本章用来说明一些深度学习翻译(文本生成)任务中的几个指标。
BLEU和ROUGE可以说是基本上一摸一样了,区别就是BLEU只计算准确率,而ROUGE只计算召回率。
为了说明这两种评价指标,我们首先引入两段文字:
- 这花儿开的真美丽啊
- 这开的花儿真美丽啊
其中第二个为预测。
BLEU
这个算是比较古老的评价指标了,主要衡量文本翻译的准确率。
首先计算BLEU-1,我们需要将句子拆开
- 这 花 儿 开 的 真 美 丽 啊
- 这 开 的 花 儿 真 美 丽 啊
对于预测结果,9个字全部都在真实结果中出现,因此BLEU-1为9/9,同理:
- 这花 花儿 儿开 开的 的真 真美 美丽 丽啊
- 这开 开的 的花 花儿 儿真 真美 美丽 丽啊
对于BLEU-2,预测结果中有4个没有在真实结果中出现,分别为“这开 的花 儿真”,因此BLEU-2为5/8。
同理我们可知BLEU-3,BLEU-4均为2/7,1/6。
可以看出,低阶n-gram可以衡量准确性,而高阶n-gram可以衡量最终句子的流畅性。
当然,最终的BLEU并不是上述的值。
我们可以发现:如果模型总是预测很短的序列,那么就可以获得较高的BLEU分数,比如:
- 今天是个好日子,因为今天是中华人民共和国的国庆节。
- 中华人民共和国
对于下面的预测句,BLUE-1,2,3,4均为1。这显然不是我们想要的结果。
因此在BLUE中还引入了一个惩罚项,以惩罚这种预测句长度小于真实句的情况。
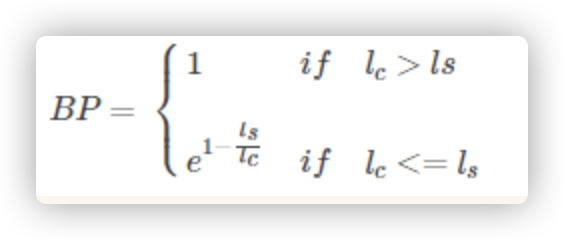
if hyp_len > closest_ref_len:
return 1
# If hypothesis is empty, brevity penalty = 0 should result in BLEU = 0.0
elif hyp_len == 0:
return 0
else:
return math.exp(1 - closest_ref_len / hyp_len)
我们将BLEU-1,2,3,4分别取对数然后求平均,然后取指数,就是最终的BLEU。
import math
from nltk.translate.bleu_score import sentence_bleu
log_avg = (math.log(9 / 9) + math.log(5 / 8) + math.log(2 / 7) + math.log(1 / 6)) / 4
bp = 1 # l_pred == l_true bp=1
print(math.exp(log_avg)) # 0.41535092372063953
r = sentence_bleu(
references=[list('这花儿开的真美丽啊')],
hypothesis=list('这开的花儿真美丽啊'),
)
print(r) # 0.41535092372063953
最终,句子的BLEU分数为0.42。
值得注意的是,虽然BLEU指标增加了长度惩罚项,但是效果并没有特别好,因此BLEU依然偏向于较短的文本评价。
ROUGE
BLEU是一个只看准确率的指标,而ROUGE是一个只看召回率的指标,整体流程来看,就是BLEU的比较对象发生了变化。
- 这 花 儿 开 的 真 美 丽 啊
- 这 开 的 花 儿 真 美 丽 啊
ROUGE-1为1,因为真实标签中 的每一个字都可以在预测结果中找到。
- 这花 花儿 儿开 开的 的真 真美 美丽 丽啊
- 这开 开的 的花 花儿 儿真 真美 美丽 丽啊
ROUGE-2为5/8,因为真实标签中的“这花 儿开 的真”不在预测结果中。
可以看出,相比BLEU只是比较对象变了,YX变成了XY。
ROUGE-L相对有一些变化,L代表LCS,最长公共子串。
公式为:
r_lcs = llcs / m
p_lcs = llcs / n
f_lcs = 2.0 * ((p_lcs * r_lcs) / (p_lcs + r_lcs + 1e-8))
其中,llcs为最长公共子串长度,m,n分别为两个句子的长度。
例如:
- 这花儿开的真美丽啊
- 这开的花儿真美丽啊
的最长公共子串长度为为7(这花儿真美丽啊(XY)或 这开的真美丽啊(YX))。因此r_lcs/p_lcs 为 7/9 f_lcs为2*7/18 = 7/9.
因此,ROUGE-L为7/9。
from rouge import Rouge
rouge = Rouge()
r = rouge.get_scores(
hyps=' '.join(list('这花儿开的真美丽啊')),
refs=' '.join(list('这开的花儿真美丽啊'))
)
for k, v in r[0].items():
print(k, v['r'])
#output
rouge-1 1.0
rouge-2 0.625
rouge-l 0.7777777777777778
由于ROUGE并不检查连贯性,因此ROUGE对于语义连贯性较差的模型以及任务(比如使用机器学习进行文本翻译)不太友好,对于深度学习类的任务(这类模型生成结果往往有较好的语义连贯性)较为友好。
0 条评论