摘要
- DeepSeek-R1 相关调研
(Scaling Test-Time Compute/Human-like Long Thought o1, R1/RL)
- R1 复现工作(业界和我们)
(SFT/DPO/PPO, Open-Ended Solution e.g. Marco-MT/ 形式主义的长思考/Aha v.s Sad)
DeepSeek-R1 相关调研
DeepSeek 分为了Zero和R1两个版本。DeepSeek-R1-Zero(简称 Zero)与 DeepSeek-R1(简称 R1)。
- DeepSeek-R1-Zero:直接从基座模型(base model)开始,利用大规模强化学习(RL)进行训练;
- DeepSeek-R1:在基座模型上先进行小规模的监督微调(SFT),再进行多轮强化学习与再微调,最终获得更好的可读性与通用能力。
模型介绍
DeepSeek-R1-Zero
zero是在DeepSeek-V3-Base的基础上,直接进行约8000步RL(GRPO)得到的。
- GRPO(Group Relative Policy Optimization) 是 DeepSeek 团队提出的一种高效替代传统 PPO 的强化学习算法,能够节省一个和策略模型等规模的价值函数模型,从而更好地节省显存与计算资源;
- 训练时主要针对数学、编程与逻辑推理等易于通过自动验证方式进行奖励计算的任务。例如,对于数学题,会用匹配答案或检测正确结果的方式提供奖励;对于代码题,会调用编译器或测试用例进行验证。模型若能输出正确解,则获得正奖励;若未正确输出或格式不符,则获得负奖励或较低奖励。
经过上述约 8000 步 RL 更新,Zero 在一些关键推理基准上取得了明显增益。其中一个典型案例是 AIME(数学竞赛题目)的 pass@1 指标:
- 从初始的 15.6% 提升到了 71.0%,意味着模型仅通过强化学习就得到了较强的数学推理能力。
对于zero的冷启动,主要还是依靠了模型自带的指令遵循能力,通过在问题前注入一些指令,让模型分布拆分,整体看更依赖于模型的预训练能力与预训练数据,也更容易出现例如Aha Moment(有些实验表明,Aha Mmoment实际上是从预训练数据中得到的,因此如果中间隔了sft,实际上是更远离了Aha moment)。

这一现象说明,即使没有专门的监督数据(如人类写好的长链式推理示例),模型也能自行学会在中途发现并修正错误,从而展现出更复杂的推理策略。
