跟随slimpajama一起出现的一个模型,主要是验证slimpajama的有效性,效果比一些7B的模型要好。不过由于论文时间比较久,所谓的比7B的好很可能效果也没有那么好。
结构
SwiGLU、ALiBi
Dmodel:2560、nlayer:32、nhead:80、Dffn:6828 total:2.6B
训练
采用两阶段训练,
第一阶段使用470B token,长度2048,batch size 1920.
第二阶段采用157B token, 长度8192,batch size 480.
AdamW,0.9&0.95&1e-8
梯度裁剪1,
训练数据
过滤了redpajama的1.2T数据,数据处理代码为:https://github.com/Cerebras/modelzoo/transformers/data_processing/slimpajama.
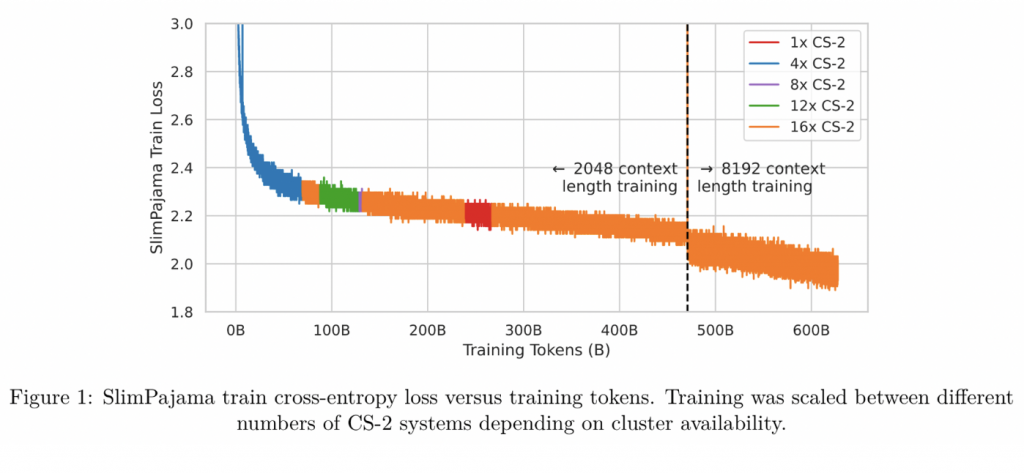
