数据
使用了3T token
数据采用了和slimpajama类似的做法,去重:标准化、minihash、LSH。质量:启发式和模型(模型ppl、文本质量评分、冒犯识别、不当内容识别)筛。同时对于低质量来源进行数据采样,最终得到3Ttoken。
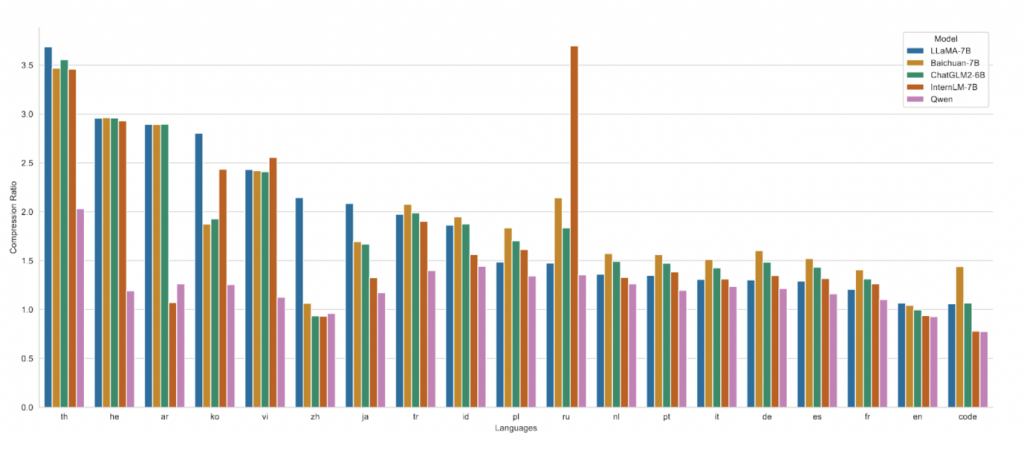
tokenizer
词表在GPT-4使用的BPE词表cl100k_base基础上,对中文、多语言进行了优化。 词表对数字按单个数字位切分。最终有151851。
结构
结构和llama一样,RoPE、SwiGLU、RMSNorm。
去掉了大部分层的bias,但是为了保留外推能力,留下了qkv的bias。
训练
预训练
AdamW 0.9& 0.95 和baichaun2一样。
不过使用了cosine学习衰减,到最大学习率的10%。
也是bf16,不过没有提到warmup。
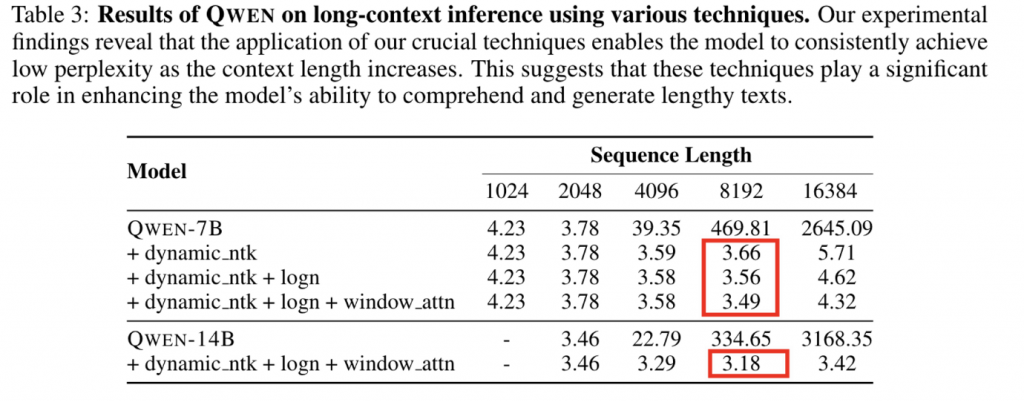
通过使用NTK感知和logN 缩放(苏建林),模型在8096长度下依然具有较为不错的能力。
sft
观察到数据格式能够显著影响模型性能,使用OpenAI的ChatLM风格,这种格式使模型能够有效地区分各种类型的信息,包括系统设置、用户输入和助手输出等。通过利用这种方法,我们可以增强模型准确处理和分析复杂对话数据的能力。
ChatML Format:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|> user
