吴恩达深度学习第五课第一周:序列模型
1.为什么选择序列模型
很多任务中数据对先后敏感,举个简单的例子,I love u 和u love i,意思明显不同,因此需要对顺序敏感的模型来处理类似数据。
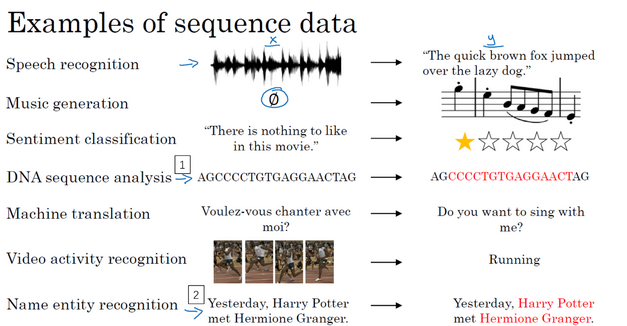
2.循环神经网络(RNN)
循环神经网络就是将上一个输入作为下一个的输入
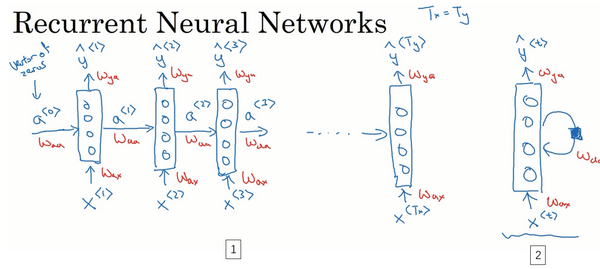
网络前向传播示意图:
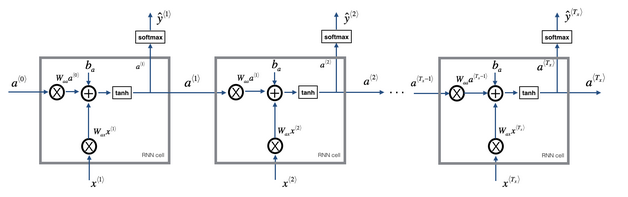
3.循环神经网络的反向传播
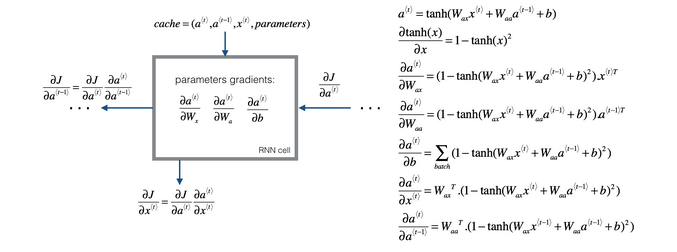
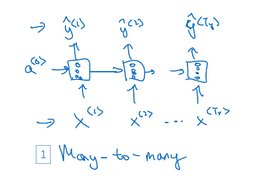
4.不同类型的循环神经网络
根据输入输出个数的不同,大概分为几类:
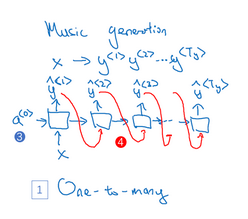
many-to-many:
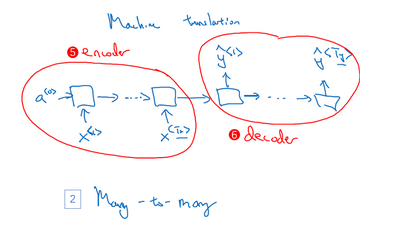
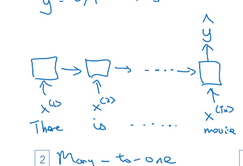
many-to-one:
one-to-one:
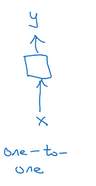
one-to-many:
5.循环神经网络的梯度消失
由于我们的时间序列常常导致神经网络很深,因此也就会产生梯度消失和梯度爆炸的问题,我们可以通过截取参数来避免梯度爆炸,那么梯度消失怎么处理呢。
特别是对于
The cat, which already ate ……, was full.