Reward Model
Zero 所使用的奖励函数比较简单:
- 正确性奖励:对最终输出是否正确进行判断(对于code直接使用解析器、对于math直接使用匹配既正确答案是否在模型output中出现);
- 格式奖励:对回答中是否包含指定的推理与答案框架进行检测(如使用预先设定的分隔符、输出 pattern 等)。具体来说:看CoT过程是否以标准
<think> </think>包裹。
这么看起来似乎暴力又简单的方法,效果却出奇地好。
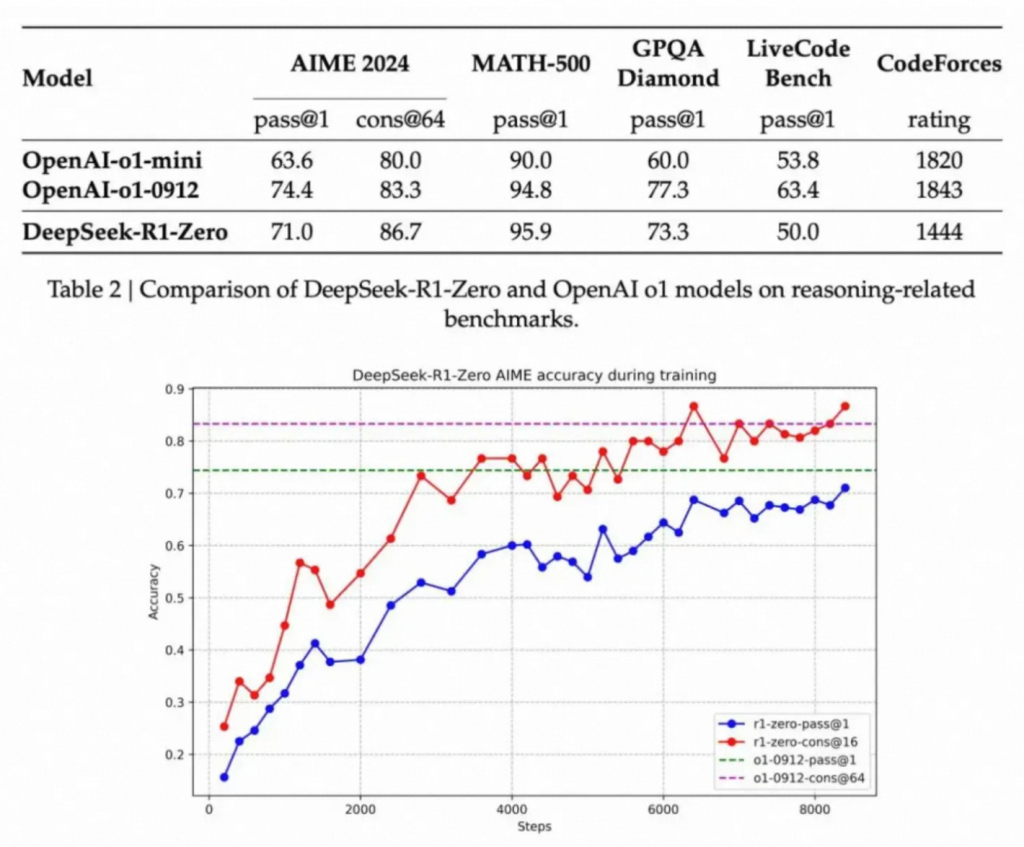
并且观察到了明显的“进化”现象,随着训练步数的增加,输出平均长度也在增加。意味着LLM似乎自己已经潜移默化学会了进行更多的思考和推理,达到更好的效果
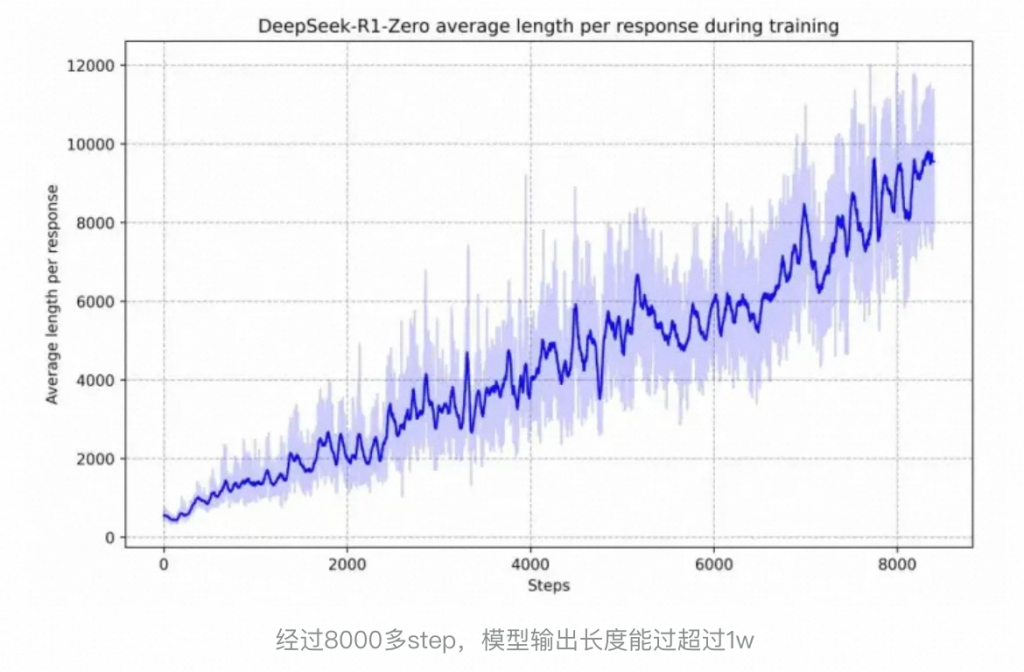
但是Zero 也会面临一些典型问题,如可读性差、语言混乱:可能在中英文甚至其他语言之间来回切换,或是输出大量中间符号、不完整的数学公式;
因此在Zero的基础上又开发了DeepSeek-R1。
DeepSeek-R1
DeepSeek-R1-Zero已经证明了,完全不进行SFT, 直接RL就能显著提升LLM的推理能力;但是同时输出的可读性、混合语言输出问题还是很难。DeepSeek-R1采用如下4个阶段,通过引入SFT流程,让模型输出PATTERN更加可控。
a. 少量数据冷启动
采用一定的手段收集少量高质量数据:比如对于长CoT数据,使用few-shot,直接提示DeepSeek-R1-Zero通过反思和验证生成详细答案,然后通过人工注释者的后处理来细化结果。
总共收集了数千个样本,相比完全不用SFT,收集的样本进行SFT,可以显著增强可读性;同时后续的实验也证明了通过少量数据冷启动也能进一步提升推理能力。
b. 对推理场景进行RL
然后对数学、代码等推理场景进行RL。这里没啥好说的,和DeepSeek-R1-Zero一样的方式。针对DeepSeek-R1-Zero输出中语言混合的情况,额外增加一个奖励:语言一致性奖励,统计输出中目标语言的占比作为奖励信号。将原始的准确性奖励与语言一致性奖励求和作为最终奖励,进行过程反馈。
c. 拒绝采样和SFT
这一步主要是为了提升模型的通用能力,通过构建两部分的数据进行SFT来实现。
