这篇文章讨论binary_crossentropy、(sparse)categorical_crossentropy的区别 还有 sigmoid和softmax 的区别
首先定义简称:
- binary_crossentropy:BCE
- categorical_crossentropy:CE
- sparse_categorical_crossentropy:SCE
在这里我们还要和激活函数一起说——这也是为什么要写这篇笔记的原因。
首先我们先对比sigmoid和softmax这两个激活函数
这两个激活函数之所以能被比较,只有一种情况下可以被比较——那就是二分类任务。
- 使用单节点输出,sigmoid激活
- 使用双节点输出,softmax激活
(使用双节点输出sigmoid激活放到后面说)
那么在这种情况下我们应该怎么选择激活函数呢?
首先看两个激活函数的公式:
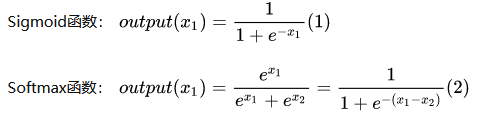
我们可以看出,两个激活函数在二分类任务中,并没有什么区别,那实际使用中呢?
其实这两种方式对于分类结果来说没有任何区别(理论上),因为都可以用过设定阈值来获取到正确的分类结果。
但是,由于pytorch和tensorflow等框架计算矩阵的方式,导致两者在反向传播过程中还是会产生差别。实验表明,对于不同的分类模型,两者都有自己的优势区间——也就是不一定哪个好。
但是我们需要注意:对于上面提到的组合虽然各有各的好,但是对于:
- 使用双节点输出,sigmoid激活
- 使用双节点输出,softmax激活
来说,二者具有不同的现实意义
- sigmoid 说明 为1的概率为xx,不为1的概率为yy。
- softmax说明 为1的概率为xx,而不为1的概率为(1-xx)[因为softmax和为1]
简单来说,sigmoid并不保证xx+yy=1,这和我们现实中的想法并不统一。
而softmax保证了和为1。
至于在双节点的时候使用sigmoid还是softmax,这要看具体情况,一般来说,NLP任务中softmax效果较好,而CV任务中sigmoid效果较好。
然后我们对比损失函数
BCE、CE、SCE,首先BCE的binary,我们就可以知道BCE主要用于二分类,而CE、SCE主要用于多分类。
CE和SCE又只差了一个 sparse[稀疏],因此,它俩其实没有什么太大区别,只是CE传入one hot标签,而SCE可以直接传入数字标签。
最后我们结合损失函数和激活函数一起进行一些说明
BCE和CE的对比:
两个损失函数的公式如下:
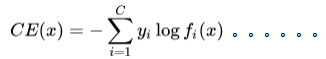
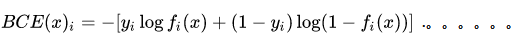
一般,我们认为二分类使用BCE,而多分类使用CE。
在二分类场景下,我们一般使用sigmoid+BCE的组合(单输出),作为对比,我们对比sigmoid+BCE 和 sigmoid+CE。
在这种情况下,CE的损失函数为:
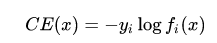
可以很明显的看出来,当y为0时,损失函数为0。这就意味着,当样本为0时,模型没有办法正确学习(也就是说,CE的核心是学习正样本,然后通过softmax抑制负样本的值),因此:
由于使用了单节点,CE没有办法学习负样本,只能是随机输出,而正样本的准确率(precision)会很高。
我们使用imdb进行测试:
运行200个step后,binary_crossentropy已经明显收敛:
20000/25000 [==>......] - ETA: 1:53 - loss: 0.5104 - acc: 0.7282
而categorical_crossentropy却收敛缓慢:
20000/25000 [==>......] - ETA: 1:58 - loss: 5.9557e-08 - acc: 0.5005可以验证这个猜想。
而事实上,tensorflow已经禁止在单输出的时候使用CE。
0 条评论