吴恩达深度学习第五课第二周 自然语言处理与词嵌入

1.词汇表征
之前使用的one-hot编码方式,没有办法获得词的关联信息,因此对于下图例句中apple 和orange的泛化不是很好,因此引入基于特征的词嵌入:

具有相关属性的词嵌入向量十分靠近,因此对于apple和orange很容易被判断为相近的意思。
2.使用词嵌入
对于之前的one-hot编码,如果我们遇到的词one-hot并没有编码则会发生对句子的错误理解。
但是词嵌入由于学习模型很大,通常都是百万级的,因此可以遇到更好的词语表示。
我们同样也可以使用迁移训练来完成自己的词嵌入:

3.词嵌入的特性
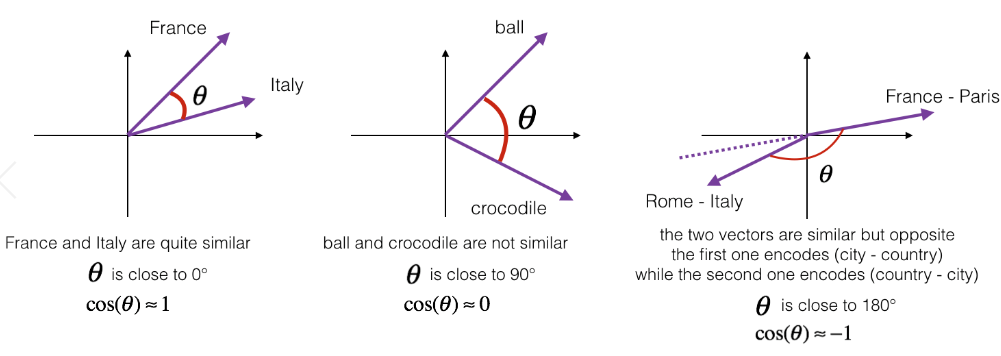
词嵌入还可以进行推理任务。
比如man对应woman、king对应queen等。
简单说就是我们通过向量差异构成一个平行四边形,以确定对应关系:
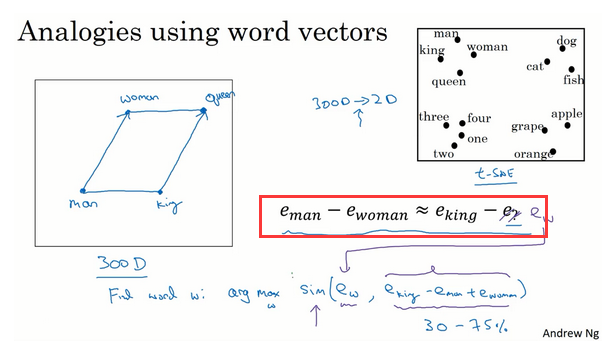
因此我们可以通过相似度来进行词推理。
4.学习词嵌入
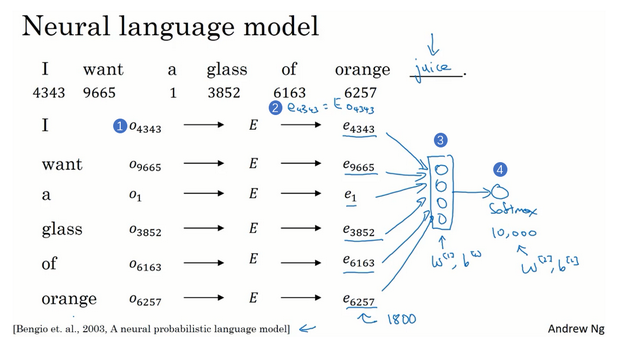
我们将多个单词的词嵌入连接起来送入softmax预测下一个单词:
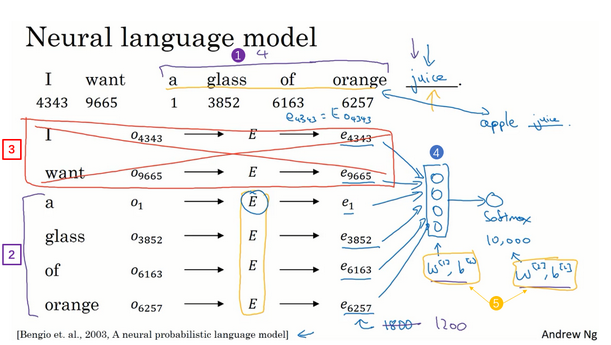
为了防止句子过长造成的问题,一般我们使用一个窗口,比如下面就是使用窗口大小为4,向后预测(预测juice)
5.Word2Vec
假设在训练集中给定了一个这样的句子:“I want a glass of orange juice to go along with my cereal.”,在Skip-Gram模型中,我们要做的是抽取上下文和目标词配对,来构造一个监督学习问题。上下文不一定总是目标单词之前离得最近的四个单词,或最近的个单词。我们要的做的是随机选一个词作为上下文词,比如选orange这个词,然后我们要做的是随机在一定词距内选另一个词,比如在上下文词前后5个词内或者前后10个词内,我们就在这个范围内选择目标词。可能你正好选到了juice作为目标词,正好是下一个词(表示orange的下一个词),也有可能你选到了前面第二个词,所以另一种配对目标词可以是glass,还可能正好选到了单词my作为目标词。
