什么是注意力?
当人类观察一张图片或者一段文字时,可以将重点放到某一部分,从而可以更好的处理图中或文字中的信息。
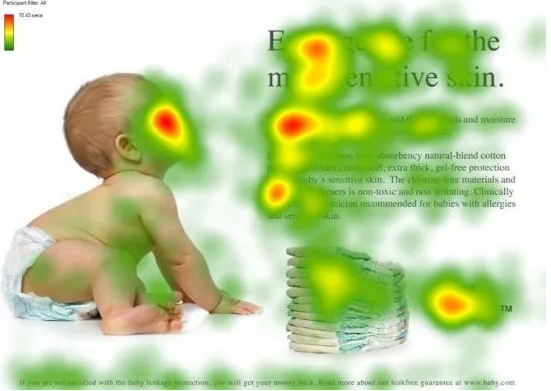
如果我们在神经网络中也使用类似机制,可以让网络更好的获取上下文信息,从而获得更好的效果。
Attention
最先出自于Bengio团队一篇论文:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE ,论文在2015年发表在ICLR。
Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射 。
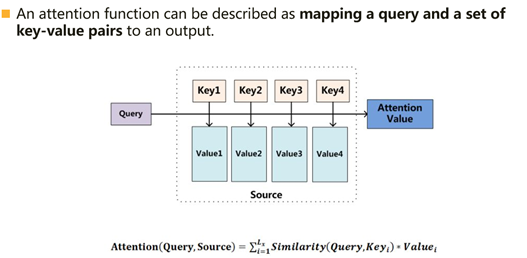
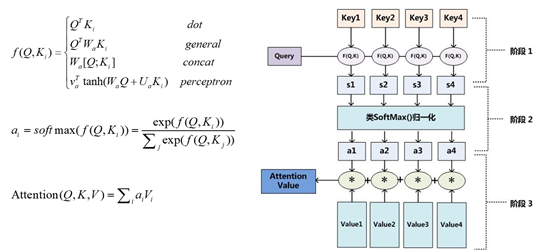
在计算attention时主要分为三步,
第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;
第二步一般是使用一个softmax函数对这些权重进行归一化;
第三步将权重和相应的键值value进行加权求和得到最后的attention。目前在NLP研究中,key和value常常都是同一个,即key=value 。
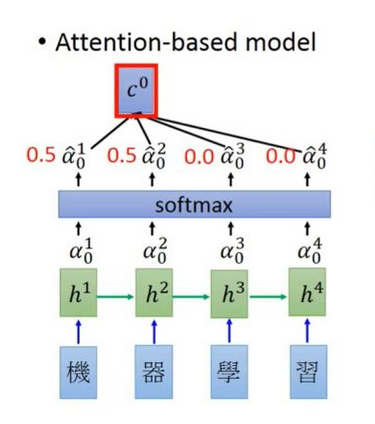
Attention机制发生在Target的元素Query和Source中的所有元素之间。
比如entity1,entity2,entity3….,attn会输出[0.1,0.2,0.5,….]这种,告诉你entity3重要些。
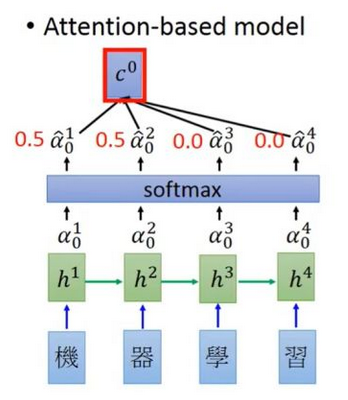
self attention
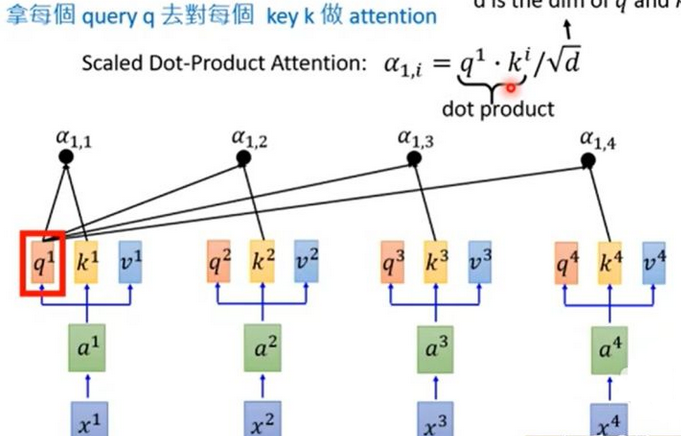
self attention会给你一个矩阵,告诉你 entity1 和entity2、entity3 ….的关联程度、entity2和entity1、entity3…的关联程度。
它指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。Q=K=V。

总结
attention和self attention 其具体计算过程是一样的,只是计算对象发生了变化而已。
attention是source对target的attention,
而self attention 是source 对source的attention。
其他链接:
0 条评论