既然已经有了【深度学习笔记】Attention和self Attention的联系和区别,为什么这里要再开一篇来讲self-attention呢?
因为这篇文章主要是用来推翻自注意力机制的。
其实深度学习一直有一个问题就是黑箱,并没有很具体的可解释性,虽然近年来做了很多网络可解释的工作,比如图片识别方向的CNN可视化等等,但是可解释性依然比较差。
在这里面自注意力机制又是一个相对来说可解释性比较强的一个模型了,它通过自己与自己的attention来自动捕获token和token之间的关联。甚至《attention is all you need》 论文中也给出了一个比较合理的可视化结果。
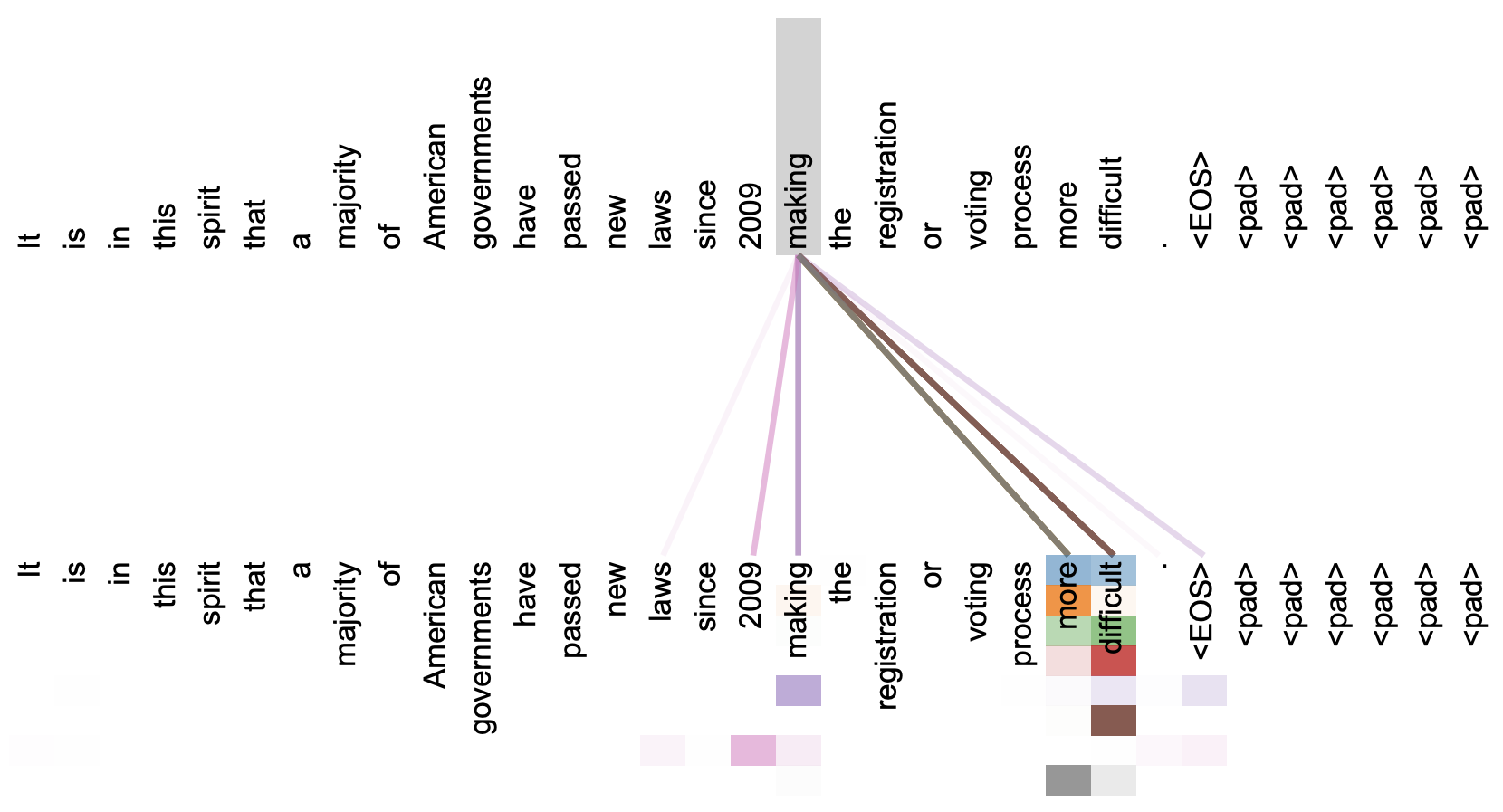
但是事实真的是这样的吗?
