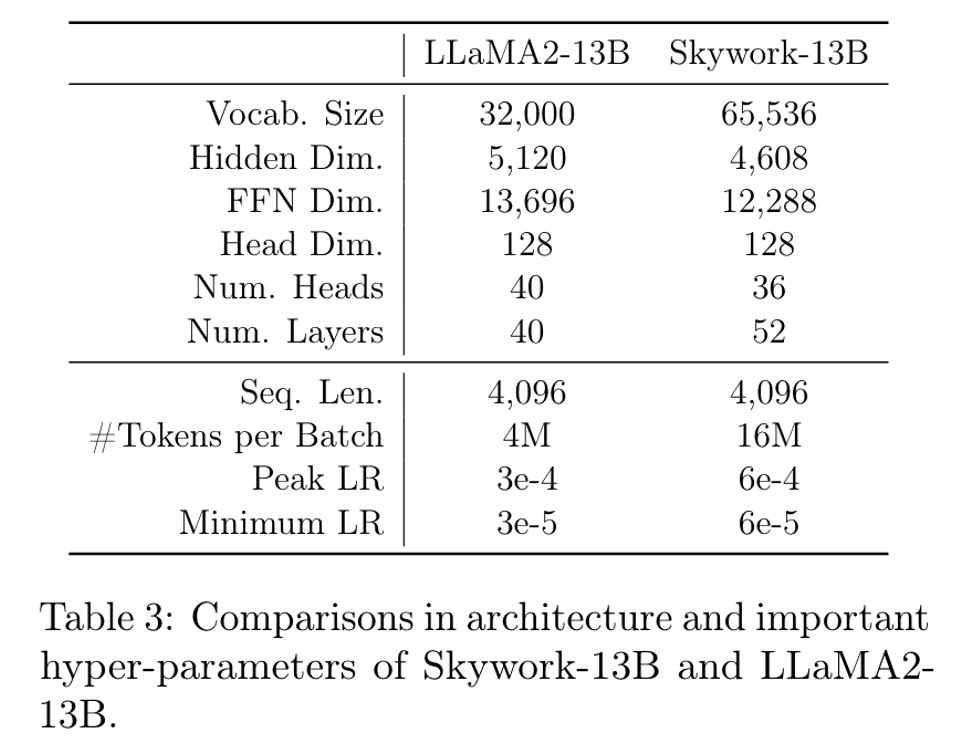
模型结构
使用了RoPE,RMSNorm和SwiGLU。
整体结构和llama类似,也看得出来整体技术报告处处对比llama,应该是跟随llama的一个工作。不过比llama2更加的“细长”,增大了layers,缩短了num_head。
tokenizer
tokenize也是浓浓的llama风。包含了llama的32000个token。由于llama不支持中文,因此将bert-chinese的8000个token添加进来,同时又添加了25k个中文高频词组,最后又17个保留字(不过这个保留字真少啊,baichuan2可是留了几千个保留字,不知道是不是为多模态做准备)。最终词表总大小65536。
数据构成
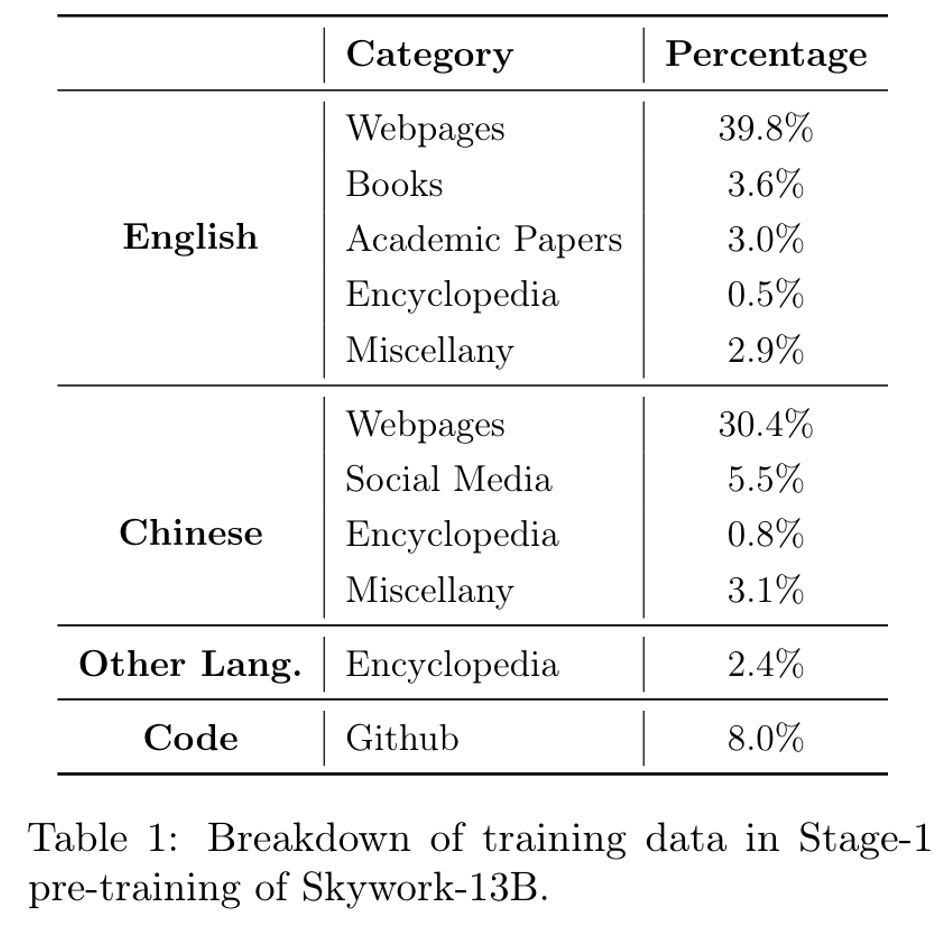