我们继续假设使用一个10,000词的词汇表,有时训练使用的词汇表会超过一百万词。但我们要解决的基本的监督学习问题是学习一种映射关系,从上下文c,比如单词orange,到某个目标词,记为t,可能是单词juice或者单词glass或者单词my。延续上一张幻灯片的例子,在我们的词汇表中,orange是第6257个单词,juice是10,000个单词中的第4834个,这就是你想要的映射到输出y的输入x。
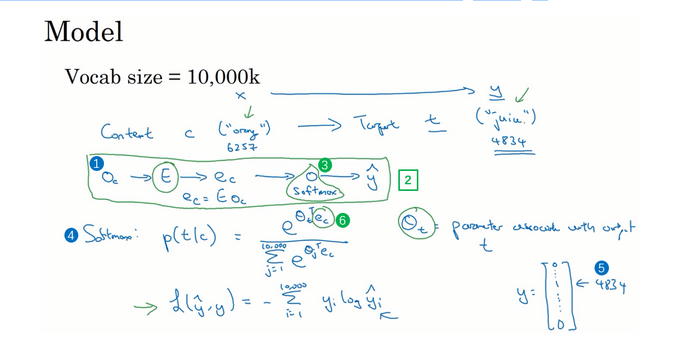
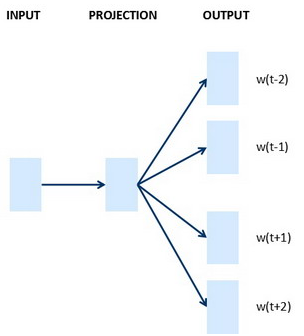
类似于注意力机制?
6.Glove词向量
通过一个窗口的移动,然后判断窗口中间的词和其他词的关系。
比如:中心词为love,语境词为but、you、him、i;则执行:
Xlove,but+=1
Xlove,you+=1
Xlove,him+=1
Xlove,i+=1
使用窗口将整个语料库遍历一遍,即可得到共现矩阵X。


测验:
1. 假设你为10000个单词学习词嵌入,为了捕获全部范围的单词的变化以及意义,那么词嵌入向量应该是10000维的。
错误。
2. 什么是t-SNE?
- 一种非线性降维算法
- 一种能够解决词向量上的类比的线性变换。
- 一种用于学习词嵌入的监督学习算法。
- 一个开源序列模型库。
1。
3. 假设你下载了一个已经在一个很大的文本语料库上训练过的词嵌入的数据,然后你要用这个词嵌入来训练RNN并用于识别一段文字中的情感,判断这段文字的内容是否表达了“快乐”。

那么即使“欣喜若狂”这个词没有出现在你的小训练集中,你的RNN也会认为“我欣喜若狂”应该被贴y = 1的标签。
正确。
4. 对于词嵌入而言,下面哪一个(些)方程是成立的?
e_{boy} = e_{ girl } ≈ e_{ brother } – e_{sister}
e_{boy} – e_{brother} ≈ e_{girl} – e_{sister}
5. 设E为嵌入矩阵,e1234对应的是词“1234”的独热向量,为了获得1234的词嵌入,为什么不直接在Python中使用代码E∗e1234呢?