The cats, which ate ……, were full.
我们就需要记录一个值c,来告诉后面,前面的名词是单数。
这种类似的问题,过长的距离可能导致差异根本影响不到,因此引入门的概念。
6.GRU单元
GRU单元就是通过门控循环单元改变RNN隐藏层结构,使她可以更好地捕捉深层连接,改善了梯度消失。
GRU单元实际上就是通过一个值,来决定当前当前结点计算的值和前一个阶段的结果的占比。
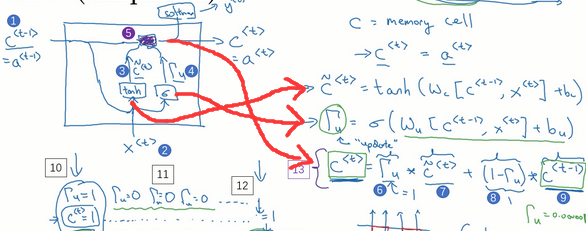
实际上完整的GRU单元还有一个门控,十分类似于上面说的门,上面的门记录了当前结点和上一个结点的关系,因此还有一个记录下一个结点和当前结点的关系。也就是:

因此有完整公式:
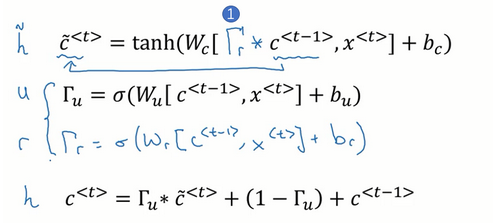
7.长短时记忆网络(LSTM)
LSTM是一个比GRU更强大和通用的版本
相比GRU,LSTM有更新门update、遗忘门forget和输出门output。
而对于update和forget从公式中我们可以看到,实际上就是GRU的(1- Γ )变成了遗忘门。
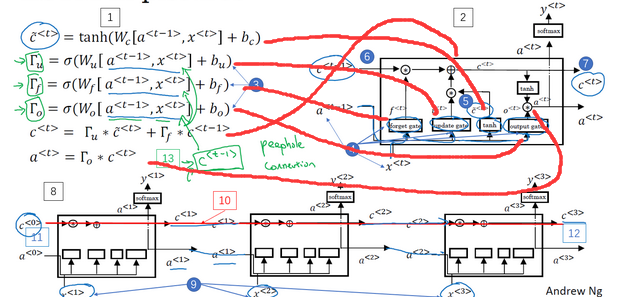
我们很容易的发现,LSTM对于特征c(单复数)有一个横向的传播
8.双向循环神经网络(BRNN)
我们现在已经可以使用RNN获得之前序列的状态,那么之后呢?我们使用两个RNN组合而成的双向循环神经网络BRNN来解决解决这一问题。
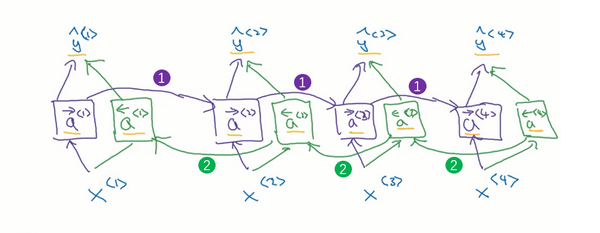
可以看到,这个网络中有两组RNN,一个向前,一个向后,因此这个网络就可以完成对于上下文的关系获取。
9.深层循环神经网络
我们在之前介绍了很深的CNN模型或者DNN模型,对于RNN,由于时间序列较长,我们一般不做很深的网络,三层基本就最多了:
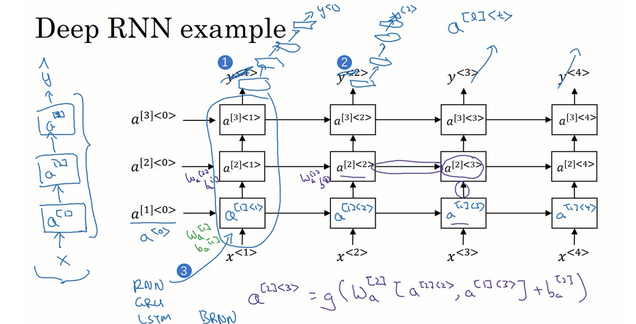
但是对于输出,我们可以继续选择嵌套DNN。
测验
1. 假设你的训练样本是句子(单词序列),下面哪个选项指的是第i个训练样本中的第j个词?