1.推理数据:采用拒绝采样的方式从前一阶段得到的模型生成推理过程,同时额外引入一些无法用规则进行奖励的数据(这部分数据使用DeepSeek-V3通过LLM-as-judge的方式进行奖励,比较GroudTruth与实际输出)。同时,过滤掉了包含混合语言、长段落、代码块的CoT数据。总计有60w样本。
2.非推理数据:使用DeepSeek-V3生成、使用DeepSeek-V3的SFT数据,共计20w推理无关的样本。
这一阶段总共生成了80w样本,用DeepSeek-V3-Base 进行了2个epoch的SFT。
d. 适配所有场景的RL阶段
最后为了同时平衡推理能力和通用能力,又进行了一次RL。对于不同的数据类型,采用不同的prompt和奖励。
对于推理数据,使用DeepSeek-R1-Zero中的方法,该方法在数学、编程和逻辑推理领域使用基于规则的奖励指导学习过程。对于通用数据,使用通用的RM来进行奖励。基本复用DeepSeek-V3的方式。对于有用性,专注于评估最终的summary,确保评估对用户的实用性和相关性,同时尽量减少对底层推理过程的干扰。对于无害性,评估模型的整个响应,包括推理过程和总结,以识别和减轻生成过程中可能出现的任何潜在风险、偏见或有害内容。
最终,奖励信号和多样化数据分布的整合使得最终的模型既能保持推理能力,又能满足有用性和无害性,取得比较好的用户体验。
如此形成了 base -> SFT -> RL ->(拒绝采样+新 SFT)-> RL 的多阶段训练pipeline。
经过最终收敛后,R1 的数个评测指标(如 AIME、MATH、LiveCodeBench、甚至一些长文本写作与问答评测)均达到了或超过了主流商用闭源大模型的水准。报告中提到,R1 的数值表现已“接近或达到 OpenAI-o1-1217”水平。

读者友好的输出与常见问题
相比 Zero,R1 的输出可读性、语言一致性显著提升,并且对安全与对齐的关注度也更高。另一方面,R1 仍然存在一些已知不足:
- 对少数语言可能仍会混用英文:R1 的训练重点是中文与英文,遇到法语、德语等场景时,依然可能出现意外的混合输出;
- 对上下文提示敏感:在一些测试中发现,Few-shot 提示反而会降低 R1 的性能,表现不及直接的 Zero-shot 提示;
- 软件工程能力仍不算最佳:虽然在算法题上表现强劲,但在大型软件工程任务(例如多文件、多模块依赖)方面,强化学习的代价昂贵,依赖大量且实时的编译测试;目前相对通用型微调与拒绝采样的规模还不足以大幅提升工程类编程任务的表现。
其他结论
1. 对于小模型来说,小模型蒸馏>强化?
