http://arxiv.org/abs/2203.00555
1.动机
我们知道transformer的深度比广度更为重要,因此理论上同等参数量的网络,更深比更宽更为重要。但是训练深层transformer极其不稳定,本文提出了一个新的DeepNorm,可以稳定训练千层transformer,同时本文还分析了一下为什么会出现训练的不稳定。
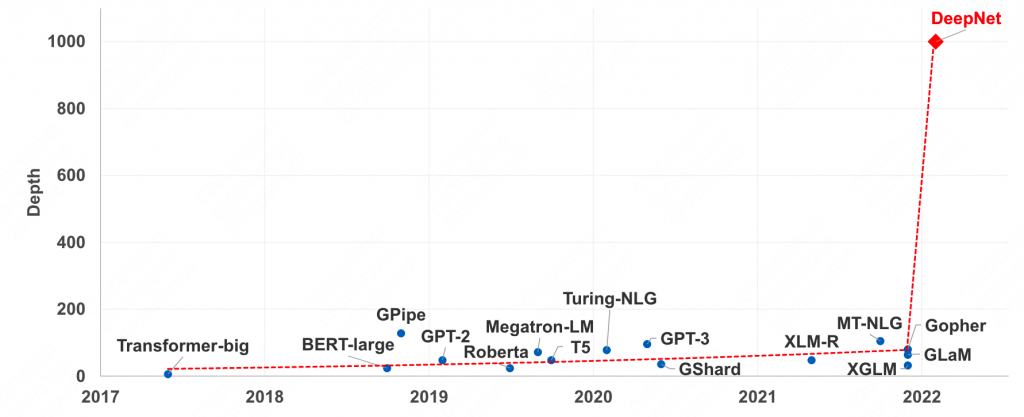
使用DeepNorm的千层transformer在3.2B参数下的性能会超过12B模型5个点。
2.为什么会出现训练不稳定
我们知道,相比Pre-Norm,Post-Norm的训练更加不稳定。因此使用Post-Norm来进行实验。其中Post-LN-init为使用了一种特殊的初始化方案的模型,后面会讲到。
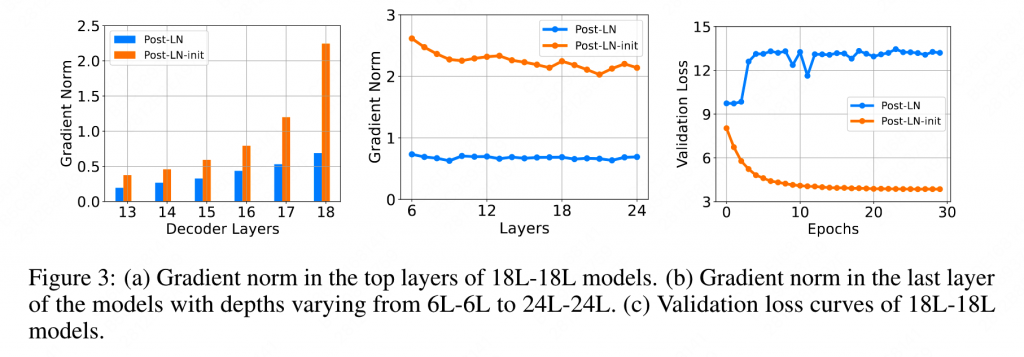
从上图中可以看出,经过特殊init之后,越靠近输出层的地方梯度越大,同时最后一层的梯度也更加稳定,随着训练的继续,模型(loss)也没有崩掉。同时也可以证明,其实模型训坏掉并不是最后一层的梯度过大(因为图b init的梯度更大,但是没有崩掉)。
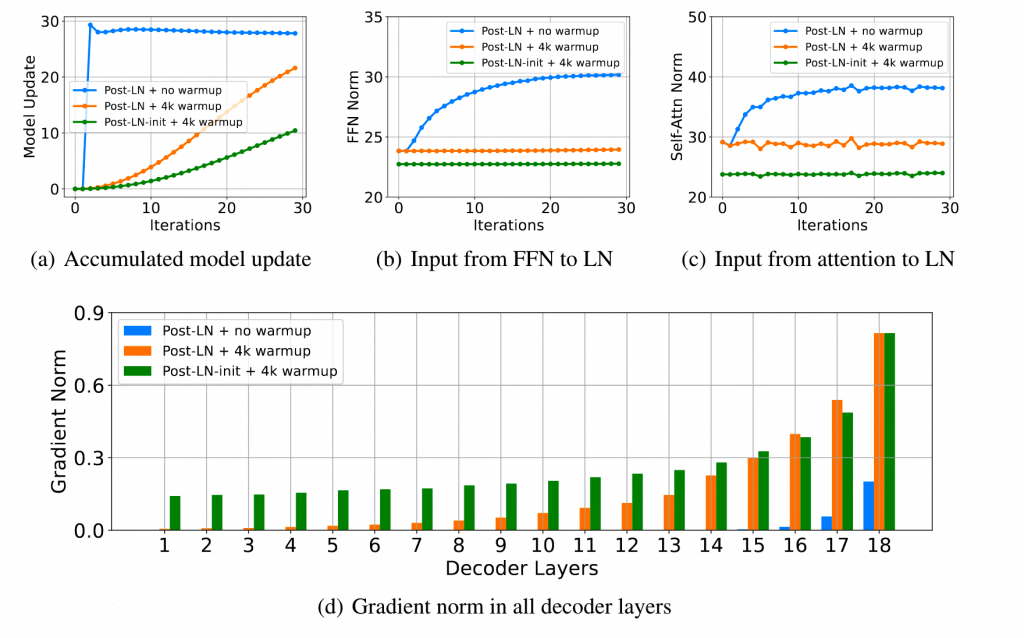