前不久谷歌的新论文ICML2021《Synthesizer: Rethinking Self-Attention in Transformer Models》让我们开始对这个想法是否科学开始有了一定的怀疑。
对于注意力机制,可以查看之前在 【深度学习】Transformer中对多头注意力机制进行的描述。
而谷歌在这篇论文上做了一个实验,那就是
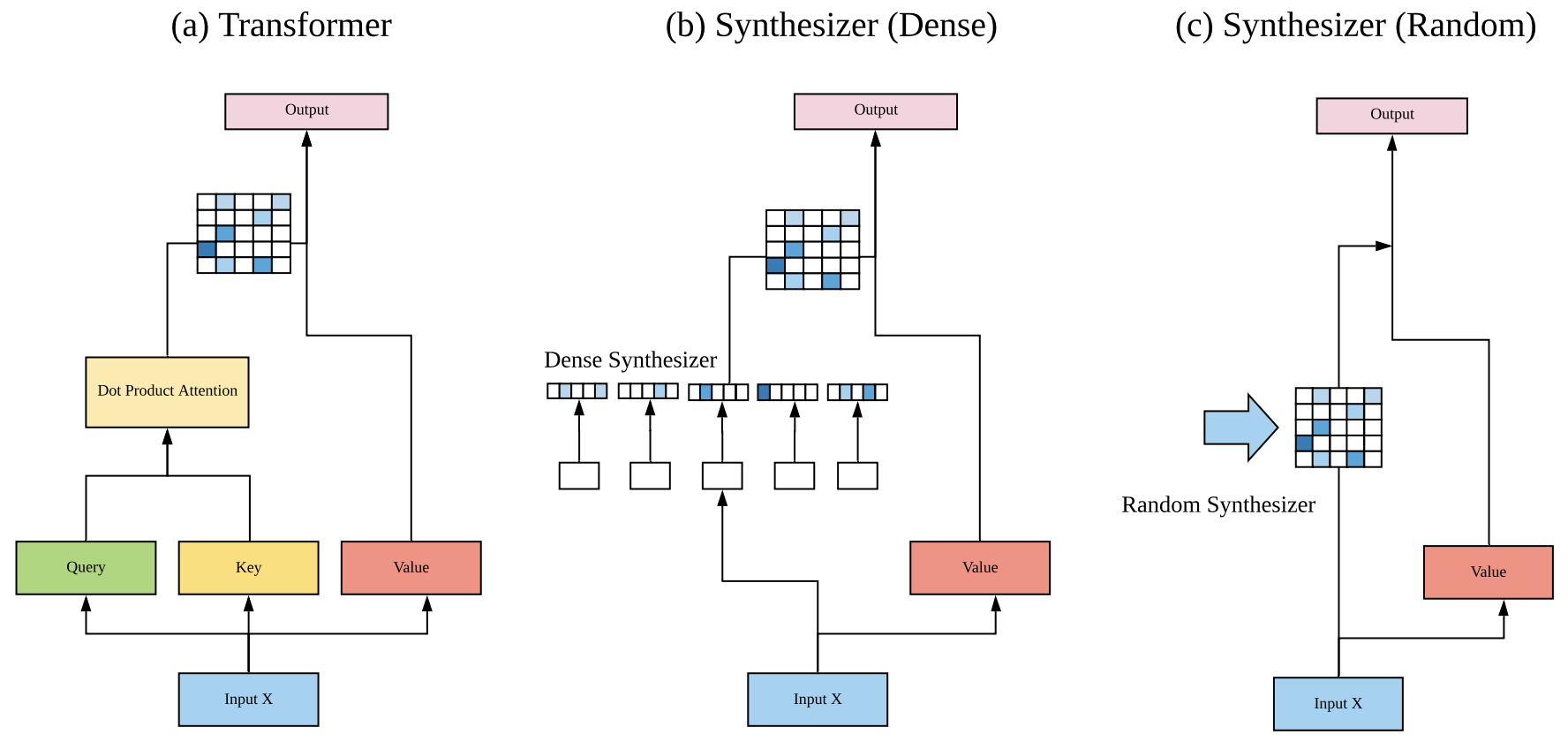
最左边这个就是一个最基础的注意力机制,是通过qk计算一个注意力矩阵,然后和v相乘输出一个结果。
而问题就是,这个矩阵真的是“有道理”吗?