DeepSeek的另一个重要结论是,对于小模型(如 1.5B、7B、32B 参数规模)来说,从大模型蒸馏而来的推理能力通常优于直接进行大规模 RL。
- 在报告中,作者尝试对小模型(如 Qwen-32B-Base)进行大规模强化学习,发现效果甚至不如直接拿 DeepSeek-R1 当教师模型来生成数据,再做监督微调;
- 原因可能在于,小模型本身的初始能力或表示能力有限,无法在 RL 过程里探索并学到高水平的推理框架,而蒸馏则可以直接“迁移”大型模型的推理路径与知识点。
不过这一点我们的工作以及其他的一些小模型蒸馏工作发现,大模型蒸馏小模型实际上存在很多问题,比如更容易non-stop等。
总体看,蒸馏虽然容易在某个细分任务上进行过拟合而提升指标,但是往往很容易矫枉过正丧失其他例如指令组训等基本能力。所以这个结论我们认为还为时尚早。
2. DeepSeek-R1在长文本、可控生成上也获得了很强的提升
DeepSeek-R1在AllacaEval2.0与ArenaHard的长度控制上胜率分别为87.6%与92.3%。同时在长文本理解等方面性能也显著超过DeepSeek-V3。但是没有具体提完整的指令遵循能力提升,考虑到R1的few-shot能力比较差,很有可能是有一点掉点的。
从这点上来说,我们的实验也发现了,相较于常规的Instruct版本,我们的模型可以获得更好地指令遵循能力,在长度控制、format控制上,具有更好的效果。相较baseline有10个点左右的提升。似乎这是长CoT模型的一个舒适区,有更长的空间来对长度等问题进行思考。
3. 为什么不使用(P)RM?
1. 在一般推理过程中明确定义细粒度的步骤比较困难。
2. 对步骤打标难以扩展,采用自动标注难以获得较高准确率,手动标注又难以规模化应用。
3. 引入基于模型的(P)RM,不可避免地会遇到reward hacking, 重新训练奖励模型需要额外的训练资源,并使整个训练流程复杂化。
包括mcts也进行了一定的研究,主要问题为搜索空间过大,容易陷入局部最优解。
4. 未来方向
- 通用能力:虽然R1出圈的原因是很强的泛化能力,但是相比仍然不及DeepSeekV3。
- 语言混合:DeepSeek-R1目前针对中文和英文进行了优化,但是在处理其他语言以及语言遵循方面还是会有问题。
- PE:DeepSeek-R1对Prompt非常敏感。few-shot提示会持续降低其性能。
- 软件工程任务:由于长时间的评估会影响RL过程的效率,大规模RL尚未在软件工程任务中广泛应用。
R1复现工作
Open-R1
DeepSeek-R1模型权重是开放的,但用于训练的数据集和代码没有提供。
