吴恩达深度学习第五课 第三周 序列模型和注意力机制

1.Seq2Seq
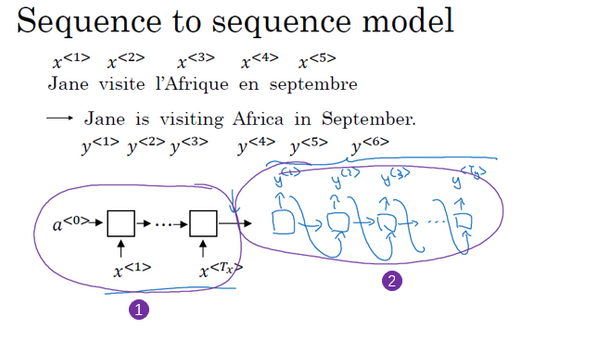
seq2seq模型就是编码-解码模型,常用于句子翻译这类输入输出长度不一致的问题中。
2.Beam Search
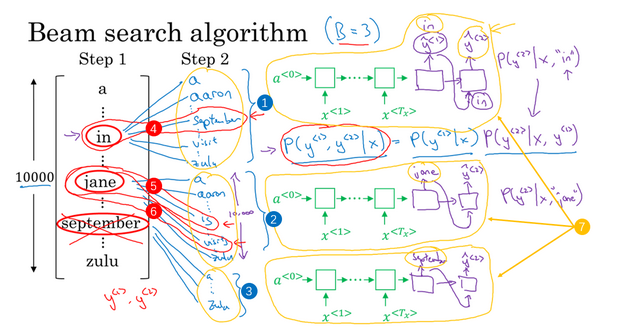
对于多个RNN(LSTM)输出我们怎么选择最重要输出的整句话呢?如果我们对每一个输出都选择最大概率,也就是贪心的思想,我们知道,贪心的结果并不一定是最优解(但是动态规划一定是哈哈哈哈哈哈)。
因此引入beam search。beam search(集束搜索)算法,目的是选择一个全局最优解(大部分情况是)。它通过定义一个B,集束宽,来定义对于每一个输出选择概率最高的B个输出,然后根据这B个输出分别计算下一个单词的概率(也就是假如词库中一共有1w个单词,这里计算1w*B个单词的概率),从这Bw个单词中继续选择前B个概率继续向下迭代。
为了防止下溢,我们将Beam search的公式定义如下:
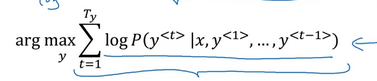
但是对于这个式子,对于很长的句子,由于乘了一个小于1的值,长句子的整体概率显然低于短句子,因此引入归一化操作,也就是除以句子单词数,来拟补这个差距。
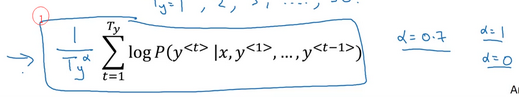
3.Beam search误差分析
对于引入beam search后的误差分析,我们可以将人类翻译作为一个基准,将人类翻译与网络翻译同时送入LSTM(RNN)中,如果RNN最终人类得分较低,则说明RNN网络有问题,需要对RNN进行调整,而如果人类胜出,则说明beam search有问题,需要调整beam search。
4.Bleu得分
Bleu是一个常用在机器翻译领域的评价指标。他通过统计n个长度的字符串在结果中出现的次数频率来统计得分

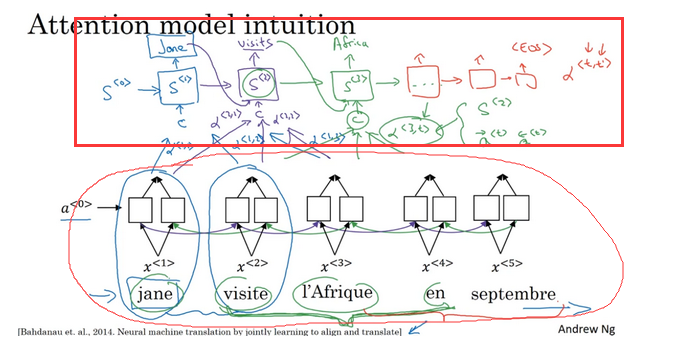
5.注意力机制
注意力机制的实质就是在RNN的输入端重新对n个长度的句子重新赋予权重,使当前位置的输出更(不)依赖某一个位置的输入。
简单理解为重新加一个比较小的神经网络。
测验
1. 想一想使用如下的编码-解码模型来进行机器翻译 , 这个模型是“条件语言模型”,编码器部分(绿色显示)的意义是建模中输入句子x的概率
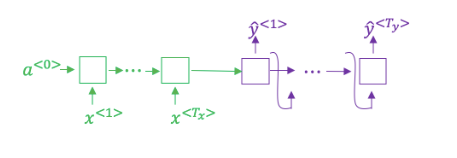
错误。
2. 在集束搜索中,如果增加集束宽度bb,以下哪一项是正确的?