作者认为,出现训练不稳定(梯度消失/爆炸)的主要原因是同时更新的参数过多。比如上图的(a),Post-LN-no warmup在一开始更新了过多的参数,导致模型错误的进入了一个局部最优解。由于LN的梯度大小与LN的输入成反比,因此当更新的参数量过大时,会使LN的输入变大(图b图c)因此这也导致了LN梯度逐渐消失,使得模型很难脱离出局部最优解,进一步破坏了算法的稳定性。而Post LN init或者warmup更新的参数很小,LN相对稳定,减轻了梯度消失的可能性,使得训练更加稳定。
3.DeepNorm
本文使用了DeepNorm来改善这一问题,DeepNorm主要包括两部分,一个是模型初始化,另一个是对Post-Norm的改进。

简单说就是对Post-Norm中的残差值添加一个变量α,对ffn、V和O矩阵进行了较小的初始化β(因为QK不会影响LN前的值的大小),不同的结构的α、β的取值如上,其中N和M分别问encoder和decoder的层数。
4.实验结果
作者在多个结构多层上进行了一定的实验。
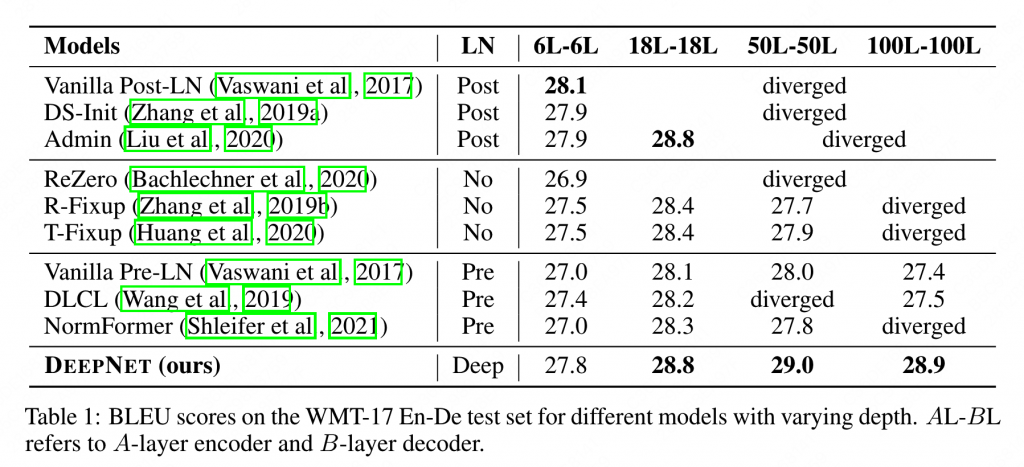
可以看出,Post相比Pre具有更好的性能,但是在18L以上就比较难收敛了。而Deep性能整体和Post相当,但是可以保证有效的收敛。
本文还对不同的结构多层情况下的性能进行了细致的对比(图6),可以发现随着层数的加深,DeepNet性能比较稳定。
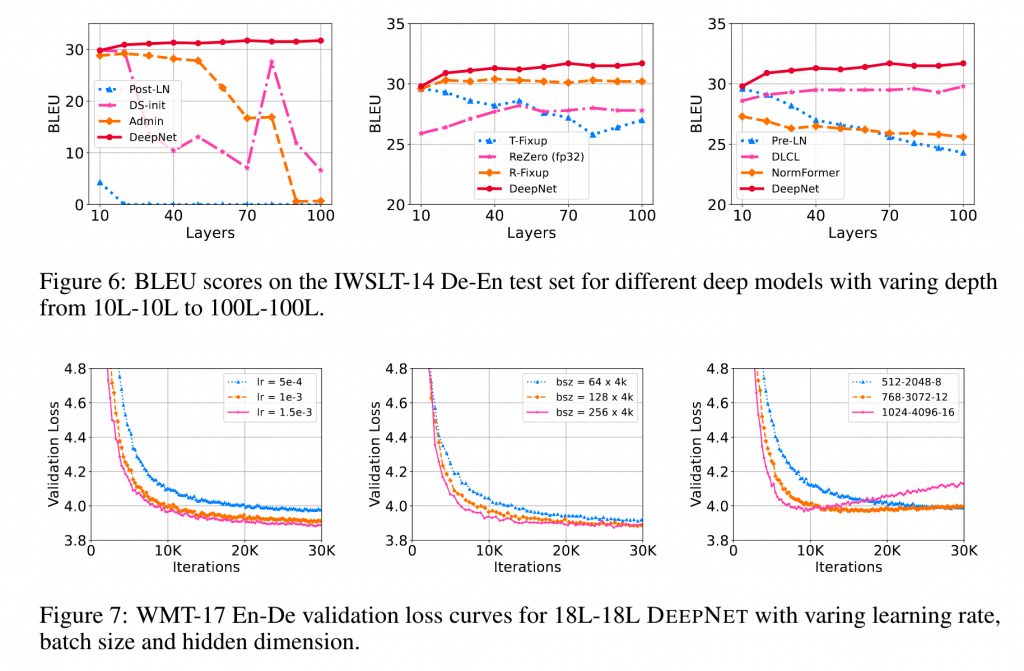
同时,DeepNorm对超参也不那么敏感,可以在多种配置下有效的学习(图7)。
0 条评论