Open-R1的目标是填补这一空白,以便整个研究和行业社区都可以利用这些资源构建类似或更好的模型。以下是复现行动计划:
- Step 1: 复现通过R1蒸馏Qwen等小模型。
- Step 2: 复现通过纯强化学习训练R1-Zero的过程,包括如何生成推理数据集。
- Step 3: 复现训练R1的完整pipeline,包括2阶段SFT、2阶段RL。
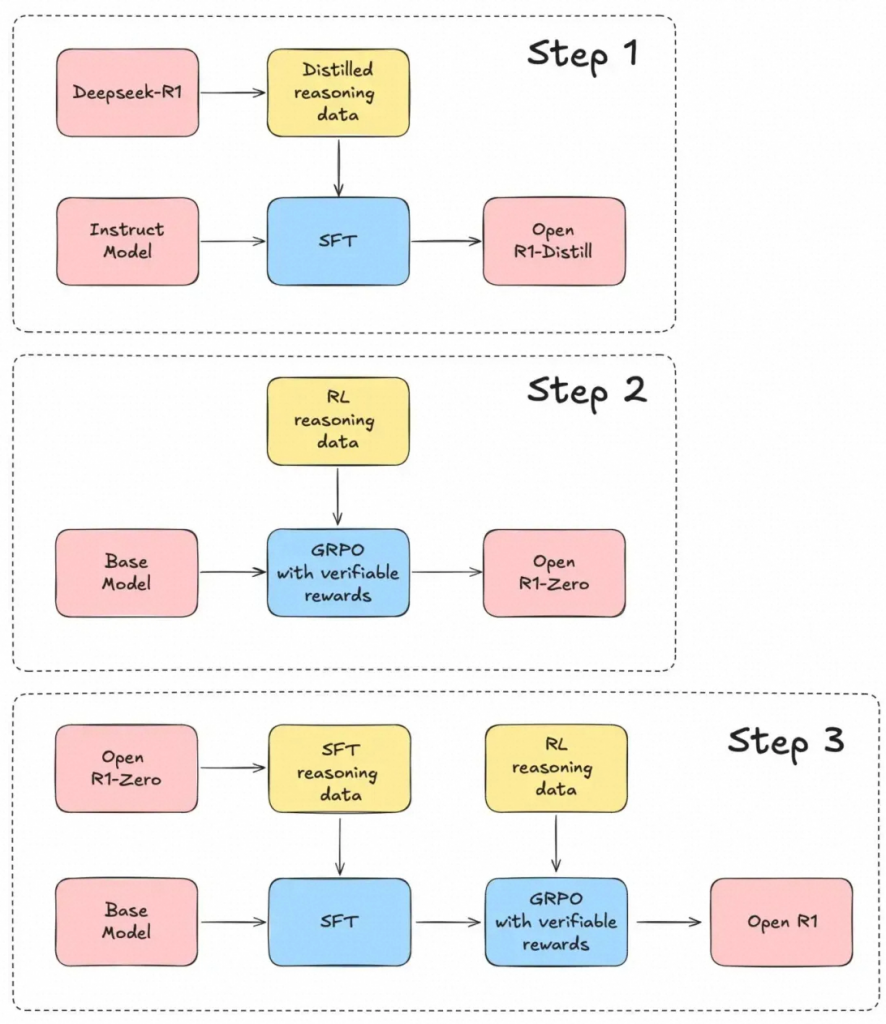
step1:通过DeepSeek-R1蒸馏的数据训练
使用 DeepSeek-R1 的 蒸馏数据创建了 Bespoke-Stratos-17k(https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k)——一个包含问题、推理轨迹和答案的推理数据集。
该数据集包含:
- 5,000 条来自 APPs 和 TACO 的编程数据;
- 10,000 条来自 NuminaMATH 数据集的 AIME、MATH 和 Olympiads 子集的数学数据;
- 1,000 条来自 STILL-2 的科学和谜题数据。
生成过程:
- 高效数据生成:调用 DeepSeek-R1,使用 1.5 小时生成高质量推理数据集,成本控制在 800 美元。
- 改进拒绝采样:引入 Ray 集群加速代码验证,作者后面计划直接集成代码执行验证器。
- 提升数学解题精度:通过 gpt-4o-mini,过滤错误的数学解决方案,显著提高了正确数学解决方案的保留率(从 25% 提升至 73%)。
step2:通过推理数据集+GRPO训练R1-Zero
此处未完整复现推理数据集的构造全流程,这个可能是R1-Zero最重要的点。
Open-R1直接采用了推理数据集:AI-MO/NuminaMath-TIR,共72540条数据。
按照R1-Zero论文的描述,problem字段是提供给模型的输入,通过规则化的RL奖励来引导模型进行思维链(CoT)慢思考。规则化的RL奖励包括答案的准确性和格式的准确性。
step3:通过多阶段pipeline训练R1
Todo
simpleRL-Reason 港科大
Motivation
当下推理模型的痛点:
- 数据成本:主流方案依赖数百万标注数据,如PRIME需7.3M样本;
- 架构复杂:需搭配奖励模型、蒙特卡罗树搜索(MCTS)等,训练成本高;
- 泛化不足:传统监督微调(SFT)在跨难度任务上表现乏力。
核心问题:能否仅用极少量数据(如8K样本)和简单RL框架,在小模型(7B参数)上实现复杂推理能力的涌现,实现 “aha moment” ?
