学习率的选择
首先是学习率,不要太高,不要太低,高了学不到东西,低了学习的慢。
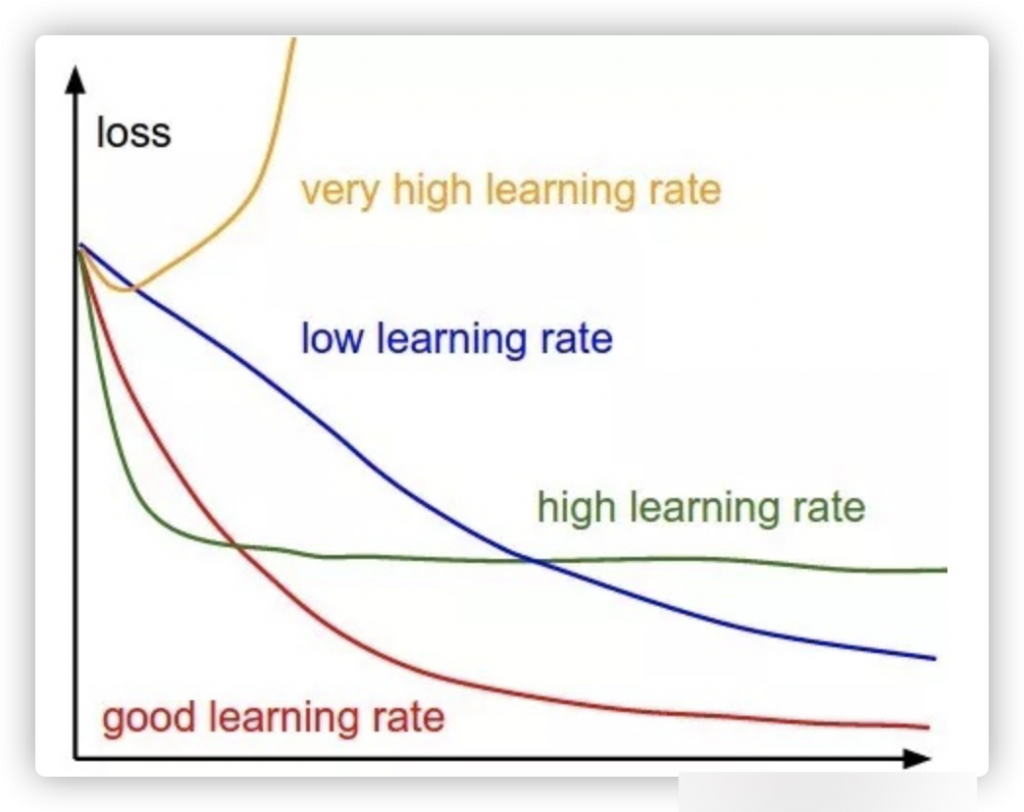
到这里仿佛什么都没有说,我们怎么确定一个比较合适的学习率呢?
我们通过从一个较小的学习率(比如1e-5[这个学习率在训练过程确实是小,但是对于微调过程,经验来看是一个比较适中的学习率]),让模型的每一batch使用不同的学习率,并记录loss,当loss有一个明显跌落时,就是一个比较合适的loss。
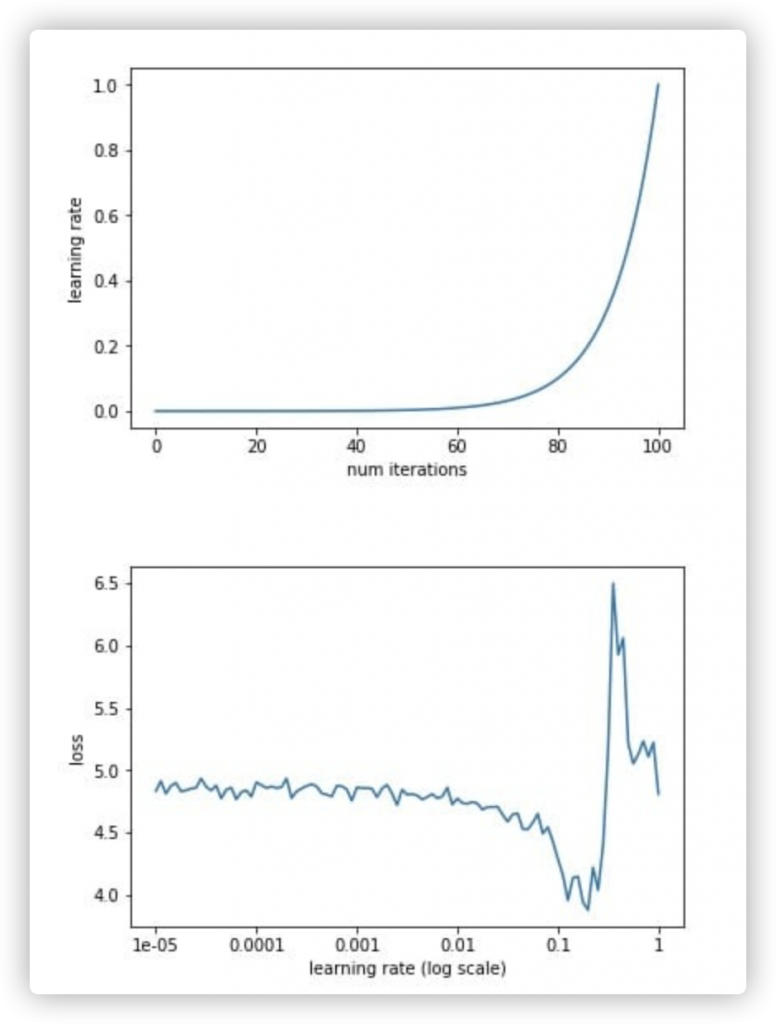
理由是,低学习率学习不到什么东西,loss平缓,高学习率会导致loss增长。
batch size的选择
对于batch size也有一个说了约等于没说的限制——不能太小,也不能太大。