创建了一个SkyPile数据集,包含了6T的token。其中150B的web数据已开源。
所有的数据经过以下几个步骤:
- 格式提取:解析html页面等结构
- 分布过滤:认为传统的给数据打标签这件事可能有问题,因为一个数据集很可能被多个标签标记,因此本文先embedding化再聚类,从而对文本进行降重。(PS:那不还是标签那套?只不过不是显示的分类任务而是聚类任务?)
- 去重:这一步没什么好说的。
- 质量过滤:这一步本来也没什么好说的,但是本文另辟蹊径的分类目标挺有意思的。训练二元分类器做文本质量筛选本身很正常,但是本文将高质量定义为“是否合适作为百科的引文”。这样因为标签文本获取容易,因此就多了很多训练数据,增加了数据的多样性。效果应该会有奇效。
同时,对于代码文本,本文没有去掉json、yaml等文件,而是保留了一部分。
同时为了保证模型的中英能力,还有一个质量极高的中英文对齐预料。
最终的skywork-13b 在6T数据中采样了3.2T作为训练数据,其中一些高质量数据例如百科,重采样了5次。整体的数据分布如下:
首先是创建了2个数据集,分别是skywork-main和skywork
训练细节
使用512张A800,基于Megatron-LM框架,训练了39天,平均运算速度175TFlops。
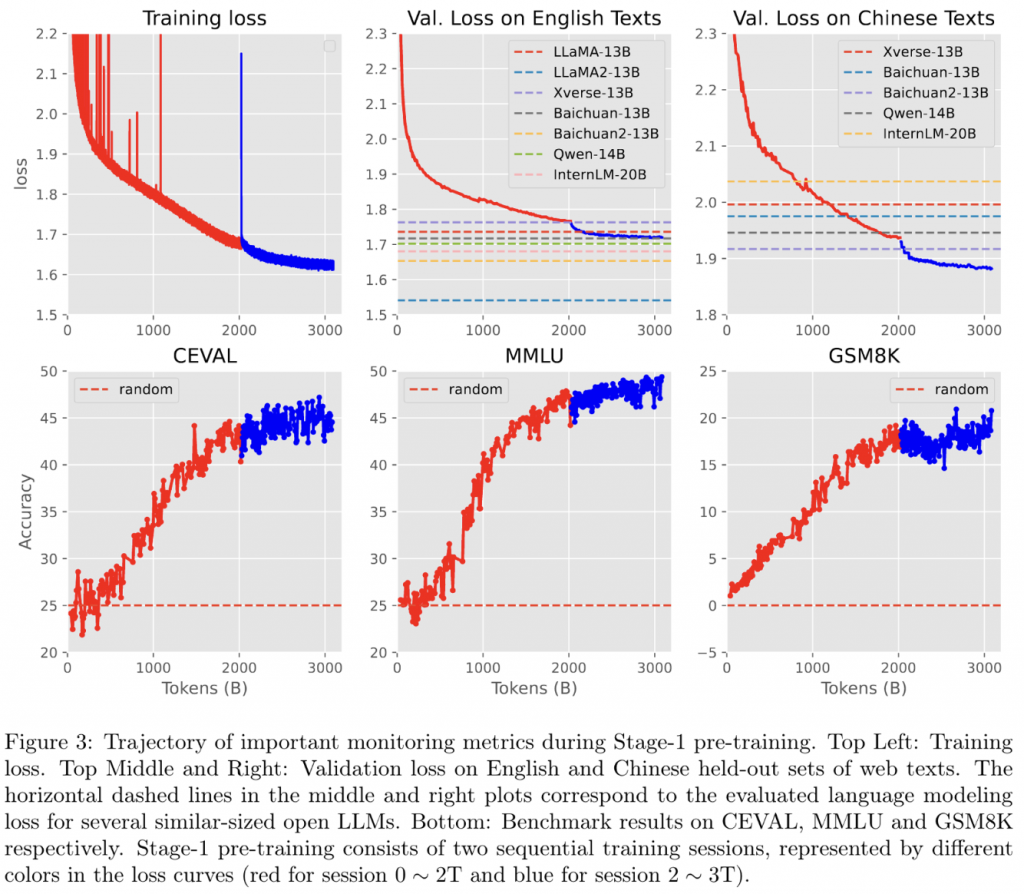
训练分为三个阶段(论文说2个阶段,但是我认为实际上是三个阶段),其中第一阶段包含2T token。 在这个范围内,使用cosine的学习率,从6e-4调度到6e-5。
一开始只计划训练2T token,不过在训练时发现模型loss下降依然明显,容量似乎还够,因此添加了第二段1T数据(不过原论文认为这属于第一段中的一部分)。
第二段使用了6e-5的恒定学习率继续训练。同时继续进行预训练(不过由于一些数据来源用完了,做了一些数据分布变化)