该研究给出了肯定答案——无需SFT、无需奖励模型,仅通过规则奖励函数,Qwen2.5-Math-7B在AIME、AMC等数学竞赛级任务中超越传统方法,甚至逼近50倍数据量的基线模型。
Solution
核心思路:通过规则化奖励函数引导模型自主探索推理路径,激发长思维链(CoT)与自我反思(Self-Reflection)。
为此,作者提出SimpleRL方案,核心仅两步:
- 规则化奖励机制:
- 格式约束:强制模型输出结构化答案,抑制冗余内容(如代码片段);
- 稀疏奖励:不干预中间推理步骤,倒逼模型自主探索有效CoT(思维链)。
- ✅ 答案格式正确且内容正确 → +1奖励
- ❌ 答案错误 → -0.5惩罚
- 🚫 无答案 → -1惩罚 无需复杂奖励模型,直接通过规则引导模型行为。
- PPO算法训练:
依然研究对比了两种训练模式:
- SimpleRL-Zero:直接从基座模型启动RL,无任何预热,意味着长CoT的能力要靠RL过程中自己进化;
- SimpleRL:先用8K样本进行长CoT冷启动(长CoT是从32B大模型QwQ中蒸馏),再进行RL微调。差异在于一开始就让模型从长CoT中拥有self-reflection的能力,然后再通过RL阶段学习更快更好。
自省能力涌现:训练约40步后,模型开始生成自我纠错过程(如“这一步可能有误,重新计算…”),与人类解题时的“顿悟”高度相似;这正是DeepSeek-R1论文中提到的“Aha Moment”:

长度自适应:初期模型因冗余代码导致输出过长(可能与模型的原始训练数据分布有关),RL快速优化格式后,逐渐剔除了这种模式,使模型学会用正常语言进行推理,推理长度随任务难度自然扩展。
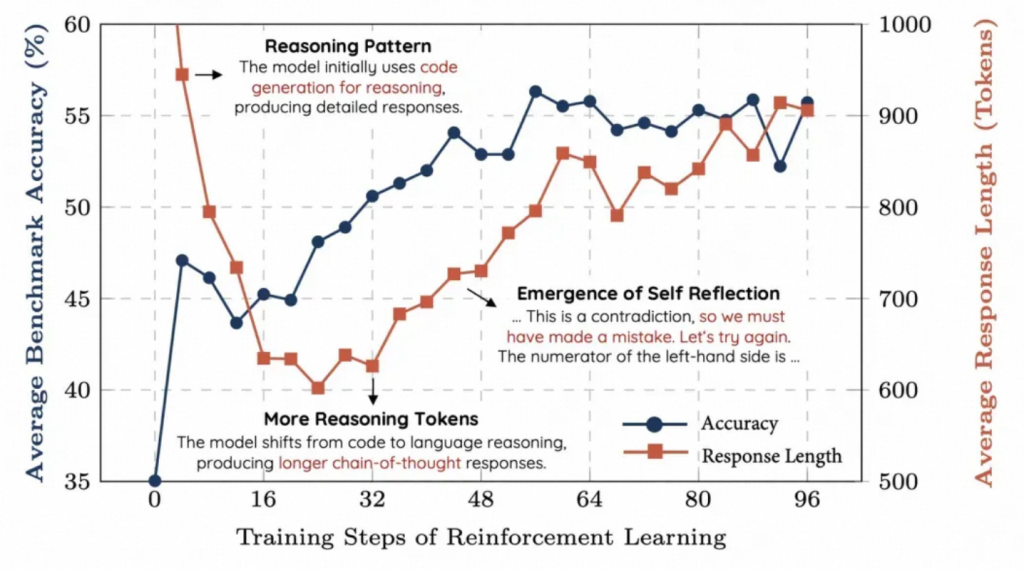
Evaluation
在实验中,作者以 Qwen2.5-Math-7B-Base 模型为起点,在多个具有挑战性的数学推理基准测试上评估其性能,包括 AIME2024、AMC23、GSM8K、MATH-500、Minerva Math 和 OlympiadBench。训练数据使用了 MATH 训练数据集中难度为 3-5 级别的约 8000 个问题。实验分为以下两种设置,分别对应 DeepSeek-R1-Zero 和 DeepSeek-R1:
- SimpleRL-Zero:直接从基础模型开始进行强化学习,不进行监督微调(SFT)。仅使用 8K MATH(问题,答案)对。
