本文来自Goggle的论文 ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generator
相比Bert,ELECTRA采用了更优秀的mask方法以及训练目标。
1.更优秀的MASK
bert的mask是随机的,比如“我想吃苹果”,很可能mask的结果是“我想吃苹MASK”,对于语言模型来说,预测“果”是很容易的。
但是对于“我MASK吃苹果”可能预测“想”的难度就会很大了。
因此ELECTRA引入了一个小型MLM语言模型作为生成器(Generator),用来完成那些“简单”的MLM任务。同时对于“较难”的MLM任务,由下游的判别器(Discriminator)来进行判断,哪些是替换或的token。
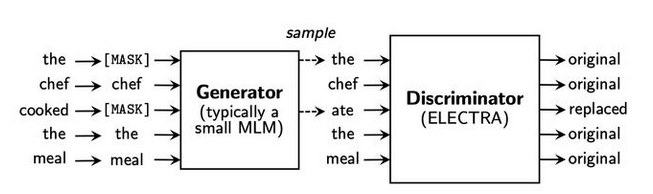
2.训练目标
训练目标当然可以和Bert相同,根据是否变化对应Bert中MASK的替换和不变。
但是ELECTRA不一样就不一样在他更换了训练目标。
如上图,使用一个二分类去判断每个token是否被换过。这就把LM任务转换为了序列标注(分类)任务。也就带来了两个好处:
- 每个token都能有一定的贡献( contribute to some extent )
- 缩小了计算量(相比预测token,二分类计算量小多了)
在训练过程中,判别器的loss不会反向传播到生成器,在pre-training之后,我们只使用 判别器 进行fine-tuning. ( 两者同时训练,但判别器的梯度不会传给生成器 )
然后在微调的过程中舍弃生成器即可。
从论文代码上来说,判别器和生成器都是Transformer based,也就是都是类bert结构的(甚至代码里直接使用了Bert相关变量)。
0 条评论