x^{(i)<j>}
2. 看一下下面的这个循环神经网络:
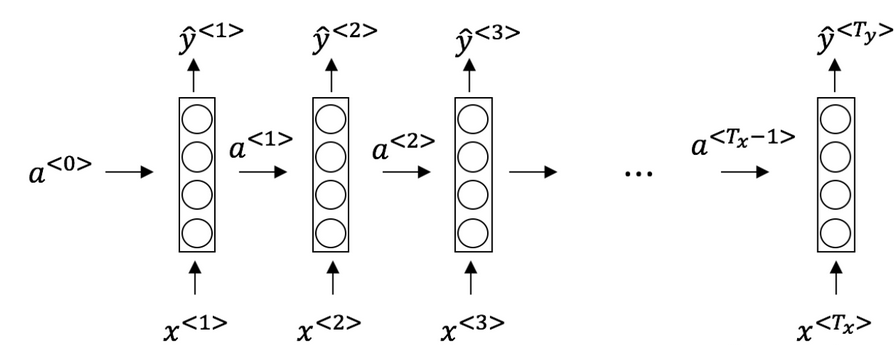
在下面的条件中,满足上图中的网络结构的参数是:
- Tx=Ty
- Tx<Ty
- Tx>Ty
- Tx = 1
1。(每一个输入都有一个输出)
3. 这些任务中的哪一个会使用多对一的RNN体系结构?
- 语音识别(输入语音,输出文本)
- 情感分类(输入一段文字,输出0或1表示正面或者负面的情绪
- 图像分类(输入一张图片,输出对应的标签)。
- 人声性别识别(输入语音,输出说话人的性别)。
2,4。
4. 假设你现在正在训练下面这个RNN的语言模型: 在t时,这个RNN在做什么?
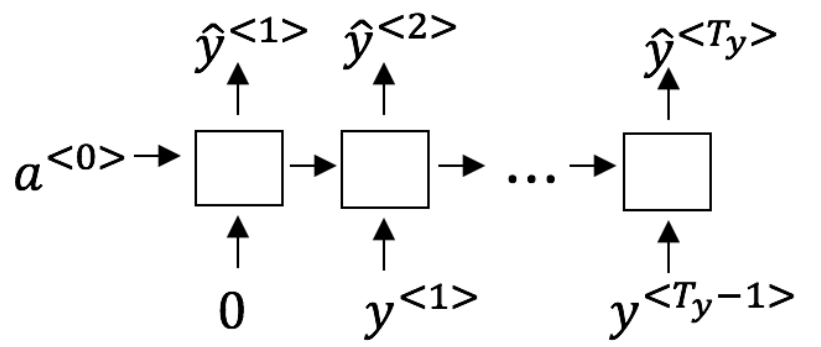
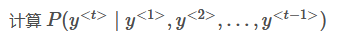
5. 你已经完成了一个语言模型RNN的训练,并用它来对句子进行随机取样,如下图: 在每个时间步t都在做什么?
