https://arxiv.org/pdf/2103.10360.pdf
1.动机
–
2.模型结构与数据构造
2.1 数据构造
GLM通过设计自回归的完形填空任务,将NLU和NLG较好的统一到了一个模型下,十分类似于UniLM,或者说就是UniLM,input部分为双向attention,而mask和生成部分为单项attention。模型结构如下图所示
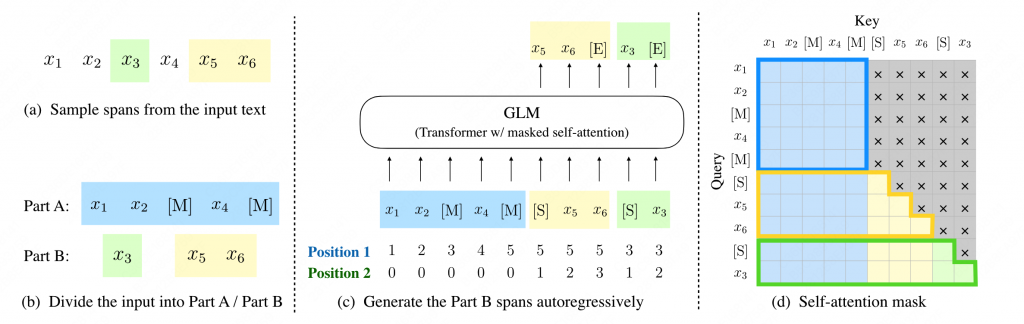
在训练策略上,主要有以下几点:
- GLM把预训练任务设计成完形填空形式的灵感来源于Pattern-Exploiting Training(PET)
- GLM从输入文本中随机挖出几个包含连续token的span后的Mask,然后再句子末尾通过自回归的方式生成被挖出的span的全部内容。
- 原始的输入部分采用双向注意力机制。
- 输入句子后面的填空和生成部分采用单项注意机制。
- 相对Prefix LM(UniLM),新增了2D position embedding。

如上图,Mask了pos4和pos5,其中pos4 MASK的词长度为2,pos5 长度为2。2D position的embedding样例如图所示。
对于NLU任务,按照PET的做法,将NLU任务重新定义成自回归的填空生成任务。
eg: a sentiment classification task can be formulated as “{SENTENCE}. It’s really [MASK]”.
对于NLG任务,在输入的句子末尾添加Mask标记,要求模型紧接着生成。
2.2 模型细节
位置编码使用RoPE,同时前馈层使用了基于GELU的GLU-GeGLU。作为对比,PaLM使用SwiGLU,OPT、GPT、BLOOM使用的是原始的FFN。
3.训练策略
3.1 数据策略
GLM的预训练部分包含了两种数据:
- 95%的自回归文本生成任务
- 5%的任务型对话
同时,为了同时支持NLU和NLG,设计了2种mask任务。
- [MASK] 阅读理解任务的MASK,mask比例和bert一样,15%mask。
- [gMASK] 文本生成的mask,在输入末尾拼接gmask,随后开始自回归续写。
两种mask的数据比例为3:7。
3.2 模型训练
GLM130B使用了96张A100*40G训练了60天,累计使用了600B token,其中中英文各200B。
3.2.1 如何增项训练稳定性
对比了Pre-Norm、Post-Norm 累计训练了30多次都没有办法有比较好的稳定性,最终选择了DeepNorm,获得了较为稳定的训练过程。
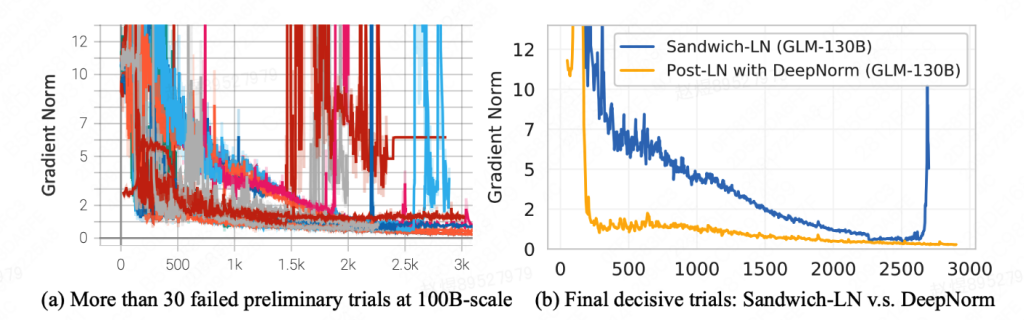
训练时,也依然使用了混合精度来保证训练的稳定性。
不过依然发现,会出现loss spike,训练不稳定。结合DeepNorm的结论,本文继续探索了各层之间的梯度,最终确定主要原因是embedding的梯度相对较大。
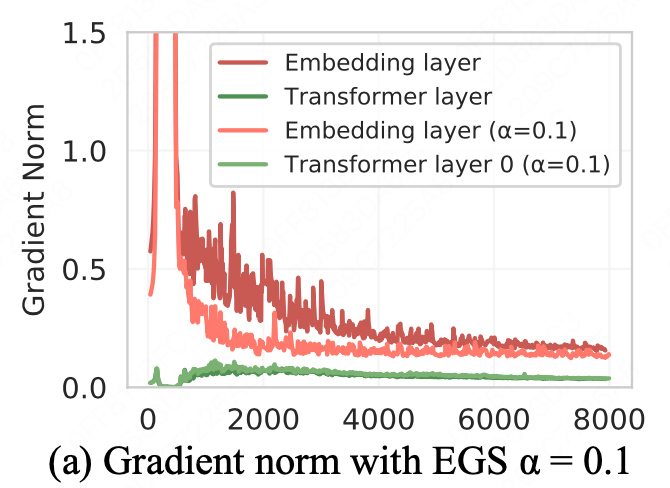
使用了一个α的平滑(EGS),来人为的降低梯度的更新范围,使得训练更为稳定。
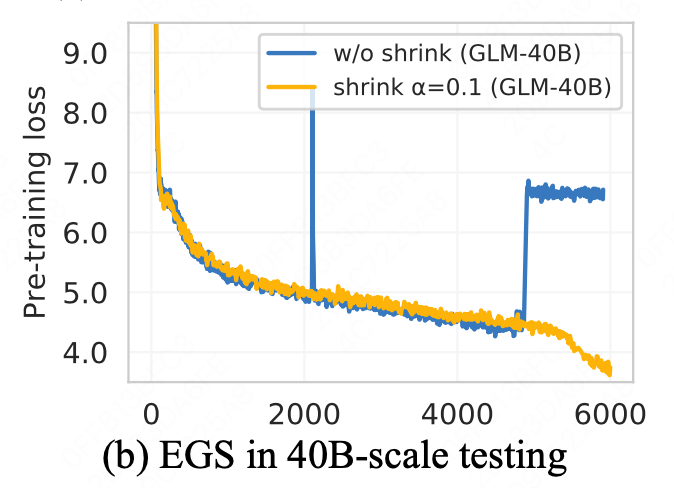
同时,由于初始化以及梯度相对较小,使得模型的最终的参数分布更加集中,更容易进行量化。GLM甚至可以进行INT4的量化。减轻了推理成本。
4.实验效果
–
0 条评论