因为这个操作是在浪费计算资源。
6.在学习词嵌入时,我们创建了一个预测P(target∣context)的任务,如果这个预测做的不是很好那也是没有关系的,因为这个任务更重要的是学习了一组有用的嵌入词。
错误。
7. 在word2vec算法中,你要预测P(t∣c),其中t是目标词(target word),c是语境词(context word)。你应当在训练集中怎样选择t 与 c呢?
c 与 t 应当在附近词中。
8. 假设你有1000个单词词汇,并且正在学习500维的词嵌入,word2vec模型使用下面的softmax函数, 以下说法中哪一个(些)是正确的?
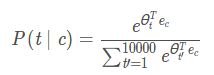
- θt 与 ec 都是500维的向量。
- θt 与 ec 都是10000维的向量。
- θt 与 ec 都是通过Adam或梯度下降等优化算法进行训练的。
- 训练之后,θt应该非常接近ec,因为t和c是一个词。
1,3。
9. 假设你有10000个单词词汇,并且正在学习500维的词嵌入,GloVe模型最小化了这个目标,一下那个说法正确
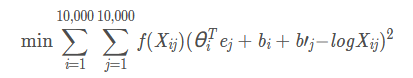
- θi 与 ej 应当初始化为0。
- θi 与 ej 应当使用随机数进行初始化。
- Xij 是单词i在j中出现的次数。
- 加权函数 f(.) 必须满足 f(0)=0。
2,3,4。
10. 你已经在文本数据集m1上训练了词嵌入,现在准备将它用于一个语言任务中,对于这个任务,你有一个单独标记的数据集m2 ,请记住,使用词嵌入是一种迁移学习的形式,在这哪情况下,你认为词嵌入会有帮助吗?
m1>>m2
编程作业
本周编程作业分为三部分:
第一部分,熟悉词向量
第二部分,使用词向量来进行emoji预测
第三部分,使用LSTM+词向量对emoji进行预测
1.熟悉词向量
首先导包:
import numpy as np
from course_5_week_2 import w2v_utils
加载已经训练好的词向量:
# 加载词向量
words, word_to_vec_map = w2v_utils.read_glove_vecs('data/glove.6B.50d.txt')
然后我们可以根据余弦相似度来判断两个词的相关性:
def cosine_similarity(u, v):
"""
余弦相似度
:param u:
:param v:
:return:
"""
distance = 0
# 计算u与v的内积
dot = np.dot(u, v)
# 计算u的第2范数
norm_u = np.sqrt(np.sum(np.power(u, 2)))
# 计算v的第二范数
norm_v = np.sqrt(np.sum(np.power(v, 2)))
# 计算余弦相似度
cosine_similarity = np.divide(dot, norm_u * norm_v)
return cosine_similarity
还可以找类似的词,比如根据男女之间的关系找出丈夫对应什么
e.g.