Hello! <|im_end|>
<|im_start|> assistant
Hello! How can I assist you today?<|im_end|>
有点类似于baichuan2的user token 和assistant token,不会出现在预训练中,是保留字段,但是这里的区别是还会有显式的角色信息(system、user。。)
1420步,warmup到2e-6(学习率好低),总计4000step,batch size 128。(也只是百万级别的sft,Baichuan是100k,看起来大家sft的数据都不多)。
工具调用
sft的工具调用能力是通过类似于self instruct,通过初版Qwen,self instruct输出、筛选、迭代。最终获得2000条左右具备工具调用的高质量数据。混合其他通用数据进行训练。
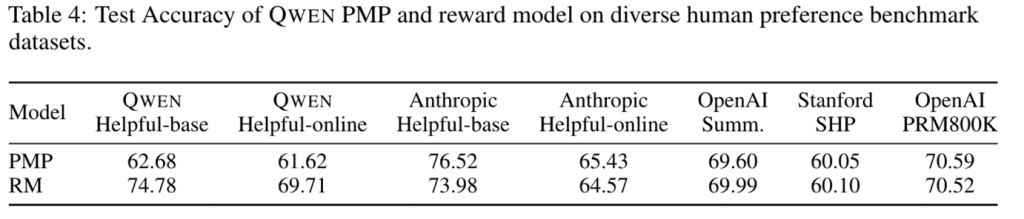
RM
RM model 使用的依然是Qwen的output,这一点应该是大家的公示,rm model和base model应该同源。(但是使用了不同大小的Qwen和使用了不同的解码策略)。
• 参考Anthropic,先在较糙的数据上预训练RM(StackExchange、Reddit等),再用质量好的数据精调(from rumor)Training a helpful and