本文主要介绍我们的iclr 2026投稿。
研究动机
今年来随着OpenAI o1、o3、DeepSeek R1等模型的出现,推理模型通过预先生成一段长思维链(CoT)确实可以显著提升模型的推理性能,在各个复杂推理任务上都有显著提升。
但是这也带来了长文本的显著压力。由于现有模型的self-attention的复杂度为  ,是二次复杂度,随着文本长度的增加,计算成本显著增加,同时kv cache的压力也随着增加。这限制了reasoning模型在实际应用中的效率。
,是二次复杂度,随着文本长度的增加,计算成本显著增加,同时kv cache的压力也随着增加。这限制了reasoning模型在实际应用中的效率。
目前大家对推理效率的提升有两种方案:
- 显示缩短推理长度:通过prompt、sft、RL等方式,让模型生成更短的推理序列,从而提高推理效率。然而这在一定程度是损失了reasoning的初衷,导致模型一定程度上性能的下降。
- 隐式缩短推理长度:这类方法通过使用一个隐向量来表达多个token,从而将长reasoning压缩为更短的推理序列。(例如早期的Qwen3,在enable_thinking=False是依然使用<think><\think>来隐掉推理内容)。然而这种模式与预训练和微调的训练范式存在较大gap。这种gap需要较多的训练资源,同时还容易产生灾难性遗忘。
为了解决上述问题,我们主要贡献如下:
- 提出了一个新的高效推理框架,在这个框架中,我们将模型的推理过程 建模为 状态转移过程。模型借助当前状态高效的生成后续的token(而不依靠之前的token)。通过这种方式:
- 我们可以将self-attention的平方复杂度降到线性复杂度,显著提高了模型的推理效率。
- 我们无需缩短推理长度和推理模式,对原模型不进行训练,完全是一个热插拔件。最大可能的保留了模型的推理能力。
- 此外,我们还提出了一个基于全局动量的推理策略。通过维护一个全局推理行进方向,动态修正模型的推理过程,能够有效的避免模型被某个局部错误引导,以此来提高模型对噪音的鲁棒性,进一步提高了模型的推理能力。
我们的方法preview
我们的整体思路是将模型的token by token的推理过程建模成状态转移过程。
现有模型的token-base reasoning时,是以自回归的方式来生成长序列中的每一个token,模型的生成速度会以平方速度下降。同时,虽然有着kv cache技术,但是随着生成序列长度的增加,kv cache内存压力也会显著增加。
