模型细节
词表从140~2000左右,留了超过2000个保留token,其中195、196分别被用来当做user token id 和 assistant token id。
base模型的拼接方式为:
chat模型的拼接方式为: system prompt + user token id + user prompt + assistant token id + model response + eos token id
数据筛选
数据多样性
- 从不同的来源获取数据,建立一个类目体系,可以提升对整体数据分布的把控,方便后续增减。
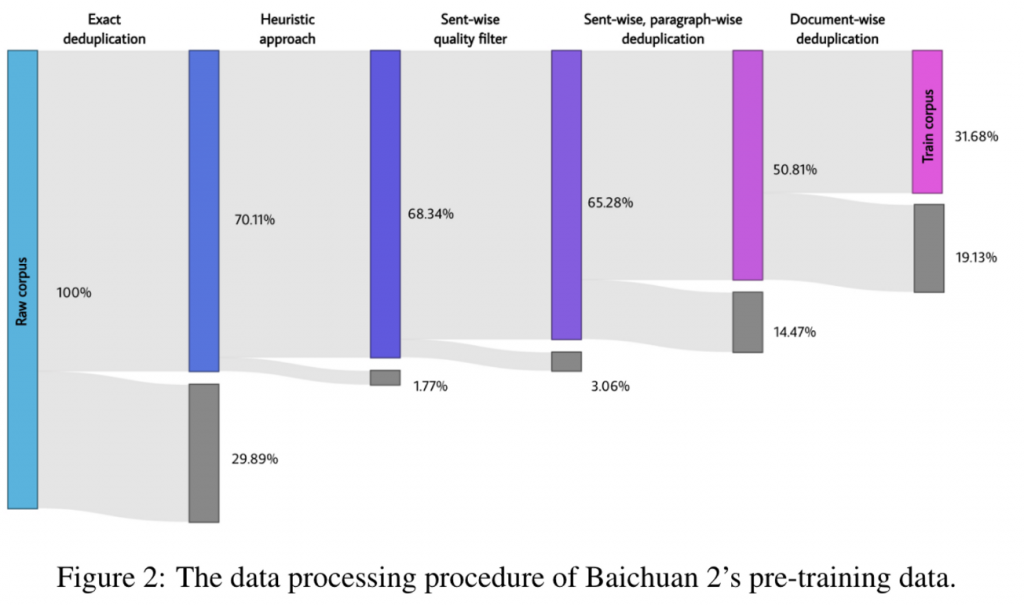
- 进行聚类和去重,可以通过LSH局部敏感或者稠密向量作为聚类特征,LSH更快一些,但向量可以更好地编码语义。但这里有个问题是需要卡阈值,去重过猛会影响多样性降低泛化能力。因此百川选择的做法是去除一部分,并对剩余的样本打分,作为预训练时采样的权重。从美团的实验来看,低阈值去重<高阈值去重<中阈值去重,应该也是因为高阈值去重会牺牲多样性。