- SimpleRL:首先进行长推理链(long-cot)的监督微调作为预热。SFT 数据是 8K MATH 查询及其从 QwQ-32B-Preview 蒸馏得到的回答。然后,使用相同的 8K MATH 示例进行强化学习。这种预热的潜在好处在于,模型从一开始就处于长推理链模式,并且已经具备自我反思能力,这使得模型在后续的RL阶段能够更快、更好地学习。这个过程实际上和deepSeek-R1的流程有差异,R1采用了2个SFT和2个RL流程。
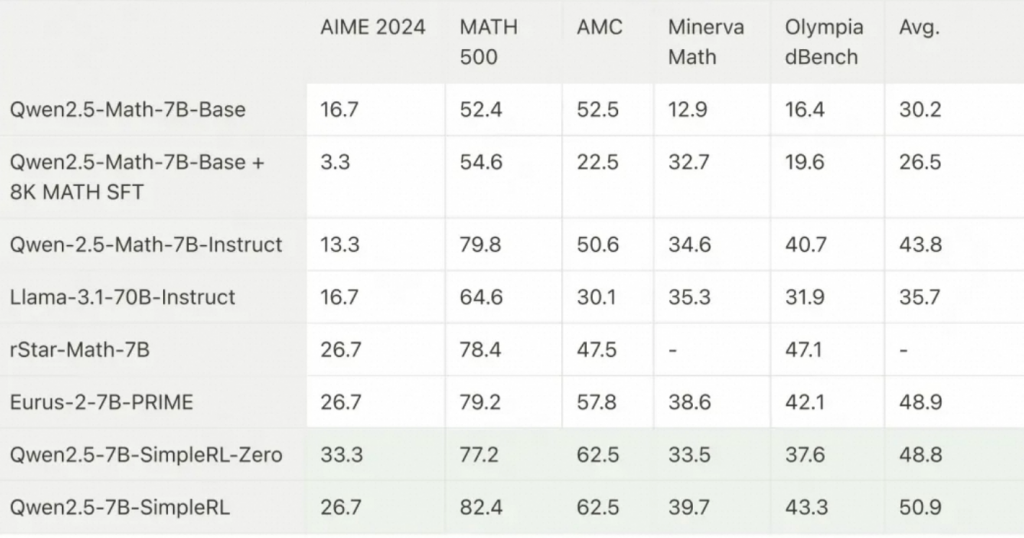
可以看到 Qwen-2.5-Math-7B-base +SFT的效果不如Qwen-2.5-Math-7B-base,结合近期大量研究,SFT可能在很多情况下起的是指令遵循作用,对于模型的推理能力不一定有太大作用。
除此之外,作者还对比了Qwen2.5-Math-7B-Base + 8K QwQ蒸馏 vs Qwen2.5-7B-SimpleRL。
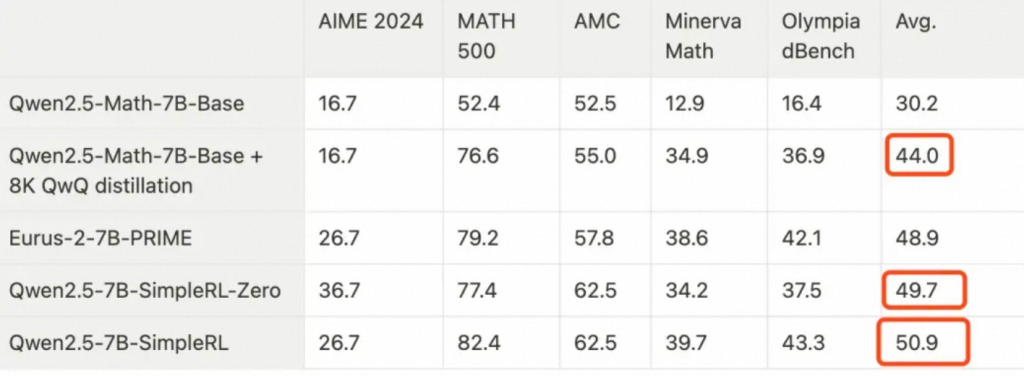
Qwen2.5-7B-SimpleRL 相比于 Qwen2.5-Math-7B-Base + 8K QwQ蒸馏,平均绝对提升了6.9%。似乎还可以,但是相比于Zero其实仅提升了1.2%。
作者对QwQ蒸馏阶段没有比zero训练方法产生更大的提升感到有些意外,因为QwQ是一个32B的相对更强大的长推理链教师模型。认为这种现象可能是因为QwQ蒸馏出的推理模式并不完全适合小策略模型,或者超出了小策略模型的容量。因此,模型在RL训练过程中逐渐摒弃了这种模式,并自行发展出新的长推理模式。
作者开源了Zero的代码,采用了OpenRLHF框架,ray和vllm加速训练。详见:https://github.com/hkust-nlp/simpleRL-reason。
我们实验的一些讨论
- format和sft一样,对于base->rl也是一个极其简单的任务。
- 对于难的任务,模型更容易产生reward hacking,对于format过分关注,而不进行有效推理。
- 如果在reward设计中添加了format reward等非outcome reward,对性能是有损伤的。
- 整体RL稳定性极其依赖于reward 设计或reward model稳定性。
对于输出长度的分析
试图回答几个问题
- RL是否能显著增加模型的输出长度?