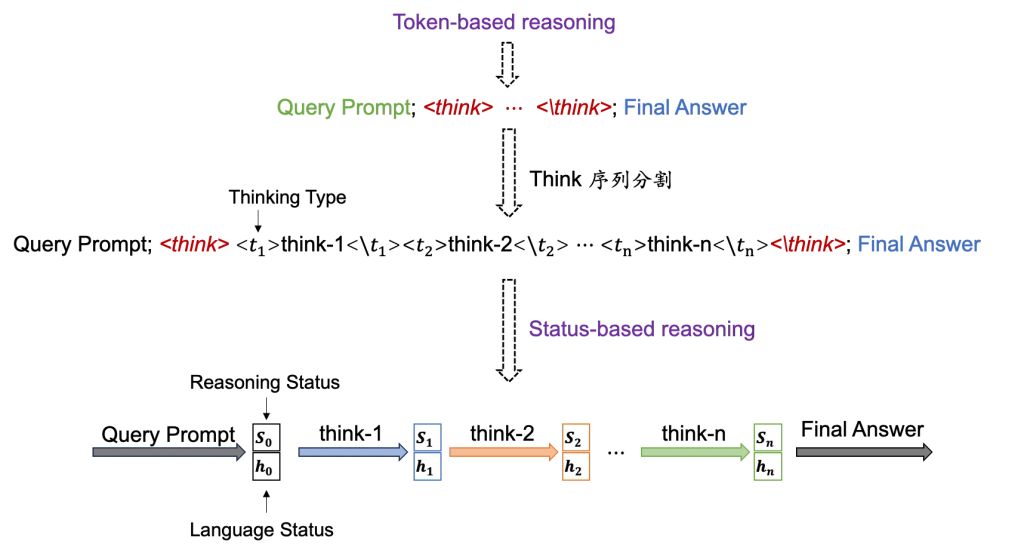
我们将token序列抽象成状态,推理实际上就是在不同状态之间的转移。
具体来说,我们将推理序列通过关键词分割成相对独立的think段,每一个think段对应一个thinking type。这些type是抽象的通过聚类而来。
当模型推理完成一个thinking type(例如think-1)时,会获得一个新的状态 ,随后模型使用和user input(prompt)完成下一段推理(think-2),而不需要考虑已经完成的think-1中的序列。
,随后模型使用和user input(prompt)完成下一段推理(think-2),而不需要考虑已经完成的think-1中的序列。
因此,我们的方法就能够在模型每次生成think时,只关注固定的prompt内容,从而将self-attention平方复杂度降至线性复杂度。
但是这里一个比较重要的问题是如何得到我们的状态 是可获得的并且是正确的。
是可获得的并且是正确的。
Linear attention
线性attention天然具备压缩状态的能力。
我们首先回顾一下标准的self-attention公式
\mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^{\sf T}}{\sqrt{d}}\right)V因为注意力的本质上就是加权平均,现在,我们不再使用softmax作为激活函数,而是使用 代替,
代替,
V_i= \frac{\sum_{j=1}^N sim(Q_i,K_j)V_j}{sim(Q_i,K_j)}
其中,分母是总和用来归一化。其中可以是任何非负函数:
其实这里非负也只是工程要求:你总不能要求一个token对总体的贡献是负数的,这很容易导致归一化出错。
基于这样的条件下,我们继续给定一个内核函数 ,那么有:
,那么有:
V_i = \frac{\sum_{j=1}^N \phi(Q_i)\phi(K_j)^TV_j}{\sum_{j=1}^N \phi(Q_i)\phi(K_j)^T}
现在,就是一个标准的矩阵乘法了,我们利用矩阵的乘法结合律得到:
V_i = \frac{\phi(Q_i)\sum_{j=1}^N \phi(K_j)^TV_j}{\phi(Q_i)\sum_{j=1}^N \phi(K_j)^T}