我们知道,每一个batch内的数据会产生噪声(我们依赖于噪声来越过鞍点),而当batch size过小时,噪声相对前进方向较大,容易产生(loss)抖动的问题,没有办法收敛到最优值,甚至不会收敛。
而如果batch size较大,会导致训练次数的不足,使收敛的时间成本增加;如果过大甚至会影响模型收敛(不过这个“大”一般都要上千了)。
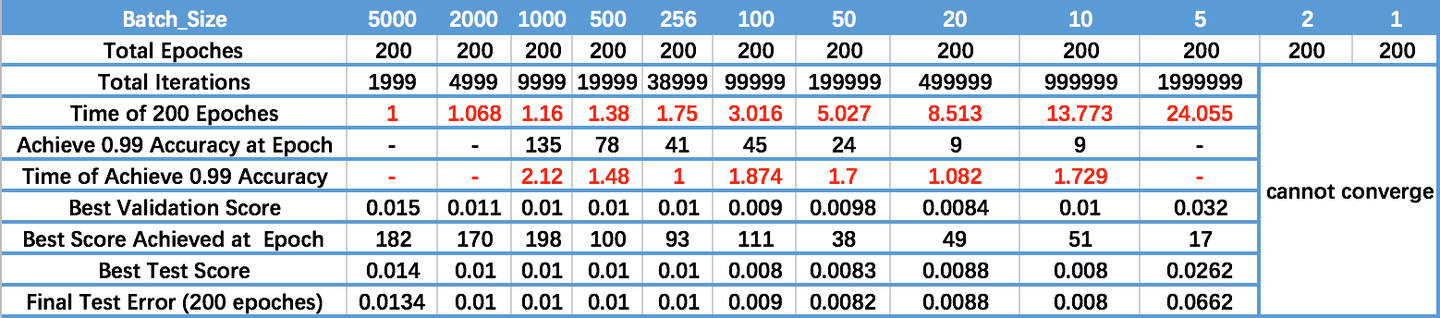
观察上图:
- 首先是batch为1和2时,模型无法收敛。
- 其次,从acc达到0.99的epoch来计算,可以看出,大batch size对应需要更多的epoch才能达到一个比较好的效果(因为需要更多的step)
- 最优的验证,测试集依然可以看出,小batch size的结果(比如5)似的模型并不能收敛到最优值;这个问题依然在极大的batch size中出现。
0 条评论