- 输出长度和准确率是否有相关性?
- 是否有format检查是否影响模型效果?
先说简单任务(以下实验除非特殊说明,是format + match的reward):
如下图可以看到format(绿色)很快就上涨到接近1的水平,验证了和sft类似,format其实是很容易学到的。
其次可以发现,整体上,训练集、验证集以及输出长度随着训练step的增加而增加。似乎说明了输出长度和acc之间的关系。

那真的就是acc和长度成正比吗?但是随着难度的增加,发现走势出现了一点偏差。走势并不像简单任务一样完美走势。

出现了明显的reward hacking——反正都做不对,think里有没有内容就不重要了。
同时,目前大家的一些复现工作以及和相关复现同学的聊天看,(在不给长度reward的情况下)整体稳定长度增长都是一个比较困难的问题(或者说是一个很敏感问题)。例如对于困难问题就会出现明显的reward hacking导致模型整体能力坍塌。同时还有一些长度天花板问题(如下图,模型长度在700左右走平,不会持续增长)。
好消息是目前我们对于通过一些训练trick,在极难任务上也已经做到了2200多token的输出,acc也是稳步上涨。受限于数据量,我们并没有继续运行以观察到长度与性能上限。
整体而言,如何引导模型输出持续变长是一个较大的挑战。因为在初期模型还不能有效完成PATTERN对齐时,reward趋势一定是让模型输出更短的(因为要输出终止符而不是Next Token Predict),这就很容易由于rule-based reward的稀疏性导致模型陷入局部最优解。
因此例如DeepSeek的先进行sft warmup在进行强化就是一个较为可行的方案,猜测也是一个tech report中没有提到的一个动机。但是也不得不承认,单就引导模型变长这一单一行为看,能够解决的方案有很多。
同时。我们还观察到,对于一些任务而言,并不是输出越长越好,例如下图实验,训练集和测试集的reward持续增加,但是文本输出长度存在较大的波动。推测可能是有一些行为激发后慢慢进行收敛导致的。不过目前还是猜测,还需要进一步的分析case获得更好地认知。

上面所有的实验基本都发生了随着RL step的进行,模型response length在持续整张,那是否能证明RL真的能让模型输出变长呢?还是否定答案——至少不全是。例如如下例子,train/test sert的reward在持续增长,但是输出长度在显著降低。模型没有进行良好的推理,退化成常规的强化学习,直接对结果进行优化,从而出现了推理长度变低,但是性能在上涨的原因。
需要格外一提,下图实验并没有发生reward hacking。因此RL with reasoning = response length变长?这个等号似乎也是画不上的。

而对于format的消融实验发现,添加format rule-based 会损伤模型性能。和上文提到的R1 添加语言 reward会掉(一点)性能类似。说明和outcome无关的一些reward在一定程度上是会影响模型性能的。不过影响范围有限,对于一些较为重要的特征依然有使用必要。

case show
我们也观测到了R1论文中提到的语言混乱问题。好玩的是思路/语义是连贯的。只不过某个词被替换成了另一个语种。

还在极难任务中发现了自我修正的case。前面分析了很多,最后分析出了矛盾点,自我进行改正并输出答案,整体模型输出超过了3000 token。

在翻译业务中,也发现了模型自发的开始思考语言本地化与词汇推敲。例如下图说需要思考中文和西班牙语之间的语法、词汇、文化等差异。这对一些本地化翻译和业务翻译提供了一些有趣的优化方向。

难点
- 如DeepSeek使用了8000步强化,实际上一些复现表示在几百小几千step时就会出现瓶颈。如何做到这么多的step的稳定?
- rule-based reward由于其稀疏性导致模型极其脆弱,如何设计一个良好的reward系统?对于不同的任务是否要设计不同的reward系统?
- 如果使用reward model(无论是reward model还是其他llm as a judge),如何降低reward hacking的影响?
- R1的一大亮点是泛化性很好,跨领域泛化如何保证?
0 条评论