loss
经历过2次loss突增,分别是15step的时候和刚切换到8192长度的时候。但是并没有影响后续loss的下降。
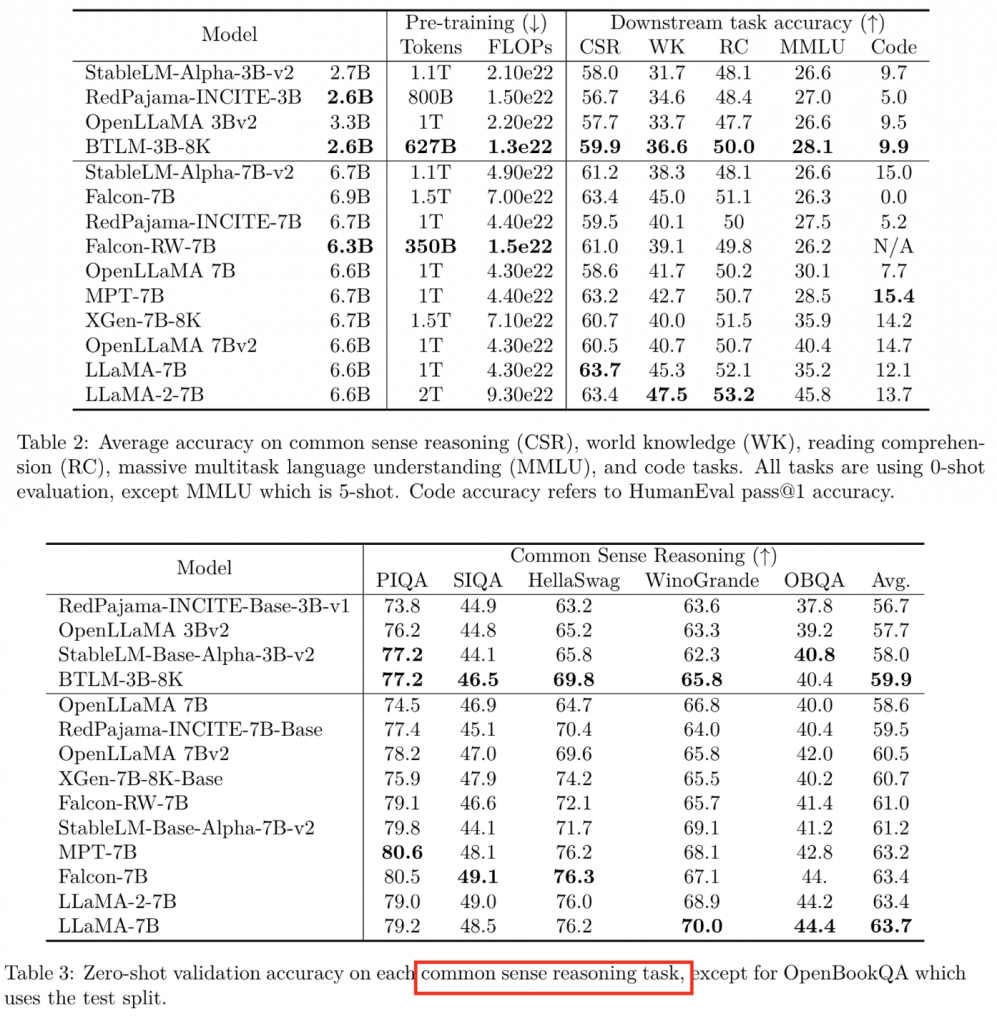
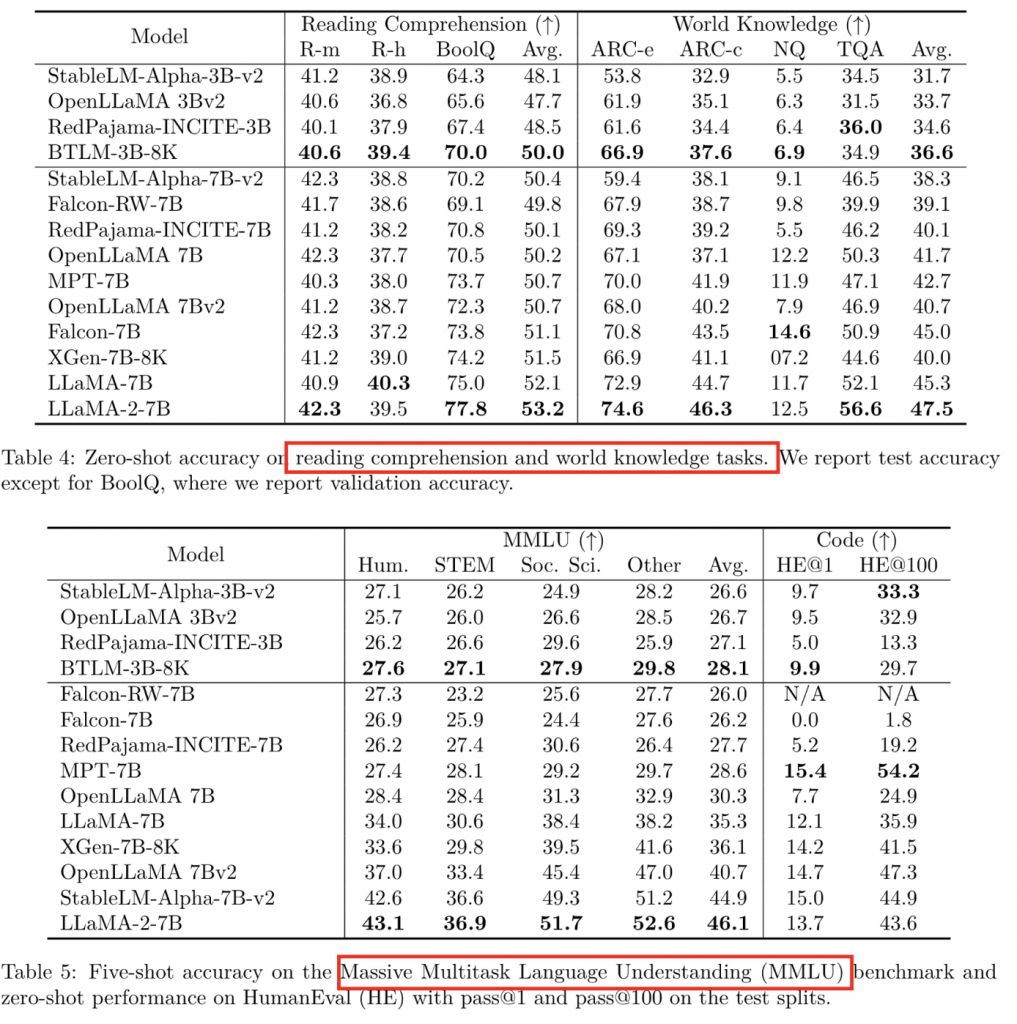
evaluate
文本长度与位置编码
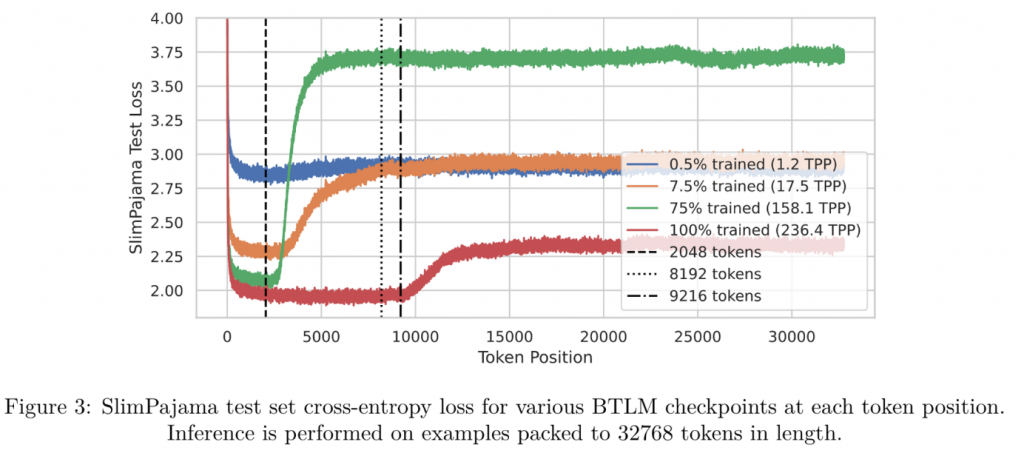
TPP(token per parameter)
ALiBi论文中,说明外推性很好的实验是使用了103M数据训练了一个255M的模型,tpp仅有0.4。
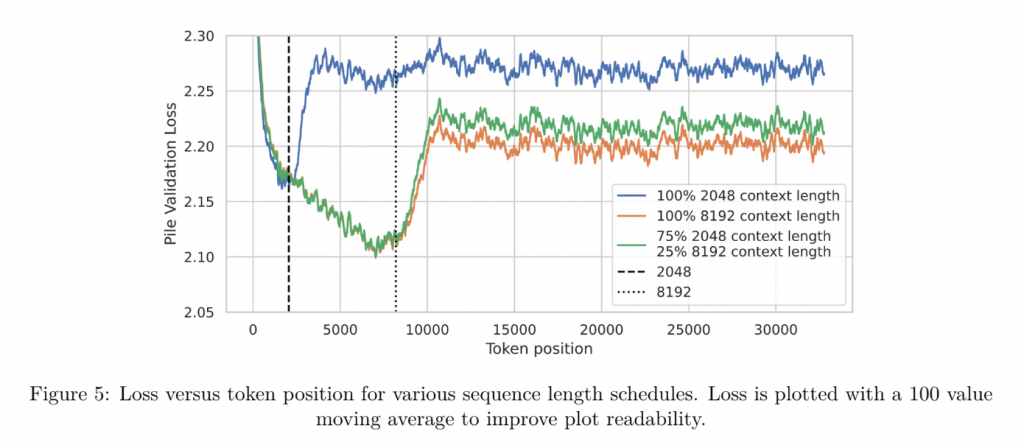
通过分析不同checkpoint(不同tpp)时,不同文本长度的loss,最终发现在1.2tpp时确实文本长度增加loss没有明显变化,但是这是