPredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states我们发现这里初始化了一个768*768+768的Linear,是不是眼前一亮?这好像数目对上了。
然后就是LN一下,然后就是一个 hidden size * vocab size 的Linear(上面那段代码)。
至此,也就输出到了vocab size大小的向量,就可以输出对应的token了。
但是这里呢,有一个细节不太明显,我们继续查看tf的代码:
不上代码了,太长了,后面会有截图。想看跳转github
长了好多,我们继续把TFBertPredictionHeadTransform的代码一并在下面展示出来。
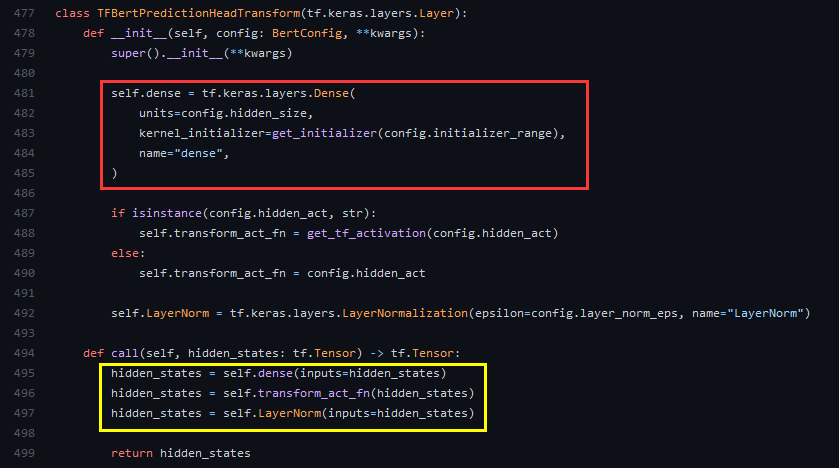
可以看到这里初始化了一个768*768+768的Dense(红)。隐藏层通过这个dense,激活之后,进行LN操作(黄)。
那么整个流程就可以变为:
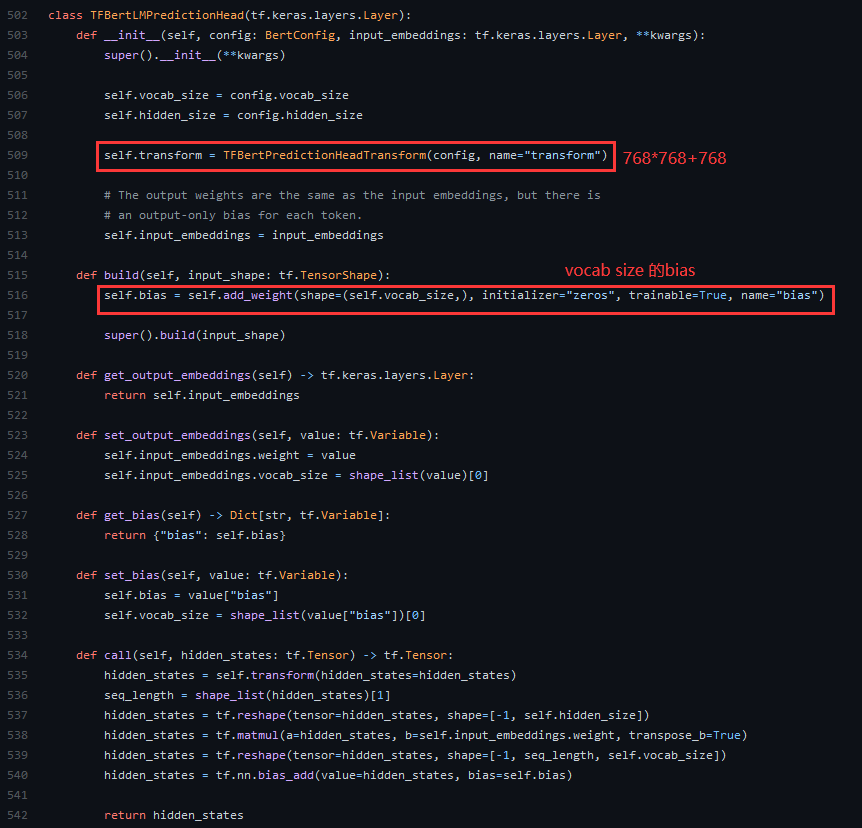
虽然最后也是输出的vocab size,但是依然不能解决我们。
但是我们查看细节:
在call中我们可以发现:(重点来了傲!)
首先,就是将bert的输出( seq length *768)通过一个768*768+768变换( seq length *768),然后通过矩阵相乘,变换成seq length*vocab size(reshape),随后对每一个单词添加一个偏置bias随后输出。
而矩阵变换是( seq length * 768)*(768* vocab size)最后得到( seq length *vocab size)。而最关键的这个 (768* vocab size) ,我们通过观察变量名:input_embeddings.weight,就可以发现,实际上这个就是输入的embedding,只不过转置一下,相当于输入变输出(相比embedding过程),因此在这里实际上是参数复用。
也就是说,我们假设有一个字“你”,将 [101,770,102]( [CLS,你,SEP] )输入到embedding中,最后输出3*768维向量进入bert中计算,最后将bert输出反向送入embedding中,试图让 embedding 继续输出 [101,770,102] 的过程。
所以,到现在我们就理清了mlm的思路:
将bert的输出(512*768)通过一个768*768+768的变换,变成(512*768),然后通过与embedding(21128*768)的转置(768*21128)相乘,获得(512*21128)的向量,再加上对每一个字的一个偏置(1,21128),从而可以获得每一个位置的输出。
PS:有没有产生一个疑问(反正我有)? 直觉上,embedding->token和token->embedding应该是一个可逆过程,为什么这里要使用 768*768+768 的Dense还要添加一个 (1,21128) 的偏置呢?
因为。。我把问题想简单了,这个直觉不准, embedding->token和token->embedding 并不是一个可逆过程,对于Embedding层当然可逆,可是我们现在要处理的是经过了12层transformer处理后的“embedding”,因此我们需要这个Dense和bias。
2021.09.16更:今天看到了一个关于bert的名词:weight tying,看解释感觉就是这里的东西。查了一下其实就是这里的参数共享。
但是,虽然是共享,但是他们并不是同一个层,因为他们都有着各自的Dense层。使用这种方法既可以减少参数量,也可以加快训练速度。
2021.11.13更:苏建林师兄在最近的博客里也说明了为什么MLM要多加Dense。
5 条评论
1 · 2021-10-21 18:52
开源了吗
Ysylvia_ · 2021-11-02 15:50
请问 bert的MLM 的预训练参数是不是没有保存?
咸鱼 · 2021-11-09 15:55
实际上最后一层为什么要加一个dense层,可以看看苏剑林的这篇博文,写的还是很详细的,纯粹从数学的角度思考的。https://spaces.ac.cn/archives/8747
Sniper · 2021-11-13 14:30
十分感谢。苏神的博客我也一直有在追。感谢大佬
袁叔叔不会飞 · 2022-03-14 16:34
牛哇~ 我也是看到这里一脸懵,大佬解决了我的疑惑,瑞思拜!