- 集束搜索将运行的更慢。
- 集束搜索将使用更多的内存。
- 集束搜索通常将找到更好地解决方案(比如:在最大化概率P(y∣xP(y∣x)上做的更好)。
- 集束搜索将在更少的步骤后收敛。
1,2,3。
3. 在机器翻译中,如果我们在不使用句子归一化的情况下使用集束搜索,那么算法会输出过短的译文。
正确。
4. 假设你正在构建一个能够让语音片段x转为译文y的基于RNN模型的语音识别系统,你的程序使用了集束搜索来试着找寻最大的P(y∣x)的值y。在开发集样本中,给定一个输入音频,你的程序会输出译文y^= “I’m building an A Eye system in Silly con Valley.”,人工翻译为y∗= “I’m building an AI system in Silicon Valley.” 在你的模型中,P(y^∣x)=1.09∗10−7、P(y∗∣x)=7.21∗10−8那么,你会增加集束宽度B来帮助修正这个样本吗?
不会。
5. 接着使用第4题那里的样本,假设你花了几周的时间来研究你的算法,现在你发现,对于绝大多数让算法出错的例子而言,P(y∗∣x)≤P(y^∣x),这表明你应该将注意力集中在改进搜索算法上,对吗?
正确。
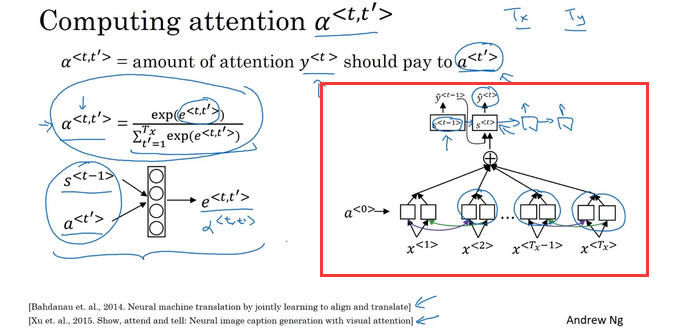
6. 下面关于 α<t,t’> 的选项那个(些)是正确的?
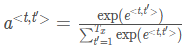
- 对于网络中与输出y<t>高度相关的 α<t′> 而言,我们通常希望 α<t,t′>的值更大。(请注意上标)
- 对于网络中与输出y<t>高度相关的 α<t> 而言,我们通常希望 α<t,t′>的值更大。(请注意上标)
- ∑tα<t,t′>=1 (注意是和除以t.)
- ∑t′α<t,t′>=1 (注意是和除以t′.)
1,4。
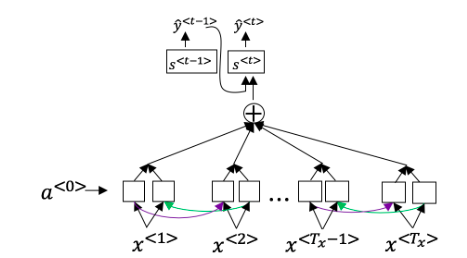
7.网络通过学习的值e<t,t′>来学习在哪里关注“关注点”,这个值是用一个小的神经网络的计算出来的:这个神经网络的输入中,我们不能将 s<t>替换为s<t−1>。这是因为s<t>依赖于α<t,t′>,而α<t,t′>又依赖于e<t,t′>;所以在我们需要评估这个网络时,我们还没有计算出st。
正确。
8. 与题1中的seq2seq模型(没有使用注意力机制)相比,我们希望有注意力机制的模型在下面的情况下有着最大的优势:
输入序列的长度Tx比较大。
9. 在CTC模型下,不使用”空白”字符(_)分割的相同字符串将会被折叠。那么在CTC模型下,以下字符串将会被折叠成什么样子?__c_oo_o_kk___b_ooooo__oo__kkk
cookbook
10. 在触发词检测中, x<t> 是:
时间t时的音频特
0 条评论