数据质量
1.采用分类器进行过滤,baichaun并未透露具体的分类器,但是应该是类似于Bloom的做法,训练一个gpt来做分类?
2.基于启发式的规则来进行质量过滤,比如符号比例?中英文占比?….
3.找一些高质量、正价值观数据,重采样。
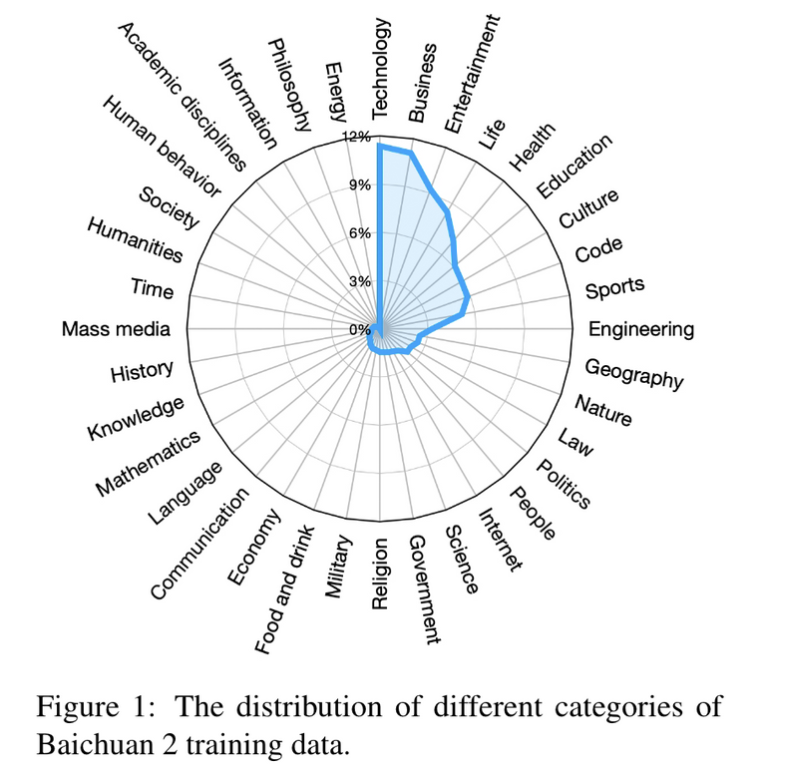
数据分布
这里猜测是通过语义聚类随后人工/GPT4打标签,获取数据的分类标签。
数据过滤
tokenizer
- 对原始数据不做任何归一化
- 把数字完全拆开,可以更好理解数值数据
- 为了代码数据,专门增加空格token
- 覆盖率在0.9999,只有少量fall back(一种避免OOV的方法,在碰到unknown中文时会变成utf8的byte token)
位置编码
不管是7B的RoPE还是13B的ALiBi,没有观测到显著的因为位置编码带来的性能变化。
训练
- 混合精度训练
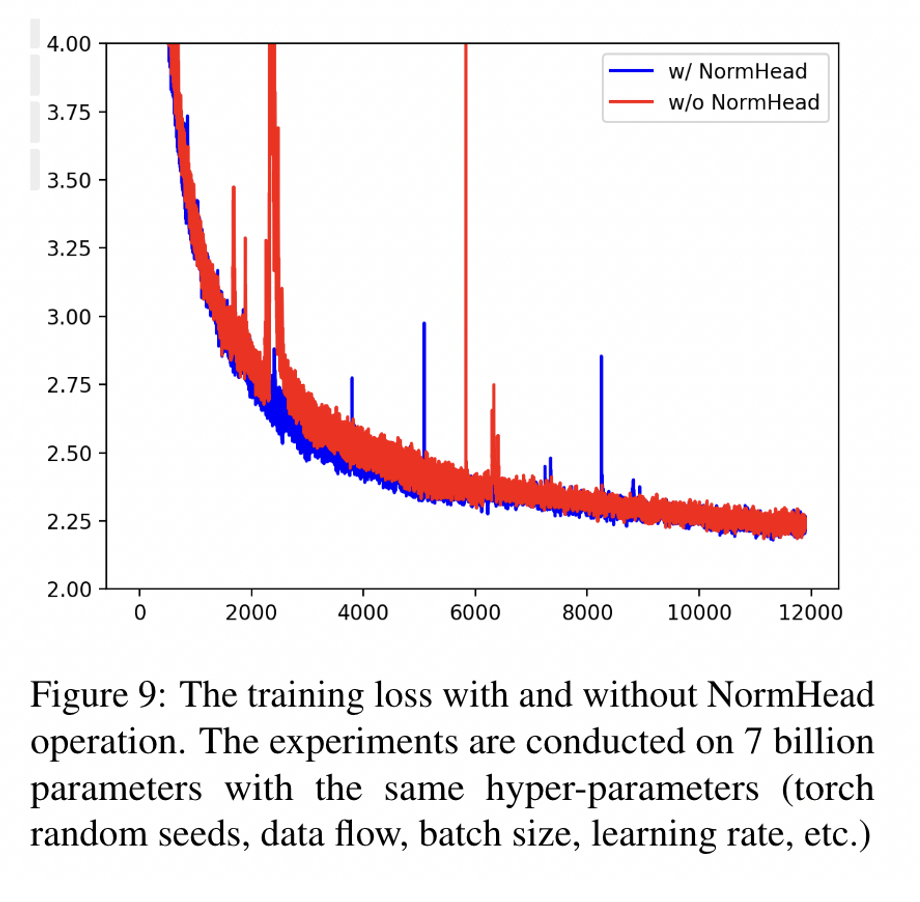