进一步简化,将分母这个归一化项去掉,我们得到:
\mathrm{Attention}(Q,K,V)= (\phi(Q)\phi(K)^T)V = \phi(Q)(\phi(K^T)V)这是,复杂度就从 降为了
降为了 。达到了线性复杂度,那就是最终的O矩阵:
。达到了线性复杂度,那就是最终的O矩阵:
o_t = q_t St
\\
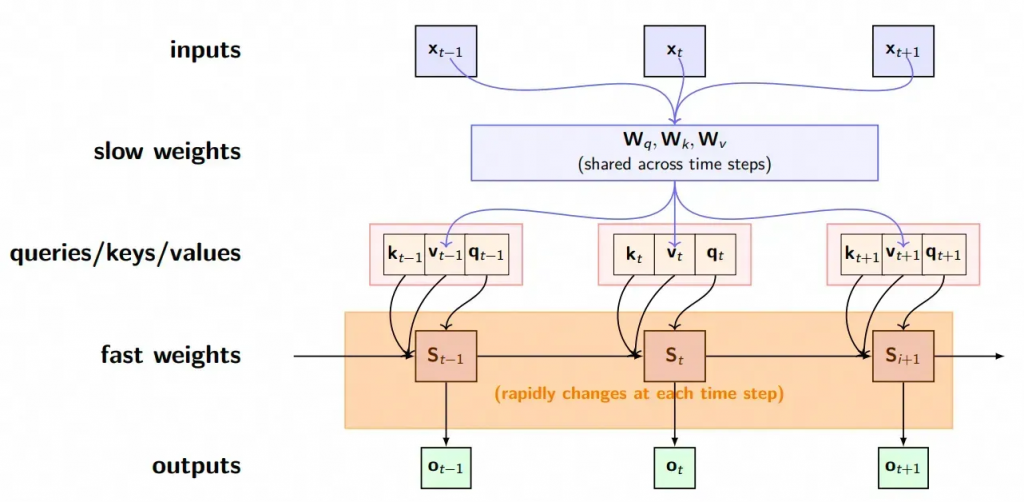
S_t = \sum_{i=1}^t k_i^Tv_i = S_{t-1} + k_t^Tv_t到这里,我们就已经观察到了Linear-attention使用了状态转移矩阵S记录了之前的上下文信息,使得每一当前步t,不再依赖于对之前token进行完整的attention计算,大大降低了存储的复杂度。
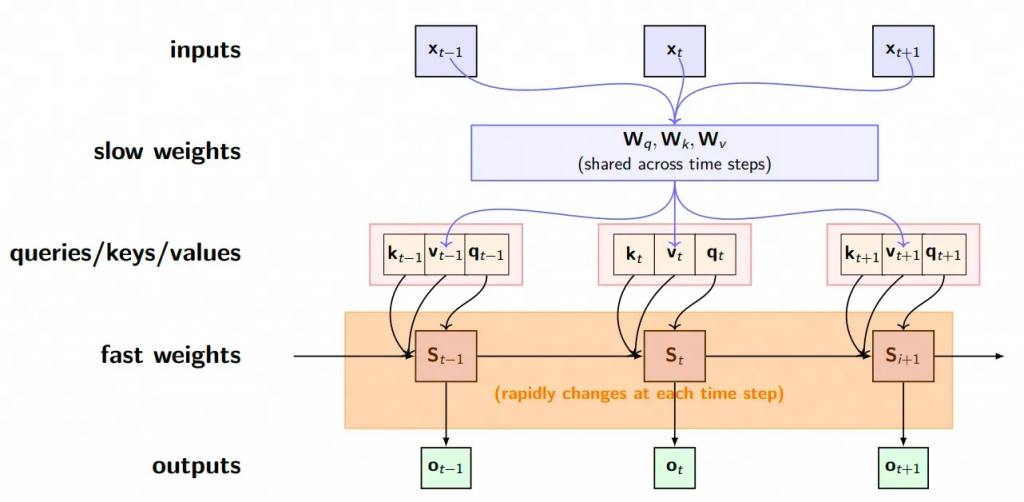
同时我们还发现,对于传统attention的,其实所有的Q、K、V、O矩阵都是共用的,只不过修改了核函数,两者具备天然的契合性。
Minimax Lightning Attention
既然Linear attention和self-attention具备天然的契合性,并且具备了线性复杂度,为什么主流依然是self-attention呢?
主要原因可能有两点:
- Linear Attention的核函数现在现阶段主要依靠例如relu、silu这类简单的非负核函数。相比softmax,他们处理Attention数值的能力更差,例如softmax很容易出现0.8这类高Attention值,但是relu、silu这类核函数很难出现极高Attention值。对整个Attention的性能有一定损失。
- 由于单项注意力系统的累加求和操作问题。如下公式,在上面提到过,在单向注意力时,实际上由于每个
 使用的累加项是不一样的,因此没有办法直接分离。
使用的累加项是不一样的,因此没有办法直接分离。
V_i = \frac{\phi(Q_i)\sum_{j=1}^N \phi(K_j)^TV_j}{\phi(Q_i)\sum_{j=1}^N \phi(K_j)^T}
\Longrightarrow V_i = \frac{\phi(Q_i)\sum_{j=1}^i \phi(K_j)^TV_j}{\phi(Q_i)\sum_{j=1}^i \phi(K_j)^T}这就必须使用for循环逐个计算,没办法使用高性能的矩阵计算,严重影响了计算效率。可以说是低时间复杂度但是高时间。