harmless assistant with reinforcement learning from human feedback: *https://arxiv.org/pdf/2204.05862.pdf*

训练数据的prompt体系做的很全,6600个标签,确保多样性和复杂度
RLHF
PPO 不太懂,存档
from rumor:
- critic model warmup 50,百川也是相同的做法
- RL训练阶段每个query采样两个答案,作者说这样效率会更高(意思是这两个答案都会计算奖励值然后强化?)
- 用running mean进行奖励归一化
- value loss clipping,提升RL稳定性
- actor 采样top-p=0.9,发现可以提升评估效果
- 用ptx loss来缓解对齐税,用的预训练数据需要比RL数据多很多,但不好调节,系数大了影响对齐,小了又没效果
最终,在300条评估集上,RLHF后的模型在知识、理解、写作、Math、Coding都有提升,有的能力提升还挺大(颜色由深到浅分别是wins、ties、losses):
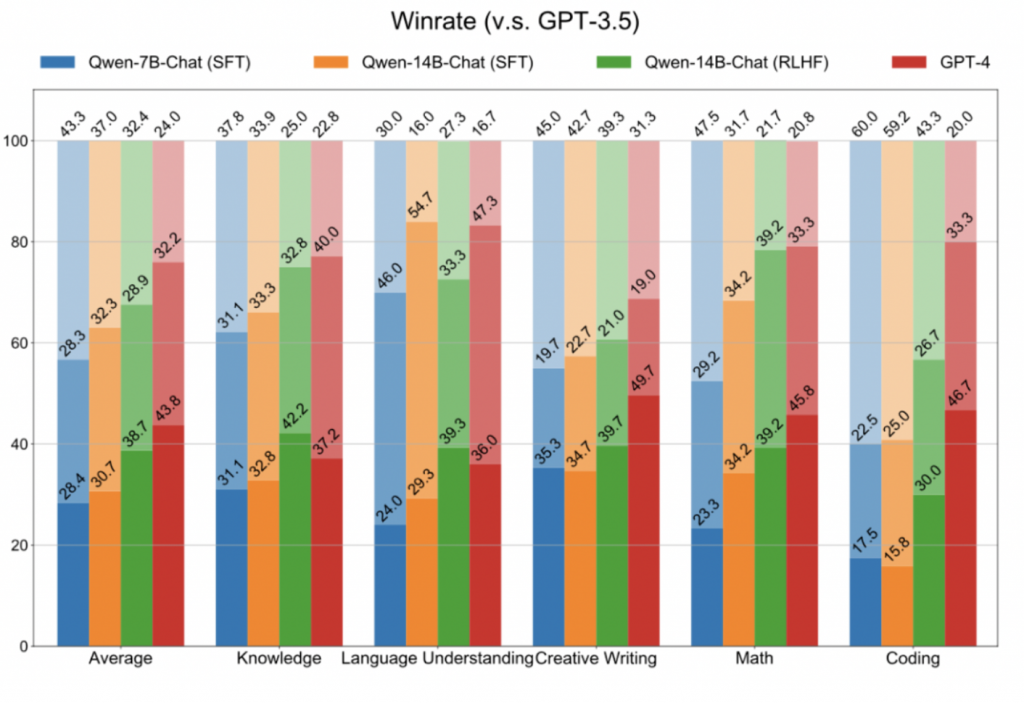
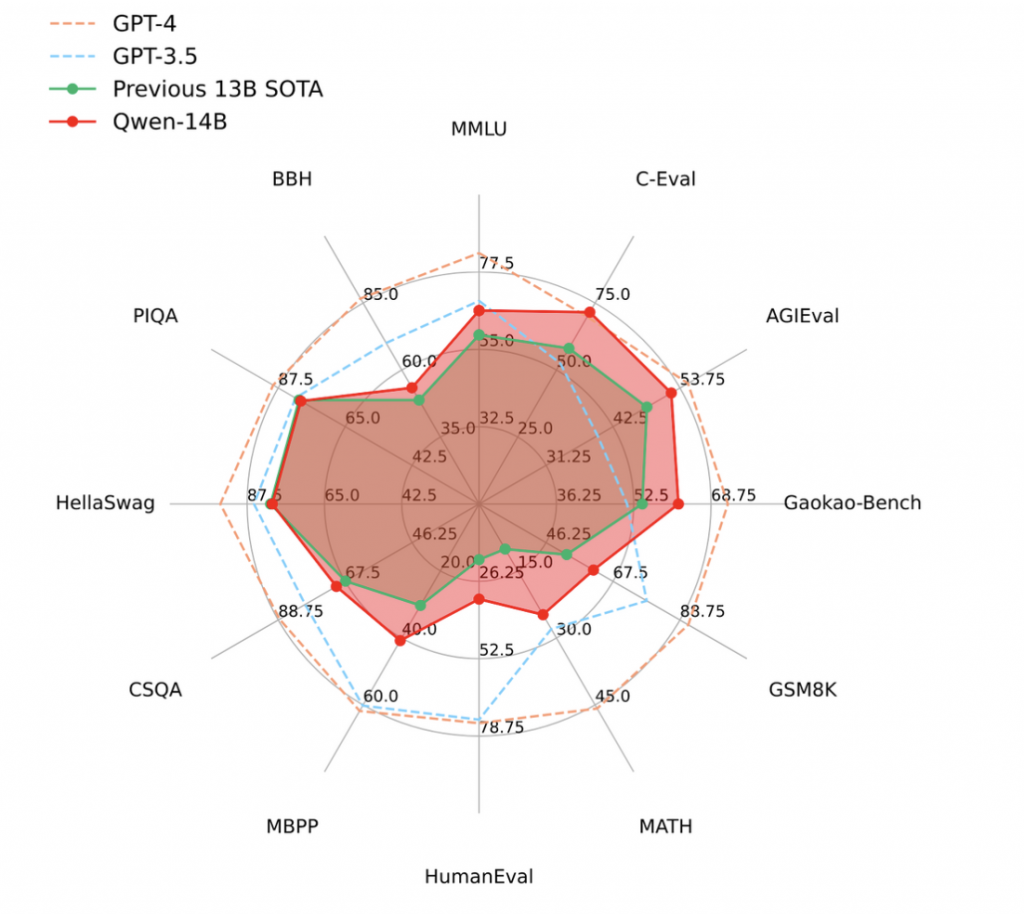
测评
整体测评:
引用
1.https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf
0 条评论