建立在模型整体训练质量很差的情况下,而在完全训练结束的75%时(后面25%切换到了8192长度),模型对超长文本的loss突增。
说明在一定程度上,随着模型训练的继续,模型会“过拟合”当前的文本长度。
因此也就不存在ALiBi的外推性更权重好这一结论。
消融实验
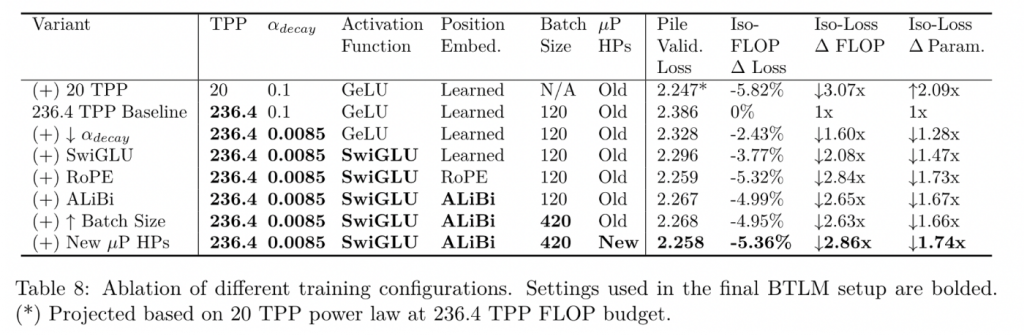
权重衰减
找到了一个权重衰减公式,比如20TPP需要0.1的衰减率,240的TPP需要0.1*1/12=0.0083。
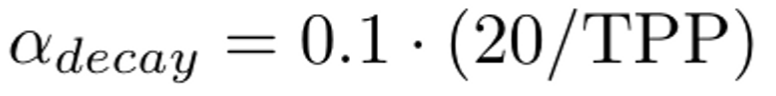
如果违背这个公式,需要多计算1.6x的FLOP。
位置编码
相比ALiBi,RoPE在2048长度下拥有更优秀的表现,但是ALiBi在最终的8k模型loss还会下跌1.26%
8192文本长度
采用两阶段长度训练,可以节省资源,也是业内大部分的做法。效果还很接近。
0 条评论