对于第二个原因,minimax lightning attention-2给出了一个稍微好一点的优化方向。借鉴了flash-attention和kv cache,使用了block的概念,对每一个block内进行for运算,同时缓存结果用于后续的计算。
\begin{align}
& o_1 = q_1(k_1^{\mathsf{T}}v_1) \\[10pt]
& o_2 = q_2(k_1^{\mathsf{T}}v_1+k_2^{\mathsf{T}}v_2) \\[10pt]
& o_3 = q_3(k_1^{\mathsf{T}}v_1+k_2^{\mathsf{T}}v_2+k_3^{\mathsf{T}}v_3) \\[10pt]
& o_4 = q_4(k_1^{\mathsf{T}}v_1+k_2^{\mathsf{T}}v_2+k_3^{\mathsf{T}}v_3+k_4^{\mathsf{T}}v_5)
\end{align}通过将计算切分成块内(intra block)和块间(inter block),来缓解这一问题。我们后续使用的就是这个Minimax Lightning Attention。
我们的方法
我们设置了一个mixed attention层,这个层实际上包含了两种attention结构。
我们同时计算Linear-attention和self-attention,其中self-attention只能关注到当前块(thinking_type)内的token信息以及输入的prompt。而全局信息全部从Linear-attention中获得。同时使用门控单元来控制二者的比例,加权求和后作为最终的输出。
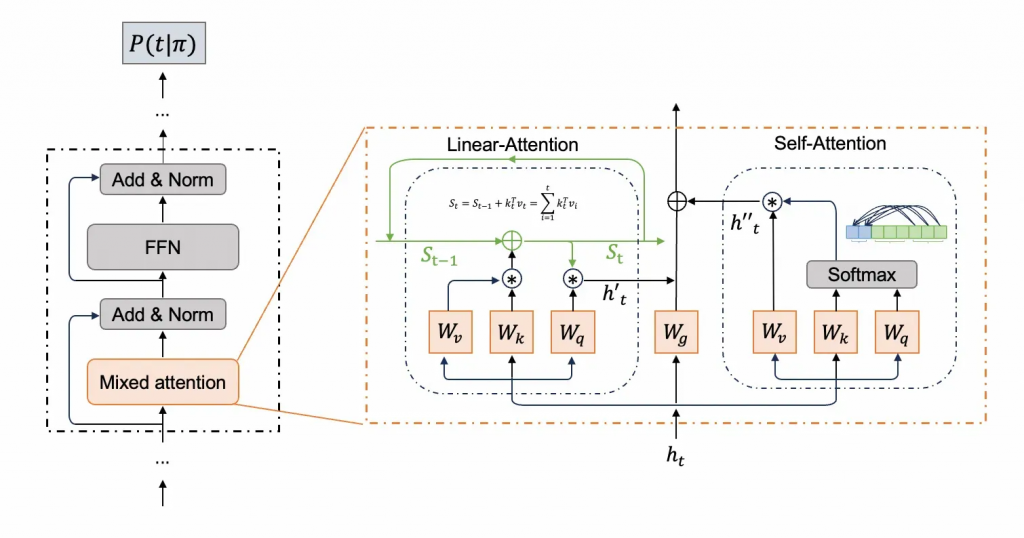
我们希望的是:对于当前thinking_type的推理,一开始主要使用Linear-attention的输出,因为它代表着对过往推理状态的总结,而随着块内推理的进行,越来越倾向使用self-attention,因为它代表着对当前块内推理的聚焦。
每一个新的token生成后,都会重新更新Linear-Attention的状态,以维护最新的全局状态。
我们一共为我们的模型设计了三种loss和两个训练阶段。