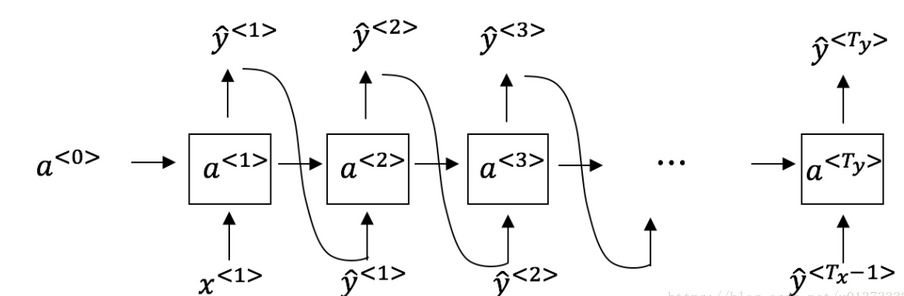
- (1)使用RNN输出的概率,选择该时间步的最高概率单词作为y^<t>,(2)然后将训练集中的正确的单词传递到下一个时间步。
- (i)使用由RNN输出的概率将该时间步的所选单词进行随机采样作为 y^<t>,(2)然后将训练集中的实际单词传递到下一个时间步。
- (1)使用由RNN输出的概率来选择该时间步的最高概率词作为 y^<t>,(2)然后将该选择的词传递给下一个时间步。
- (1)使用RNN该时间步输出的概率对单词随机抽样的结果作为y^<t>,(2)然后将此选定单词传递给下一个时间步。
4。(因为题目中说了对句子进行随机取样)
6. 你正在训练一个RNN网络,你发现你的权重与激活值都是“NaN”,下列选项中,哪一个是导致这个问题的最有可能的原因?
梯度爆炸。
7. 假设你正在训练一个LSTM网络,你有一个10,000词的词汇表,并且使用一个激活值维度为100的LSTM块,在每一个时间步中,Γu的维度是多少?
100。(激活值维度=LSTM长度=门控个数)
8. 这里有一些GRU的更新方程: 爱丽丝建议通过移除 Γu来简化GRU,即设置Γu=1。贝蒂提出通过移除Γr来简化GRU,即设置Γr=1。哪种模型更容易在梯度不消失问题的情况下训练,即使在很长的输入序列上也可以进行训练?

- 爱丽丝的模型(即移除Γu),因为对于一个时间步而言,如果Γr≈0,梯度可以通过时间步反向传播而不会衰减。
- 爱丽丝的模型(即移除Γu),因为对于一个时间步而言,如果Γr≈1,梯度可以通过时间步反向传播而不会衰减。
- 贝蒂的模型(即移除Γr),因为对于一个时间步而言,如果Γu≈0,梯度可以通过时间步反向传播而不会衰减。
- 贝蒂的模型(即移除Γr),因为对于一个时间步而言,如果Γu≈1,梯度可以通过时间步反向传播而不会衰减。
3。( 要使信号反向传播而不消失,我们需要 c<t>高度依赖于c<t−1> )
9. 这里有一些GRU和LSTM的方程: 从这些我们可以看到,在LSTM中的更新门和遗忘门在GRU中扮演类似 –––––与–––––的角色,空白处应该填什么?
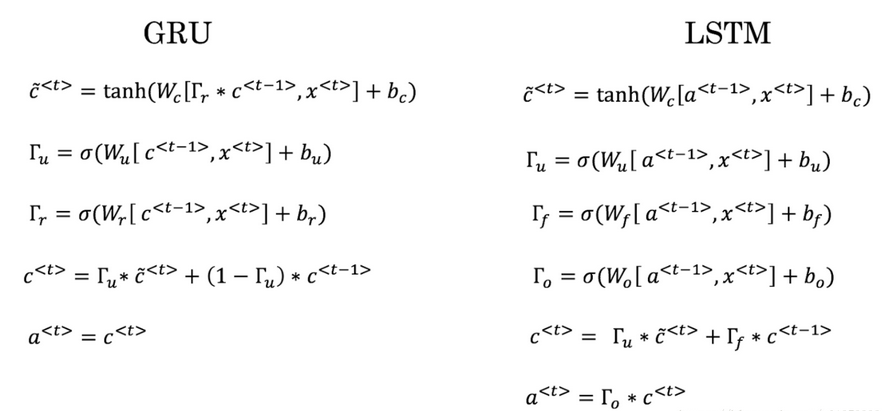
Γu 与 1−Γu
10. 你有一只宠物狗,它的心情很大程度上取决于当前和过去几天的天气。你已经收集了过去365天的天气数据x<1>,…,x<365>,这些数据是一个序列,你还收集了你的狗心情的数据y<1>,…,y<365>,你想建立一个模型来从x到y进行映射,你应该使用单向RNN还是双向RNN来解决这个问题?