谷歌在这篇论文中尝试了两个其他方法来生成这个矩阵。
分别是:使用dense来训练这个矩阵(中间那个)和随机初始化(右边那个),来验证我们通过qv的相乘最后生成的注意力矩阵到底是不是“科学”的。而这些模型统称为 Synthesizer。
dense
对于使用dense来训练,其实就是通过一个矩阵将输入变换为“注意力矩阵”。
原文中使用了两层Dense来做这一个工作
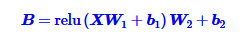
其中:X是输入,W和b为dense权重。
random
而random则更加异想天开,直接随机初始化这个矩阵(当然也可以选择训练和不训练)。
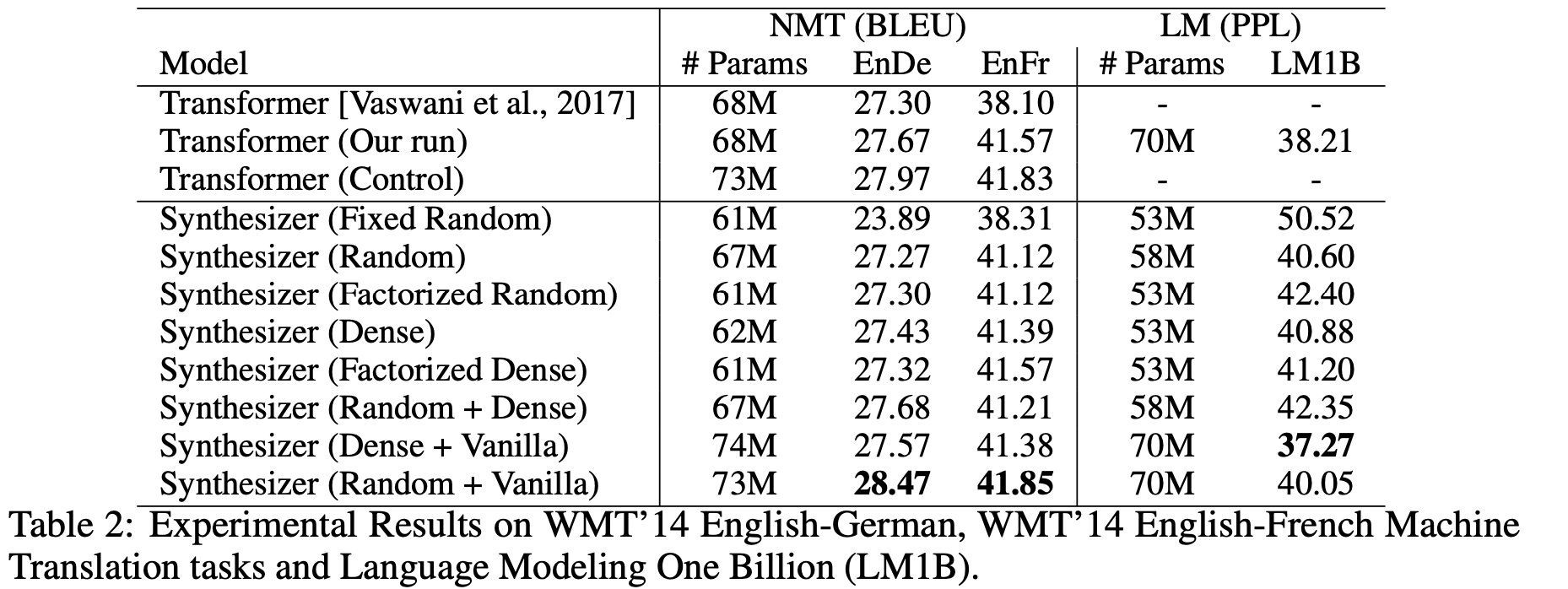
那么效果咋样呢?实验结果让我们大跌眼镜。
结果表明,多任务的多实验结果,除了冻结ramdom(fixed random),其余的自注意力结果都差不多。

预训练+微调
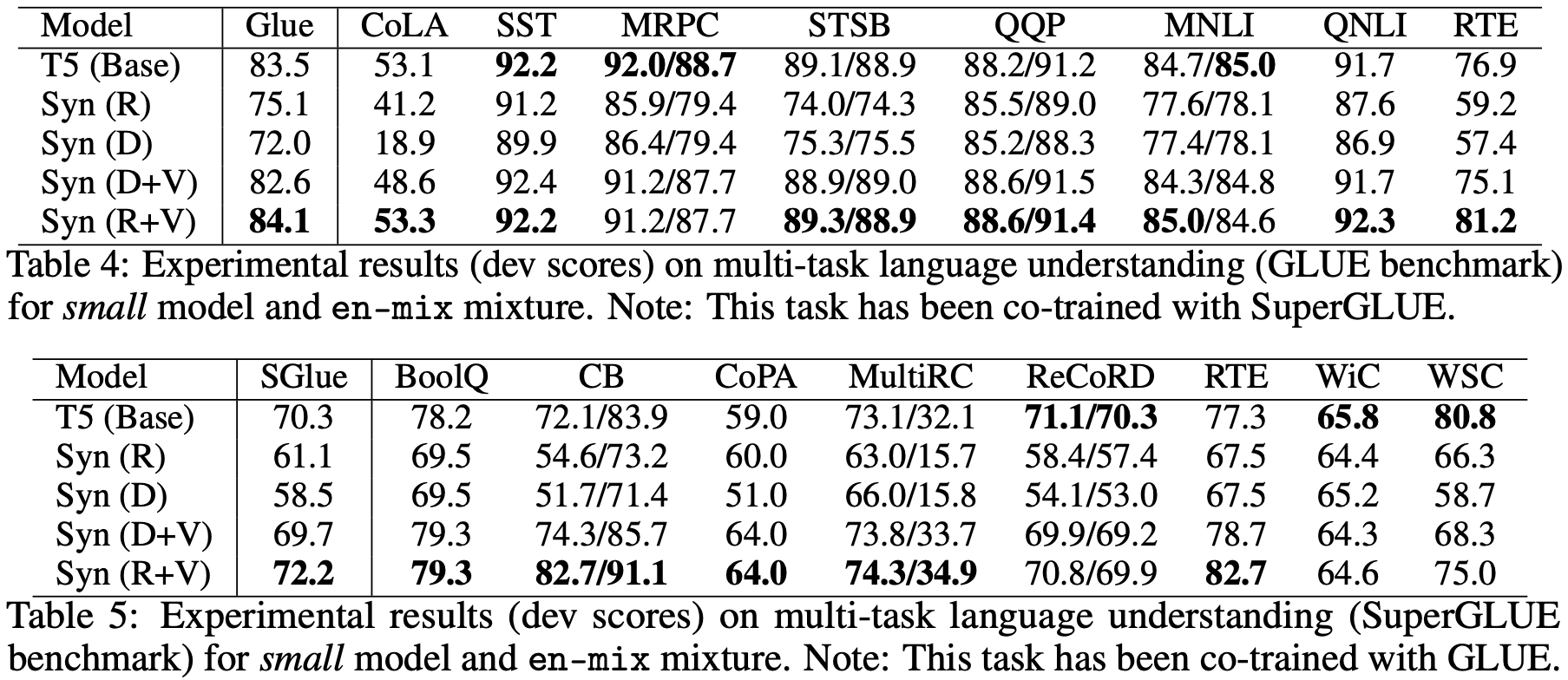
在这个结果,使用D和R的自注意力就会相对逊色了,这表明D和R的迁移能力较弱。
但是不可否定,由于省去了矩阵计算的过程,运算效率会显著提升,也就是如果解决了迁移的问题,Transformer家族或将赢来大换血。
2 条评论
刘喆 · 2025-03-09 12:32
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0
我个人认为self-attention机制现在优化的方向应该是用数学中的最优化理论、信息论证明其收敛性,有的时候深度学习缺乏可解释性的情况好多在于实验结果和理论证明对不上。
Sniper · 2025-09-25 11:55
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36
其实self-attention是后补的理论。先证明有效再补理论。但是目前看着qkv从各种可解释上来看,还是挺合理的。特别是随着模型scaling起来,很多实验结论跟一开始的“假设”基本是一致的