其中所有阶段都不会对原模型进行任何训练。仅对我们添加的参数进行训练。也就是我们的模型是一个不破坏原模型的热插拔件。
第一阶段的主要目的是对mixed attention层的预训练,我们添加了一个Linear-attention模块,同时添加了词表(thinking_tpye),总计大概60M的参数。同时修改了mixed attention层的mask矩阵,使thinking_type内只能attention到块内,使用一个KL loss来恢复整个attention输出的正确性。
这一阶段的目的主要是由于有冷启的参数,做一点预训练使其性能能够初步对齐。
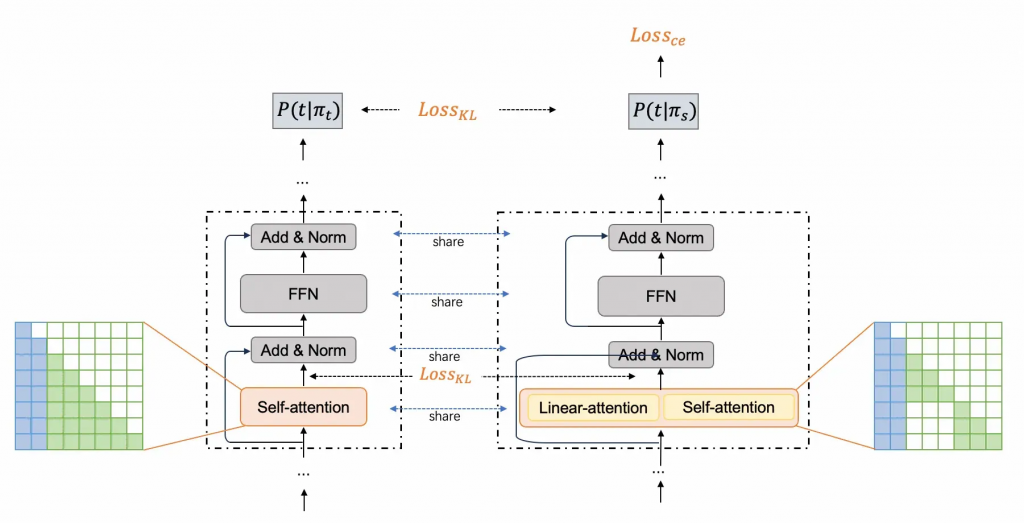
第二阶段我们就进行了更细致的微调。我们使用了2个loss。CE loss和KL loss。其中CE loss就是正常的sft loss。但是我们发现训练效果不佳,随后我们为其添加了KL loss。动机主要是考虑到reasoning模型本身就是高熵模型,需要保留较多的多样性以支持探索,因此直接使用CE loss可能会破坏模型的探索性,使其探索到训练数据上。
因此,我们添加了KL loss,它通过将正确标签去掉(削峰),根据其余位置logits的熵来动态调整目标。例如对于尖锐的分布就加大温度,太均匀的分布就减小温度,来学习全token的分布。
需要注意,我们的所有参数(包括self-attention)都是由teacher 模型共享而来,并且在训练中freeze,所有阶段的训练参数就只有Linear attention的相关参数以及我们为thinking type添加的embedding和lm_head相关参数。
推理
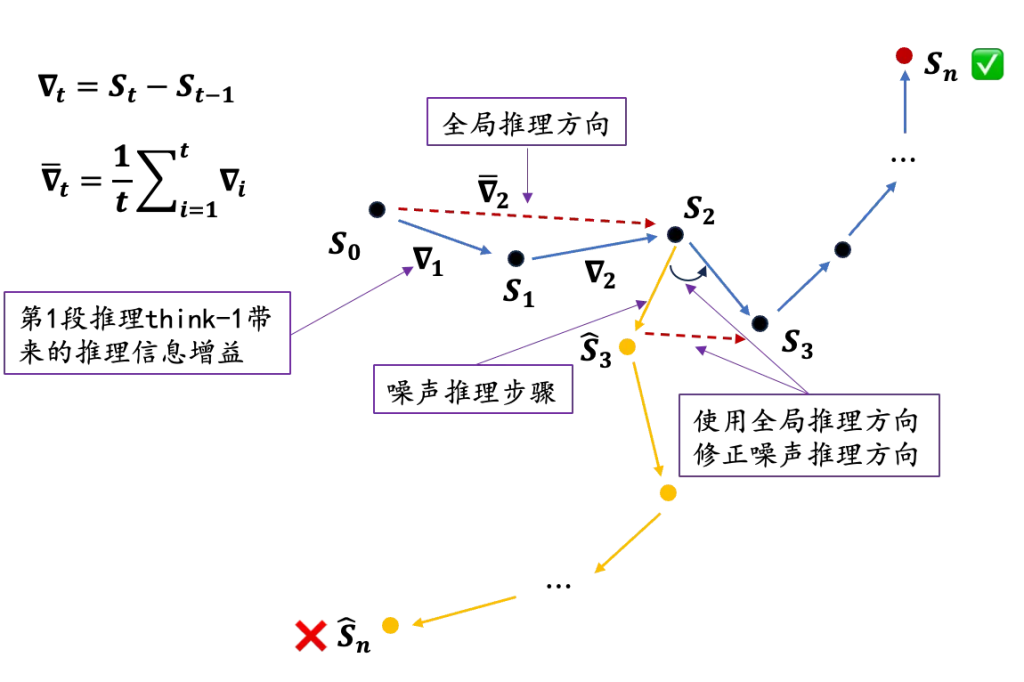
思考上面Linear attention的图,我们可以很容易的发现,其中S的计算和使用逻辑,特别像梯度下降的过程:
当我们当前状态计算了一个方向 时,实际更新方向可能收之前状态的影响比较大,因此,我们可以将这一特性沿用到推理过程中来,类似于添加一个优化器,让每一步的推理都受到历史状态的影响,防止因为某一步的推理错误导致的全局方向出现偏差。
时,实际更新方向可能收之前状态的影响比较大,因此,我们可以将这一特性沿用到推理过程中来,类似于添加一个优化器,让每一步的推理都受到历史状态的影响,防止因为某一步的推理错误导致的全局方向出现偏差。