单向RNN,因为狗也不能预知未来x。
编程作业
首先简单实现以下RNN和LSTM然后使用RNN预测恐龙名字。
RNN模型和公式如下:
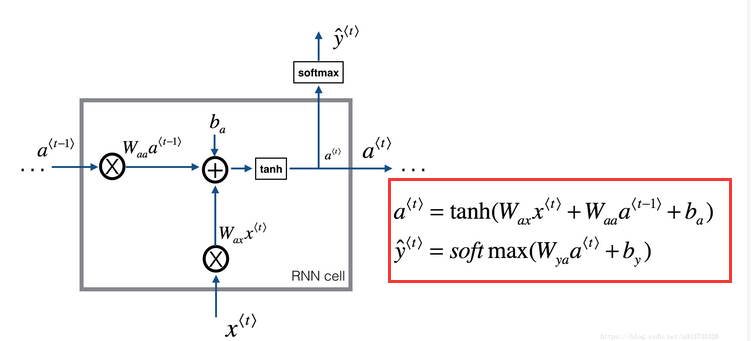
首先导包:
import numpy as np
from course_5_week_1 import rnn_utils
然后是一个cell的前向传播,其中最主要的就是哪两个公式:
def rnn_cell_forward(xt, a_prev, parameters):
"""
rnn cell前向传播
:param xt:
:param a_prev:
:param parameters:
:return:
"""
# 从parameters”获取参数
Wax = parameters["Wax"]
Waa = parameters["Waa"]
Wya = parameters["Wya"]
ba = parameters["ba"]
by = parameters["by"]
a_next = np.tanh(np.dot(Waa, a_prev) + np.dot(Wax, xt) + ba)
# 使用上面的公式计算当前单元的输出
yt_pred = rnn_utils.softmax(np.dot(Wya, a_next) + by)
# 保存反向传播需要的值
cache = (a_next, a_prev, xt, parameters)
return a_next, yt_pred, cache
然后我们做全部的前向传播:
def rnn_forward(X, a0, parameters):
"""
rnn 前向传播
:param X:
:param a0:
:param parameters:
:return:
"""
caches = []
# 获取x和Wya的维度信息
n_x, m, T_x = X.shape
n_y, n_a = parameters['Wya'].shape
# 使用0来初始化a和y
a = np.zeros([n_a, m, T_x])
y_pred = np.zeros([n_y, m, T_x])
# 初始化next
a_next = a0
# 遍历所有的序列
for i in range(T_x):
# cell前向传播
a_next, yt_pred, cache = rnn_cell_forward(X[:, :, i], a_next, parameters)
# 使用 a 来保存“next”隐藏状态(第 i)个位置。
a[:, :, i] = a_next
# 保存预测值
y_pred[:, :, i] = yt_pred
caches.append(cache)
caches = (caches, X)
return a, y_pred, caches
同样,对于LSTM,模型和公式如下:
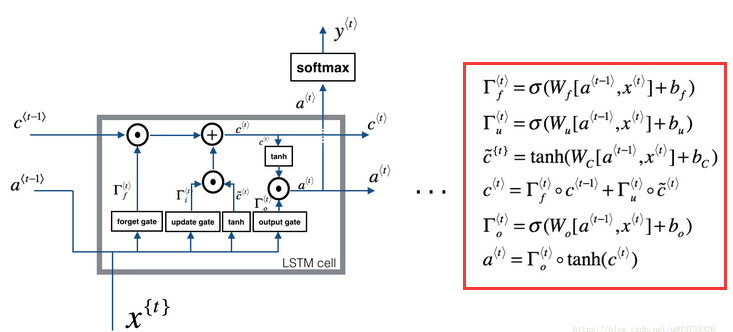
lstm的cell如下,核心还是那6个公式:
def lstm_cell_forward(xt, a_prev, c_prev, parameters):
"""
lstm cell 前向传播
:param xt:
:param a_prev:
:param c_prev:
:param parameters:
:return:
"""
# 从“parameters”中获取相关值
Wf = parameters["Wf"]
bf = parameters["bf"]
Wi = parameters["Wi"]
bi = parameters["bi"]
Wc = parameters["Wc"]
bc = parameters["bc"]
Wo = parameters["Wo"]
bo = parameters["bo"]
Wy = parameters["Wy"]
by = parameters["by"]
# 获取x_t、Wy维度信息
n_x, m = xt.shape
n_y, n_a = Wy.shape
# 链接a_prev与xt
contact = np.zeros([n_a + n_x, m])
contact[:n_a, :] = a_prev
contact[n_a:, :] = xt
# 根据公式计算
# 遗忘门,公式1
ft = rnn_utils.sigmoid(np.dot(Wf, contact) + bf)
# 更新门,公式2
ut = rnn_utils.sigmoid(np.dot(Wi, contact) + bi)
# 更新单元,公式3
cct = np.tanh(np.dot(Wc, contact) + bc)
# 更新单元,公式4
c_next = ft * c_prev + ut * cct
# 输出门,公式5
ot = rnn_utils.sigmoid(np.dot(Wo, contact) + bo)
# 输出门,公式6
# a_next = np.multiply(ot, np.tan(c_next))
a_next = ot * np.tanh(c_next)
# 3.计算LSTM单元的预测值
yt_pred = rnn_utils.softmax(np.dot(Wy, a_next) + by)