对于第二阶段的学习率也进行了很多尝试,最后发现似乎在低学习率下会有不错的表现。不过这里似乎也启发一点,就是continue pretrain需要一个相对较低的学习率进行学习。
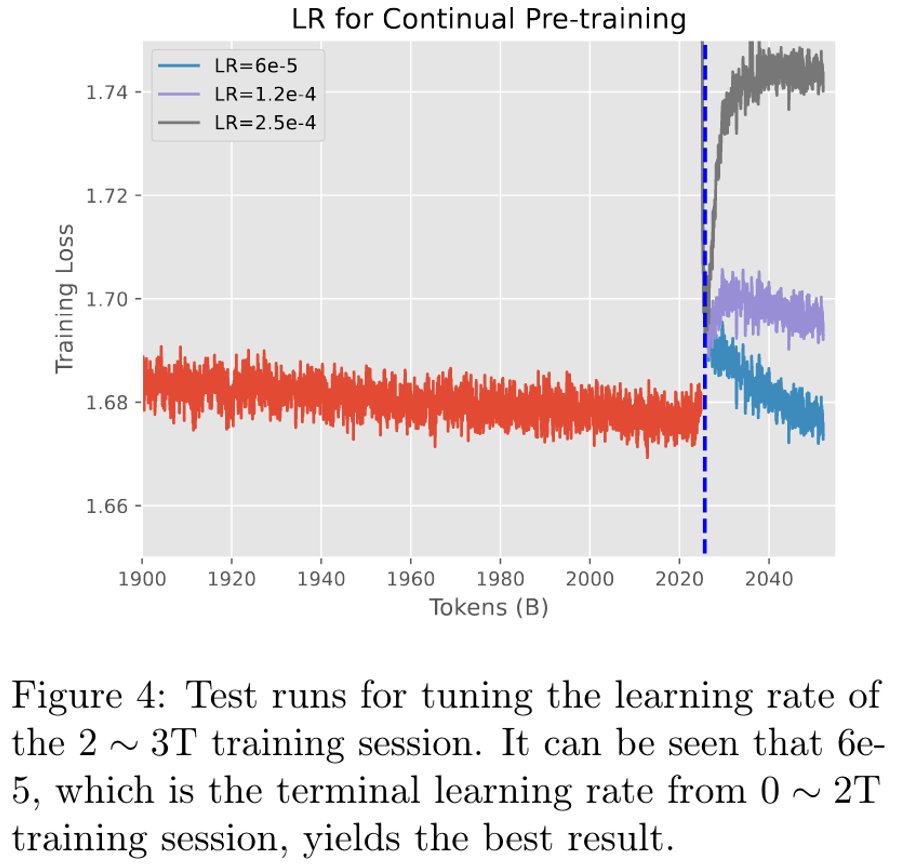
第三阶段0.13T的学科数据。最终训练数据是 20%学科数据,混80%通用数据(也就是≈0.7T)。同时,为了防止分布瞬间变化造成模型能力上的丢失。第二阶段的训练从10%的学科数据慢慢增加到40%。
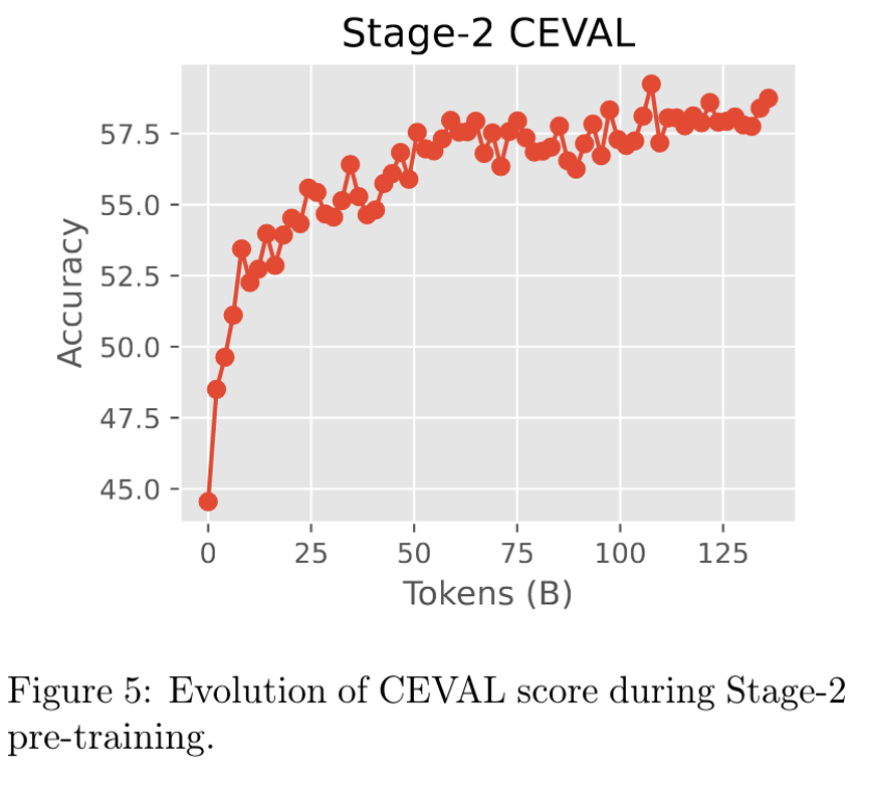
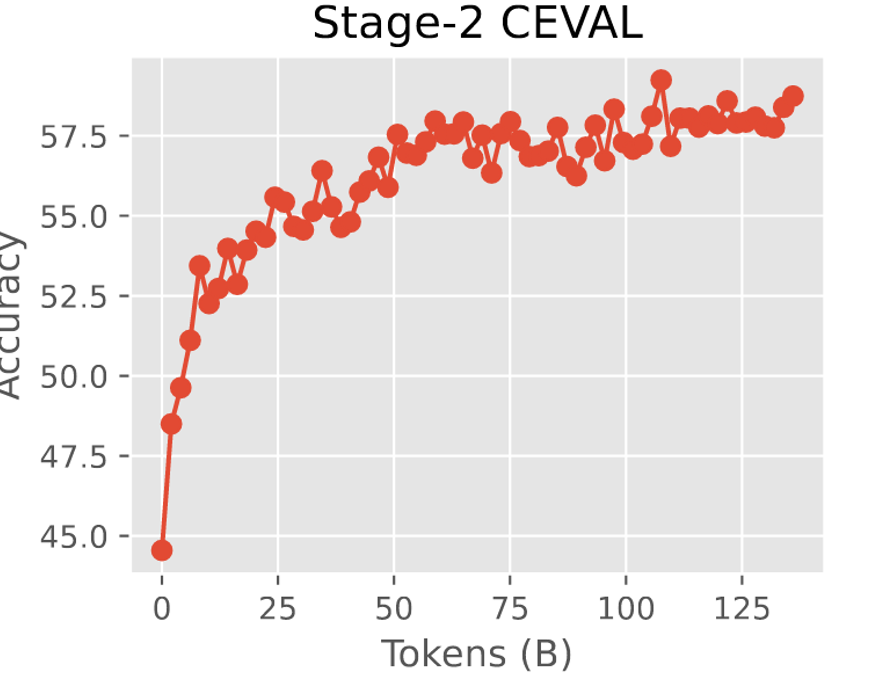
模型验证
本文在训练时,就通过监控各种数据集的验证集loss(ppl)来辅助验证模型的能力。能够较早的知晓模型整体能力的变化。
大部分领域的ppl,skywork都达到了一个较为强的水平。