italy -> italian <====> spain -> spanish
india -> delhi <====> japan -> tokyo
man -> woman <====> boy -> girl
small -> smaller <====> large -> largerdef complete_analogy(word_a, word_b, word_c, word_to_vec_map):
"""
a与b相比就类似于d与____相比一样
:param word_a:
:param word_b:
:param word_to_vec_map:
:return:
"""
# 单词转换为小写
word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower()
# 获取词向量
e_a, e_b, e_c = word_to_vec_map[word_a], word_to_vec_map[word_b], word_to_vec_map[word_c]
# 获取全部单词
words = word_to_vec_map.keys()
# 初始化
max_cosine_sim = -100
best_word = None
# 遍历整个数据集
for word in words:
if word in [word_a, word_b, word_c]:
continue
cosine_sim = cosine_similarity(e_b - e_a, word_to_vec_map[word] - e_c)
if cosine_sim > max_cosine_sim:
max_cosine_sim = cosine_sim
best_word = word
return best_word
然后是emoji预测:
首先导包:
import numpy as np
from course_5_week_2 import emo_utils
读取数据:
X_train, Y_train = emo_utils.read_csv('./data/train_emoji.csv')
X_test, Y_test = emo_utils.read_csv('./data/test.csv')
maxLen = len(max(X_train, key=len).split())
index = 3
print(X_train[index], emo_utils.label_to_emoji(Y_train[index]))
Y_oh_train = emo_utils.convert_to_one_hot(Y_train, C=5)
Y_oh_test = emo_utils.convert_to_one_hot(Y_test, C=5)
word_to_index, index_to_word, word_to_vec_map = emo_utils.read_glove_vecs('data/glove.6B.50d.txt')
一个可以返回描述句子平均词向量的方法:
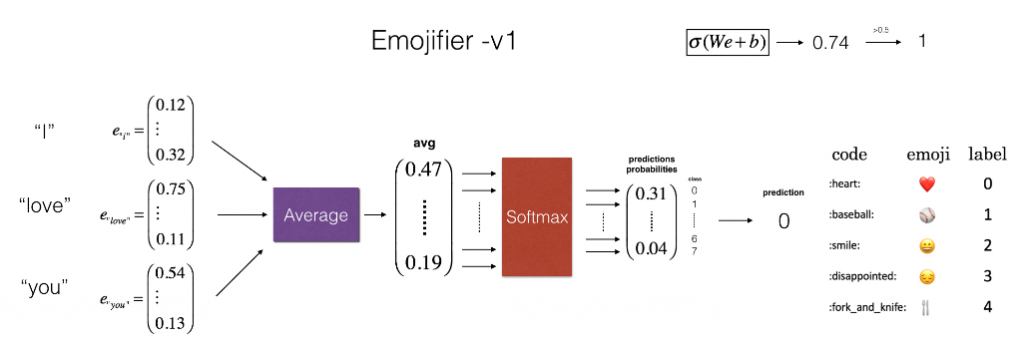
def sentence_to_avg(sentence, word_to_vec_map):
"""
返回句子的平均词向量
:param sentence:
:param word_to_vec_map:
:return:
"""
words = sentence.lower().split()
avg = np.zeros(50)
for word in words:
avg += word_to_vec_map[word]
avg = np.divide(avg, len(words))
return avg
然后写一个模型(一个很简单的神经网络)并训练:
def model(X, Y, word2vec_map, learning_rate=0.01, num_iterations=400):
"""
整体模型
:param X:
:param Y:
:param word2vec_map:
:param learning_rate:
:param num_iterations:
:return:
"""
np.random.seed(1)
# 定义训练数量
m = Y.shape[0]
n_y = 5
n_h = 50
# 使用Xavier初始化参数
W = np.random.randn(n_y, n_h) / np.sqrt(n_h)
b = np.zeros((n_y,))
# 将Y转换成one hot编码
Y_oh = emo_utils.convert_to_one_hot(Y, C=n_y)
for t in range(num_iterations):
for i in range(m):