- 对输出logit进行标准化(类似于做一个门控机制)。由于低频token在训练时模长会变短,因此使用标准化来消除一部分低频token的影响。实验结果表明会加快loss下降。
- 使用max-z loss拉低模型的logit,提高模型对超参的鲁棒性。


SFT
- 数据质量:采用抽检的方式进行质量把控,抽一批数据检查,不合格全部退回。
- 数据数量:100k
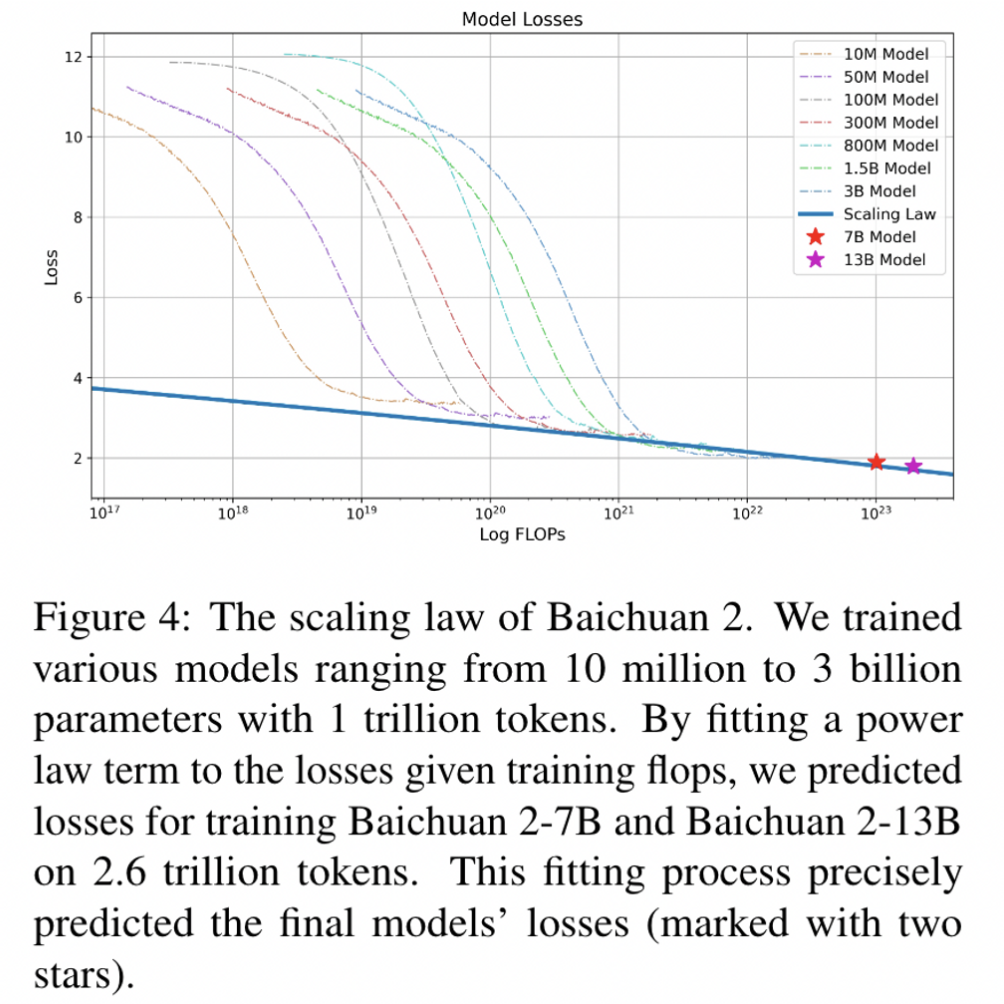
scaling law
验证了多个模型的loss下降趋势,准确的预测了7B和13B最终的收敛位置。
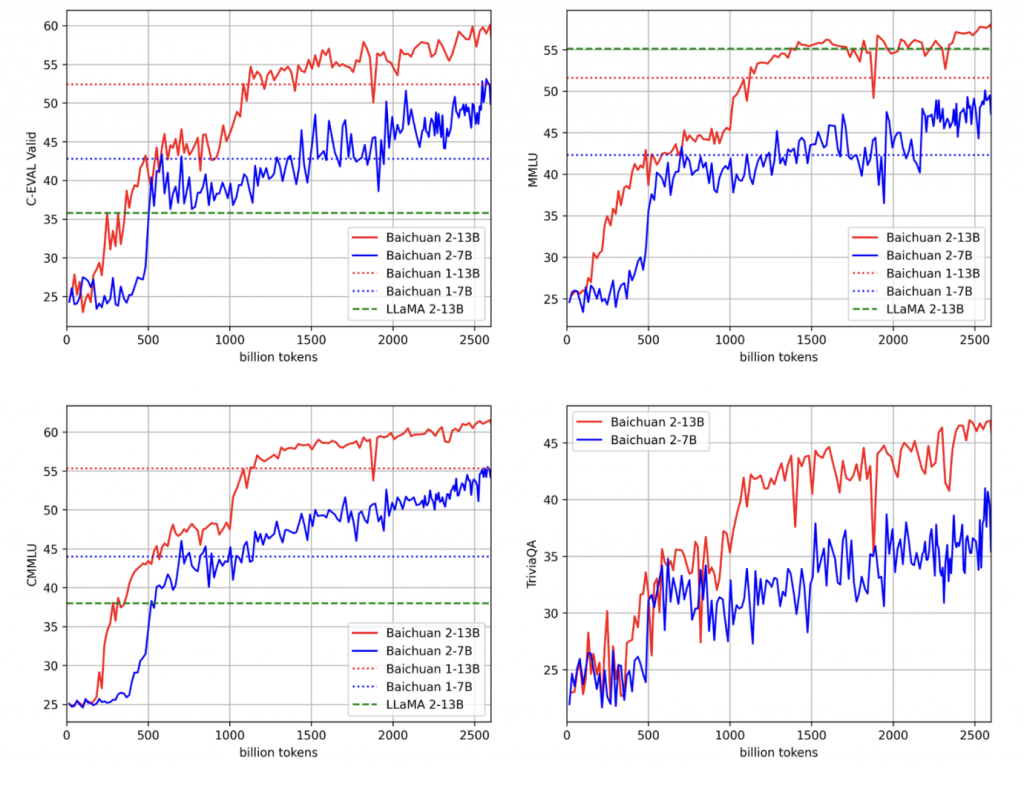
大力出奇迹
可以看出baichuan2在baichaun1的位置时,和1的性能基本一致,大力出奇迹。
同时也可以看出模型的性能在200~500Btoken时,有过一个很强的能力涌现。
引用
- Baichuan2 tech report: https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
0 条评论