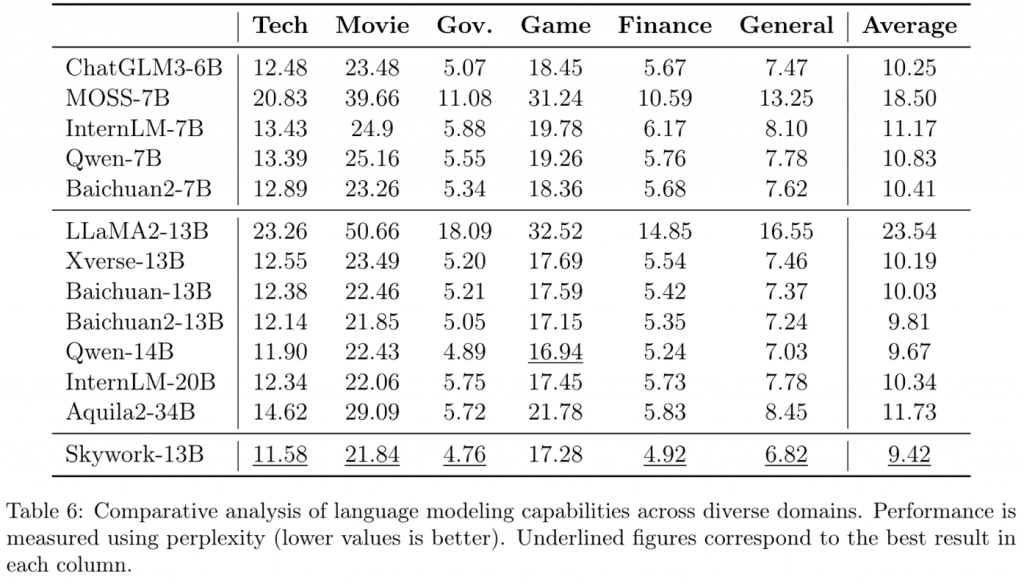
同时也做了一些比较有意思的验证。 首先就是
1.领域内的数据对预训练的影响
本文做了一个很有意思的小实验。取0.5T token的通用数据集来训练模型,随后使用1B的领域内数据集对模型进行微调。
结果发现,模型的领域内能力获得了很大的提升(甚至比训练3T的版本都要好),但是损失了一定的通用能力。
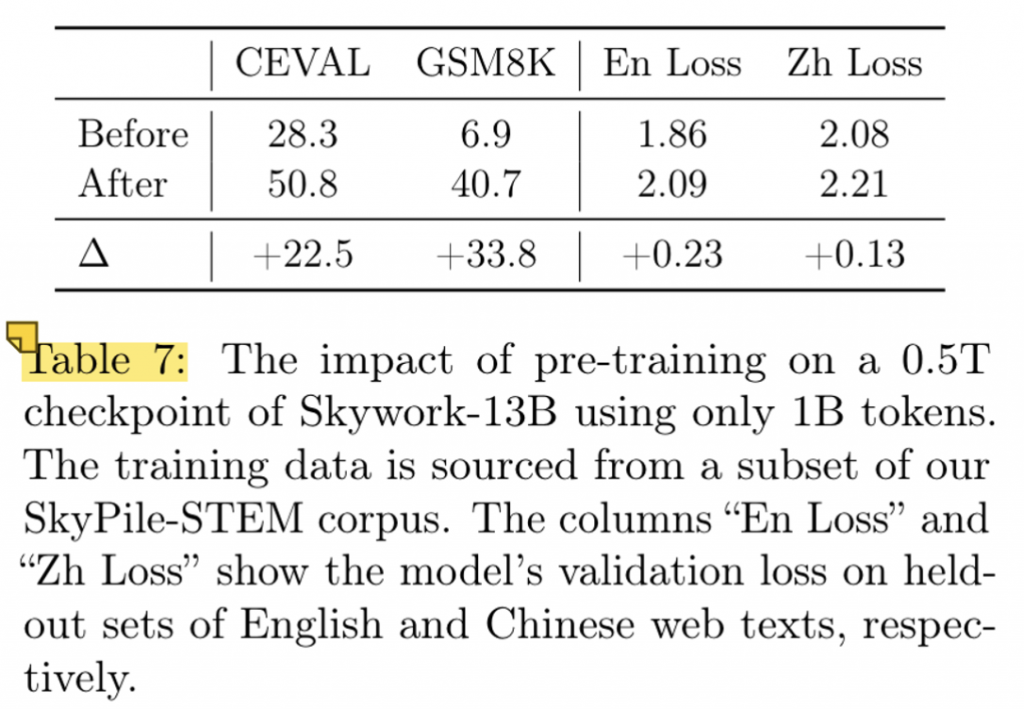
事实上,即使是3T的版本+1B的垂域数据,也没有达到这个水平(第一个点显然超过1B,但是甚至不到50),但是在经历过130B后,是显著超过了的。不过这就不确定能力来源到底是3T模型很强的迁移能力还是130B给的了。
不过这也证明了领域内数据对领域内是有正收益的,不过有可能会损伤整体的通用能力。
2. 依据1的结果,那么在领域内数据上进行预训练是一个通常的做法吗?