# 获取第i个训练样本的均值
avg = sentence_to_avg(X[i], word2vec_map)
# 前向传播
z = np.dot(W, avg) + b
a = emo_utils.softmax(z)
# 计算第i个训练的损失
cost = -np.sum(Y_oh[i] * np.log(a))
# 计算梯度
dz = a - Y_oh[i]
dW = np.dot(dz.reshape(n_y, 1), avg.reshape(1, n_h))
db = dz
# 更新参数
W = W - learning_rate * dW
b = b - learning_rate * db
if t % 100 == 0:
print("第{t}轮,损失为{cost}".format(t=t, cost=cost))
pred = emo_utils.predict(X, Y, W, b, word2vec_map)
return pred, W, b
pred, W, b = model(X_train, Y_train, word_to_vec_map)
print("=====训练集====")
pred_train = emo_utils.predict(X_train, Y_train, W, b, word_to_vec_map)
print("=====测试集====")
pred_test = emo_utils.predict(X_test, Y_test, W, b, word_to_vec_map)
X_my_sentences = np.array(["i adore you", "i love you", "funny lol", "lets play with a ball", "food is ready", "you are not happy"])
Y_my_labels = np.array([[0], [0], [2], [1], [4],[3]])
pred = emo_utils.predict(X_my_sentences, Y_my_labels , W, b, word_to_vec_map)
emo_utils.print_predictions(X_my_sentences, pred)
对于上面这种,很显然无法有效的区分出happy 和 not happy的关系,因此引入SLTM的emoji预测:
由于神经网络需要一个固定的长度,因为我们需要对句子进行截取或者填0:
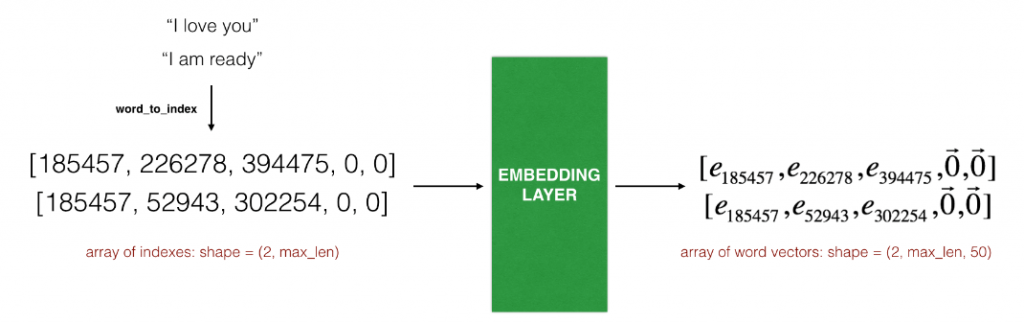
def sentences_to_indices(X, word_to_index, max_len):
"""
将句子扩充到max len长度
:param X:
:param word_to_index:
:param max_len:
:return:
"""
m = X.shape[0] # 训练集数量
# 使用0初始化X_indices
X_indices = np.zeros((m, max_len))
for i in range(m):
# 将第i个居住转化为小写并按单词分开。
sentences_words = X[i].lower().split()
# 初始化j为0
j = 0
# 遍历这个单词列表
for w in sentences_words:
# 将X_indices的第(i, j)号元素为对应的单词索引
X_indices[i, j] = word_to_index[w]
j += 1
return X_indices
然后生成这个embedding层:
def pretrained_embedding_layer(word_to_vec_map, word_to_index):
"""
:param word_to_vec_map:
:param word_to_index:
:return:
"""
vocab_len = len(word_to_index) + 1
emb_dim = word_to_vec_map["cucumber"].shape[0]
# 初始化嵌入矩阵(dict to list)
emb_matrix = np.zeros((vocab_len, emb_dim))
# 将嵌入矩阵的每行的“index”设置为词汇“index”的词向量表示
for word, index in word_to_index.items():
emb_matrix[index, :] = word_to_vec_map[word]
# 定义Keras的embbeding层
embedding_layer = keras.layers.embeddings.Embedding(vocab_len, emb_dim, trainable=False)
# 构建embedding层。
embedding_layer.build((None,))