# 保存包含了反向传播所需要的参数
cache = (a_next, c_next, a_prev, c_prev, ft, ut, cct, ot, xt, parameters)
return a_next, c_next, yt_pred, cache
因此整个lstm的前向传播如下:
def lstm_forward(x, a0, parameters):
"""
lstm前向传播
:param x:
:param a0:
:param parameters:
:return:
"""
caches = []
n_x, m, T_x = x.shape
n_y, n_a = parameters['Wy'].shape
# 使用0来初始化a,c,y
a = np.zeros([n_a, m, T_x])
c = np.zeros([n_a, m, T_x])
y = np.zeros([n_y, m, T_x])
# 初始化anext cnext
a_next = a0
c_next = np.zeros([n_a, m])
# 遍历所有的时间步
for t in range(T_x):
# 更新下一个隐藏状态,下一个记忆状态,计算预测值,获取cache
a_next, c_next, yt_pred, cache = lstm_cell_forward(x[:, :, t], a_next, c_next, parameters)
# 保存新的下一个隐藏状态到变量a中
a[:, :, t] = a_next
# 保存预测值到变量y中
y[:, :, t] = yt_pred
# 保存下一个单元状态到变量c中
c[:, :, t] = c_next
# 把cache添加到caches中
caches.append(cache)
# 保存反向传播需要的参数
caches = (caches, x)
return a, y, c, caches
然后我们做个简单的RNN网络:
首先导包:
import numpy as np
import random
import time
from course_5_week_1 import cllm_utils as utils
梯度修剪的方法:
def clip(gradients, maxValue):
"""
梯度修剪
:param gradients:
:param maxValue:
:return:
"""
dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients[
'dby']
# 梯度修剪
for gradient in [dWaa, dWax, dWya, db, dby]:
np.clip(gradient, -maxValue, maxValue, out=gradient)
gradients = {
'dWaa': dWaa,
'dWax': dWax,
'dWya': dWya,
'db': db,
'dby': dby
}
return gradients
在网络中进行取样,就是对每一个LSTM的cell取出单词,汇成一个句子:
def sample(parameters, char_to_ix, seed):
"""
取样
:param parameters:
:param char_to_is:
:param seed:
:return:
"""
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
vocab_size = by.shape[0]
n_a = Waa.shape[1]
# 创建one hot 向量
x = np.zeros((vocab_size, 1))
# 初始化a0
a_prev = np.zeros((n_a, 1))
# 输出列表
output = []
# 换行标记
idx = -1
counter = 0
newline_character = char_to_ix['\n']
# 如果不是换行符或者输出不超过50个
while idx != newline_character and counter < 50:
# 前向传播
a = np.tanh(np.dot(Wax, x) + np.dot(Waa, a_prev) + b)
z = np.dot(Wya, a) + by
y = utils.softmax(z)
# 随机数种子
np.random.seed(counter + seed)
# 从随机概率分布中获取字符
idx = np.random.choice(list(range(vocab_size)), p=y.ravel())
# 添加索引
output.append(idx)
x = np.zeros((vocab_size, 1))
x[idx] = 1
# 更新a_prev
a_prev = a
seed += 1
counter += 1
if counter == 50:
output.append(char_to_ix['\n'])
return output
然后是优化方法,包括前向、反向、更新参数:
def optimize(X, y, a_prev, parameters, learning_rate=0.01):
"""
rnn的单步优化
:param X:
:param y:
:param a_prev:
:param parameters:
:param learning_rate:
:return:
"""
# 前向传播
loss, cache = utils.rnn_forward(X, y, a_prev, parameters)
# 反向传播
gradients, a = utils.rnn_backward(X, y, parameters, cache)
# 梯度修剪
gradients = clip(gradients, 5)
# 更新参数
parameters = utils.update_parameters(parameters, gradients, learning_rate)
return loss, gradients, a[len(X) - 1] # 代价 参数 隐藏层
最后将他们全部合成一个模块并调用:
def model(data, ix_to_char, char_to_ix, num_iterations=3500,
n_a=50, dino_names=7, vocab_size=27):
"""
模型
:param data:
:param ix_to_char:
:param char_to_ix:
:param num_iterations:
:param n_a:
:param dino_names:
:param vocab_size:
:return:
"""
# 从vocab_size中获取n_x、n_y
n_x, n_y = vocab_size, vocab_size
# 初始化参数
parameters = utils.initialize_parameters(n_a, n_x, n_y)
# 初始化损失
loss = utils.get_initial_loss(vocab_size, dino_names)
# 构建恐龙名称列表
with open("dinos.txt") as f:
examples = f.readlines()
examples = [x.lower().strip() for x in examples]
# 打乱全部的恐龙名称
np.random.seed(0)
np.random.shuffle(examples)
# 初始化LSTM隐藏状态
a_prev = np.zeros((n_a, 1))
# 循环
for j in range(num_iterations):
# 定义一个训练样本
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]]
# 执行单步优化:前向传播 -> 反向传播 -> 梯度修剪 -> 更新参数
# 选择学习率为0.01
curr_loss, gradients, a_prev = optimize(X, Y, a_prev, parameters)
# 使用延迟来保持损失平滑,这是为了加速训练。
loss = utils.smooth(loss, curr_loss)
# 每2000次迭代,通过sample()生成“\n”字符,检查模型是否学习正确
if j % 2000 == 0:
print("第" + str(j + 1) + "次迭代,损失值为:" + str(loss))
seed = 0
for name in range(dino_names):
# 采样
sampled_indices = sample(parameters, char_to_ix, seed)
utils.print_sample(sampled_indices, ix_to_char)
# 为了得到相同的效果,随机种子+1
seed += 1
print("\n")
return parameters
# 开始时间
start_time = time.clock()
# 开始训练
parameters = model(data, ix_to_char, char_to_ix, num_iterations=3500)
# 结束时间
end_time = time.clock()
# 计算时差
minium = end_time - start_time
print("执行了:" + str(int(minium / 60)) + "分" + str(int(minium % 60)) + "秒")
输出:
第1次迭代,损失值为:23.0873360855
Nkzxwtdmfqoeyhsqwasjkjvu
Kneb
Kzxwtdmfqoeyhsqwasjkjvu
Neb
Zxwtdmfqoeyhsqwasjkjvu
Eb
Xwtdmfqoeyhsqwasjkjvu
第2001次迭代,损失值为:27.8841604914
Liusskeomnolxeros
Hmdaairus
Hytroligoraurus
Lecalosapaus
Xusicikoraurus
Abalpsamantisaurus
Tpraneronxeros
执行了:0分3秒我们可以看到效果明显变好了,更像一个名字了。
0 条评论