本文通过GSM8K的训练、验证和使用GPT4仿造的数据集上,分别对几个模型进行了ppl验证。
理论上,三组数据应该ppl一致。因为训练阶段不应该有相关数据泄露。
结果表明,有一些模型是进行了领域内数据的泄露的。
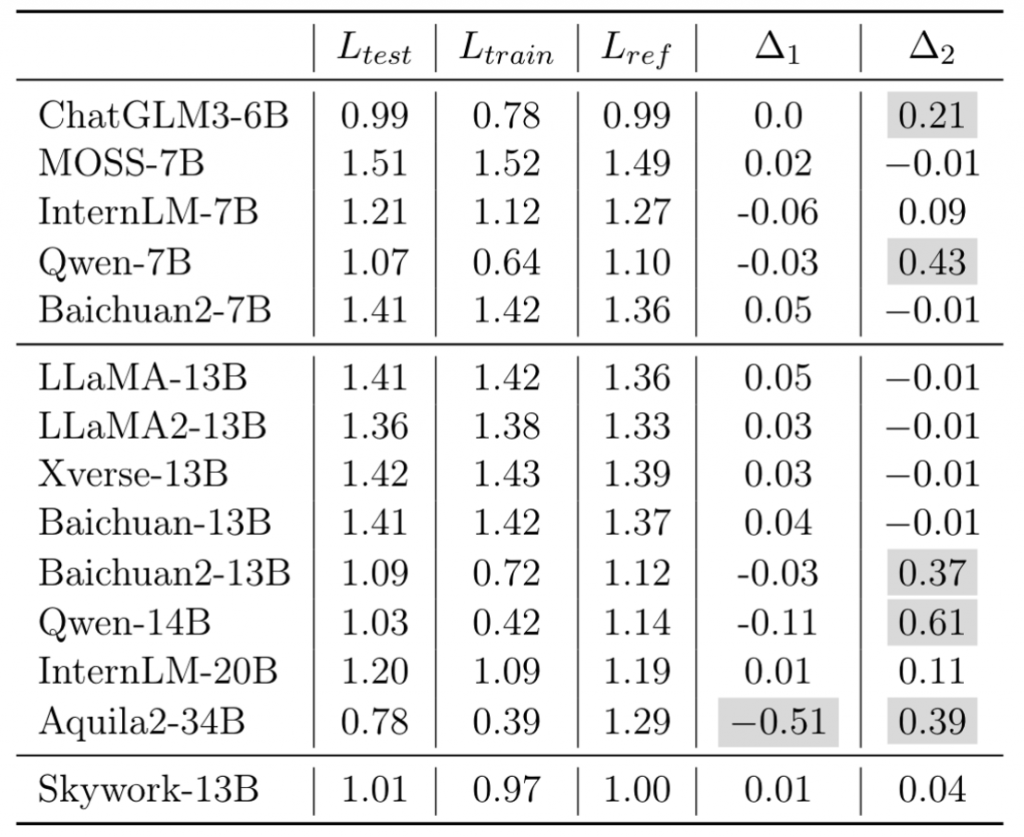
感觉这个实验就是用来骂baichuan的?(bushi。还有Qwen 说你呢!
实验比较匮乏,单验证领域内成绩可能和通用成绩不成正比,随后验证了一下究竟是哪个小伙纸用了领域内数据。
0 条评论