# 将嵌入层的权重设置为嵌入矩阵。
embedding_layer.set_weights([emb_matrix])
return embedding_layer
最后写一个LSTM并且训练:
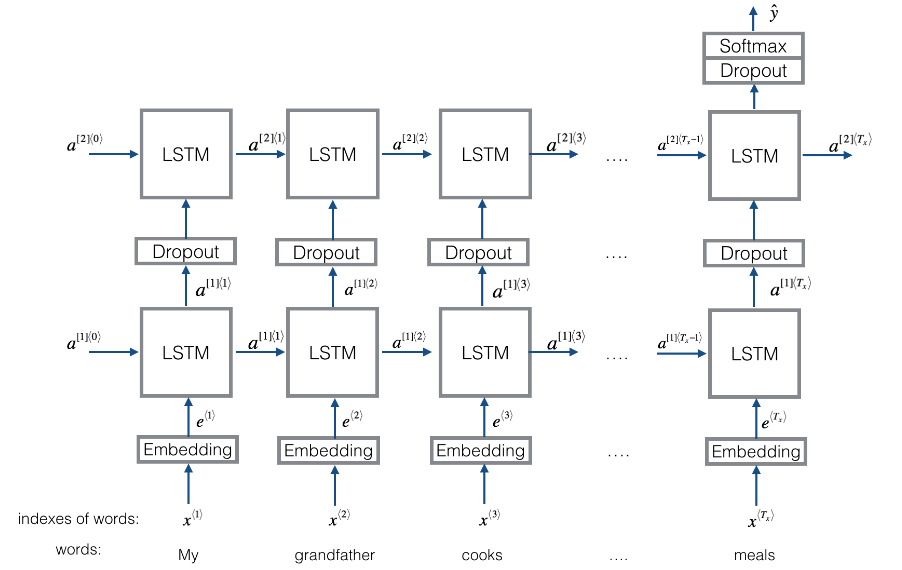
def model(input_shape, word_to_vec_map, word_to_index):
"""
算法实现
:param input_shape:
:param word_to_vec_map:
:param word_to_index:
:return:
"""
# 定义sentence_indices为计算图的输入,维度为(input_shape,),类型为dtype 'int32'
sentence_indices = keras.Input(input_shape, dtype='int32')
# 创建embedding层
embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
# 通过嵌入层传播sentence_indices,你会得到嵌入的结果
embeddings = embedding_layer(sentence_indices)
# 通过带有128维隐藏状态的LSTM层传播嵌入
# 需要注意的是,返回的输出应该是一批序列。
X = keras.layers.LSTM(128, return_sequences=True)(embeddings)
# 使用dropout,概率为0.5
X = keras.layers.Dropout(0.5)(X)
# 通过另一个128维隐藏状态的LSTM层传播X
# 注意,返回的输出应该是单个隐藏状态,而不是一组序列。
X = keras.layers.LSTM(128, return_sequences=False)(X)
# 使用dropout,概率为0.5
X = keras.layers.Dropout(0.5)(X)
# 通过softmax激活的Dense层传播X,得到一批5维向量。
X = keras.layers.Dense(5)(X)
# 添加softmax激活
X = keras.layers.Activation('softmax')(X)
# 创建模型实体
model = keras.Model(inputs=sentence_indices, outputs=X)
return model
X_train, Y_train = emo_utils.read_csv('./data/train_emoji.csv')
X_test, Y_test = emo_utils.read_csv('./data/test.csv')
max_len = 10
model = model((max_len,), word_to_vec_map, word_to_index)
# model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
X_train_indices = sentences_to_indices(X_train, word_to_index, max_len)
Y_train_oh = emo_utils.convert_to_one_hot(Y_train, C=5)
model.fit(X_train_indices, Y_train_oh, epochs=50, batch_size=32, shuffle=True)
X_test_indices = sentences_to_indices(X_test, word_to_index, max_len=max_len)
Y_test_oh = emo_utils.convert_to_one_hot(Y_test, C=5)
loss, acc = model.evaluate(X_test_indices, Y_test_oh)
print("Test accuracy = ", acc)
C = 5
y_test_oh = np.eye(C)[Y_test.reshape(-1)]
X_test_indices = sentences_to_indices(X_test, word_to_index, max_len)
pred = model.predict(X_test_indices)
for i in range(len(X_test)):
x = X_test_indices
num = np.argmax(pred[i])
if num != Y_test[i]:
print('正确表情:' + emo_utils.label_to_emoji(Y_test[i]) + ' 预测结果: ' + X_test[i] + emo_utils.label_to_emoji(
num).strip())
0 条评论