传统的Bert采用了Post-Norm的方法,而例如最近的Bloom、LLama都使用了Pre-Norm的方法。那么这两个有什么区别呢?
首先查看Bert的Post-Norm,是在Add操作后进行Norm操作,因此叫做Post-Norm。
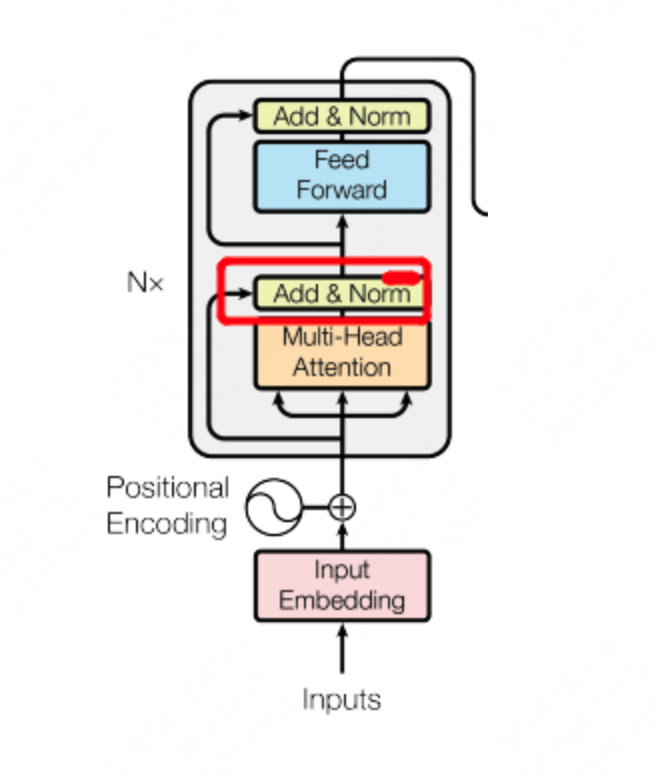
而Pre-Norm则是Norm之后再Add,所以叫Pre-Norm。
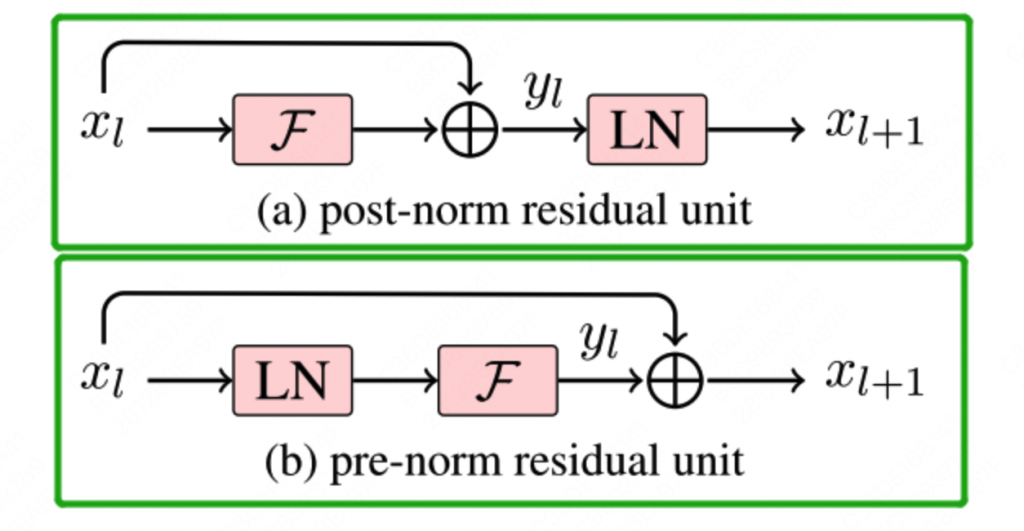
Pre-Norm和Post-Norm有什么区别?
简单说就是Post-Norm由于是在残差之后进行归一化,因此归一化的效果更好,使得模型的鲁棒性更强。
而Pre-Norm由于并不是所有的参数都参与正则化,因此整体来说更不容易发生梯度消失的问题,模型训练的稳定性更强。
因此,在Bert时代由于层数较浅,往往采用的是Post-Norm,而到了大模型时代,由于transformer的层数开始加深,为了训练稳定性开始使用Pre-Norm。
那么有没有既要又要的操作呢?
DeepNorm
微软的一个实习生提出来了一个DeepNorm,它可以稳定的训练千层的transformer。而GLM也是使用了这种Norm,使得百亿模型在整个训练过程中只出现了3次loss异常(当然也有别的措施)。
0 条评论