具体来说, 表示第t段推理think带来的梯度下降总量(即推理方向),也可以理解为think-t带来的推理信息增益。而全局推理方向
表示第t段推理think带来的梯度下降总量(即推理方向),也可以理解为think-t带来的推理信息增益。而全局推理方向 :用于记录到当前推理步t为止,模型整体的推理方向。
:用于记录到当前推理步t为止,模型整体的推理方向。
那么当遇到噪音推理(think-3)时,当前步骤的推理方向( )会严重偏离全局的推理方向(
)会严重偏离全局的推理方向( ),因此我使用全局推理方向来进一步修正局部推理方向,从而提高模型对推理噪声的鲁棒性。
),因此我使用全局推理方向来进一步修正局部推理方向,从而提高模型对推理噪声的鲁棒性。
效果
我们的模型在效果上相比baseline有了显著提升。由于时间限制目前只测了1.5B,后续会测试7B和14B。
| MATH | AIME24 | AIME25 | AMC23 | gsm8k | GPQA_D | AVG | |
| DSQ2.5-1.5B | 78.87 | 20.00 | 16.67 | 62.50 | 20.70 | 39.75 | |
| Ours | 81.21 | 26.67 | 23.33 | 67.50 | 24.24 | 44.59 |
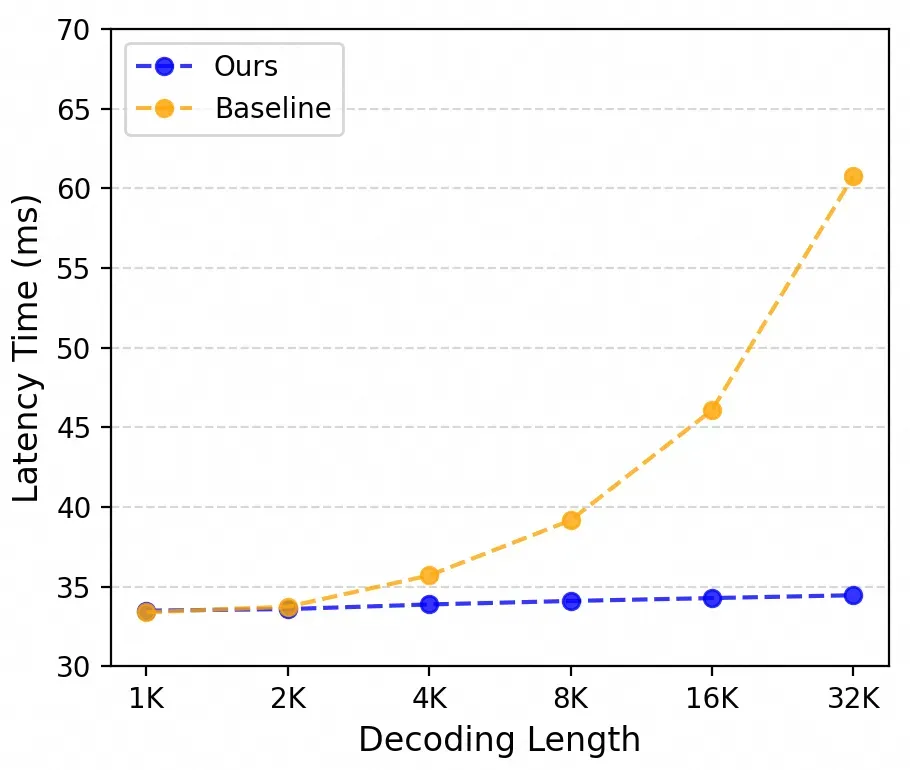
在取得性能提升的同时,我们的模型在推理速度上也获得了很大的提升。在32K情况下,我们的token生成效率在baseline使用了flash-attention加速的情况下依然提升了40%。同时得益于更低的kv cache使用,我们的显存的利用也得到了很大的降低
不足与未来工作
不足:
- 对现有推理框架的适配不足,后续在线学习可能对采样效率有一定影响。
- 目前切分thinking_type采用的是基于规则的关键词裁剪,后续可能会有更优秀的方案。
未来工作:
- 我们的推理方案证明了线性attention状态转移的有效性。后续可以用例如信息增益这类方式来构造PRM数据。
- 跳步推理。之前我们预计做可以使用linear attention直接跳过thinking_type的内部推理,直接推出新状态。但是由于没有良好的监督信号告诉模型哪些步骤需要被跳过,因此暂时没有办法实现部分type直接使用Linear attention完全跳过推理。
0 条评论