现在的模型一直在堆叠规模,但是很少有人在数据上细致的下功夫。所以ziya2在13B模型上只训练700B的token,就超过了llama2很多。
整体流程如下。在llama2 13B的基础上,分了三个阶段进行继续预训练。
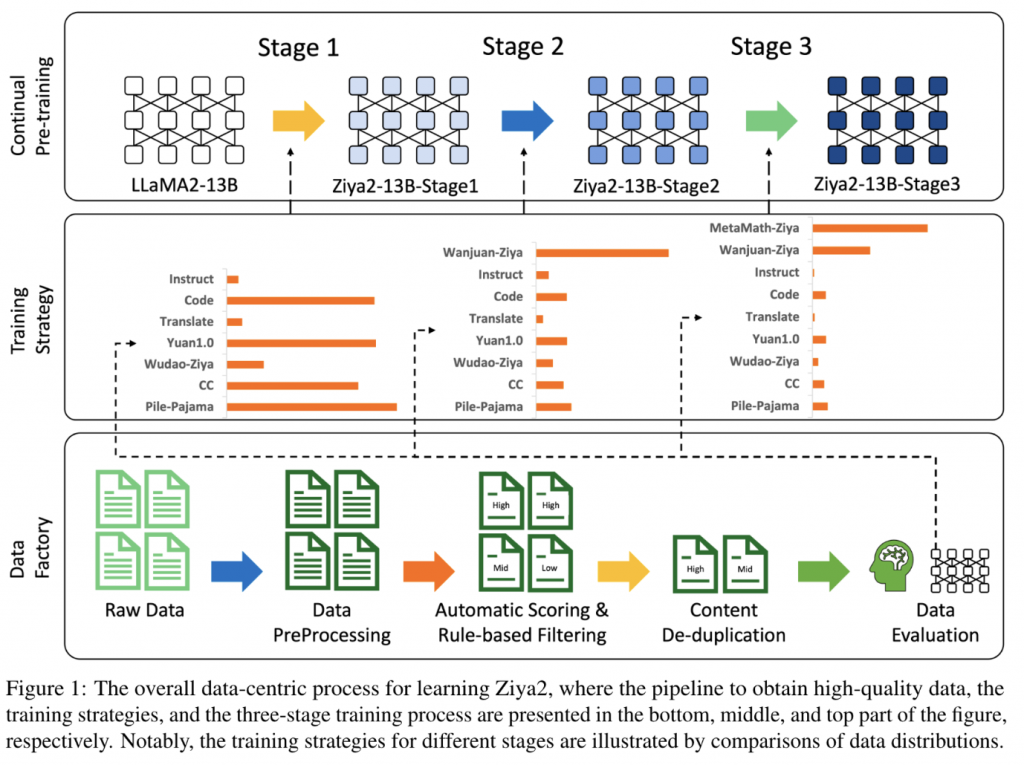
数据处理
数据处理分为了几个阶段
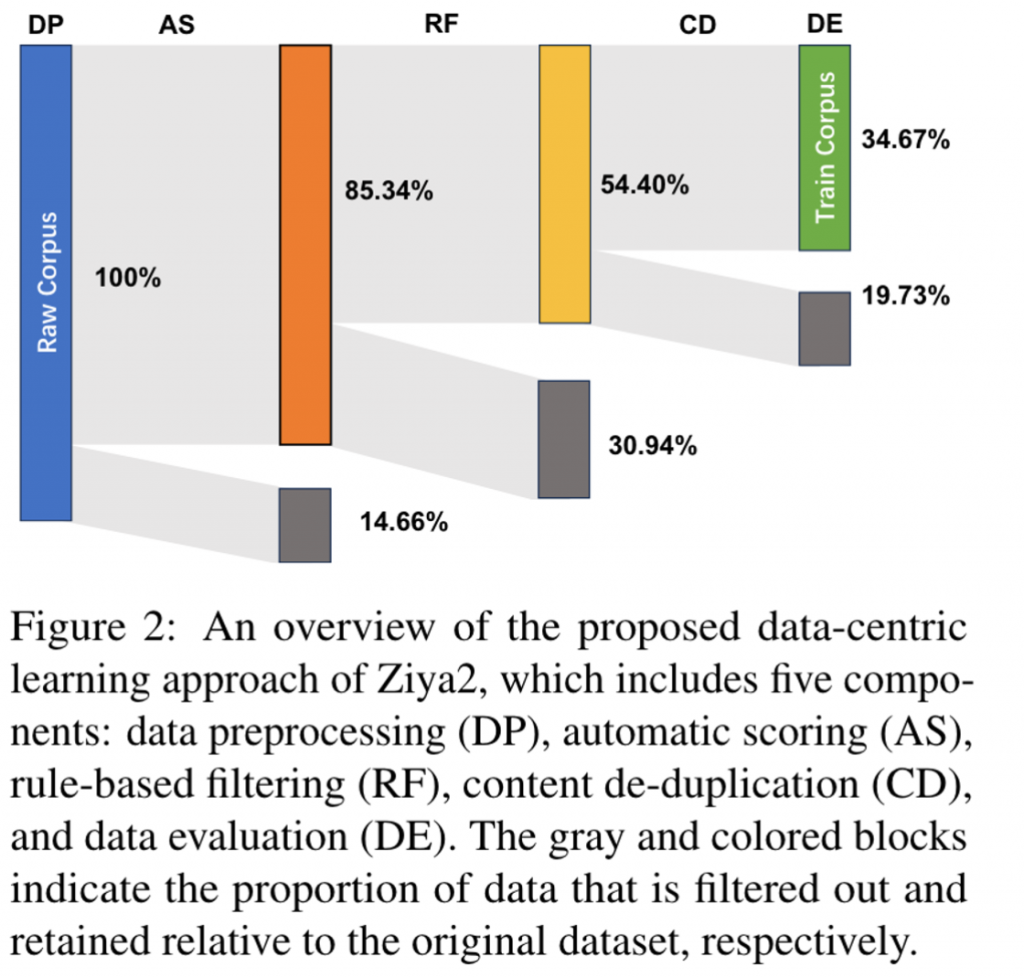
1.数据预处理(DP)
这一阶段主要包括中文的一些字体转换、符号转换、emoji处理等步骤。
2.自动打分(AF)
使用了一个经过wikii数据训练的KenLM来作为基准模型,计算cc数据的ppl。最终将top30%分数的作为高质量数据,30~60%的作为中质量数据,最后40%会被扔掉。
3.基于规则的过滤(RF)
这一步主要是一些启发式规则,用来去掉一些可能涉及到有害信息的段落和文本。当然这些规则在早期是要经过人工一致性校验的。
4.文本去重(CD)
因为重点是cc去重,因此首先使用url去重。这一步节省了大量的后续计算资源。随后使用minihash去重。
5.数据验证(DE)
人工校验数据筛选是否合理。
下图是整体数据筛选掉的比例。
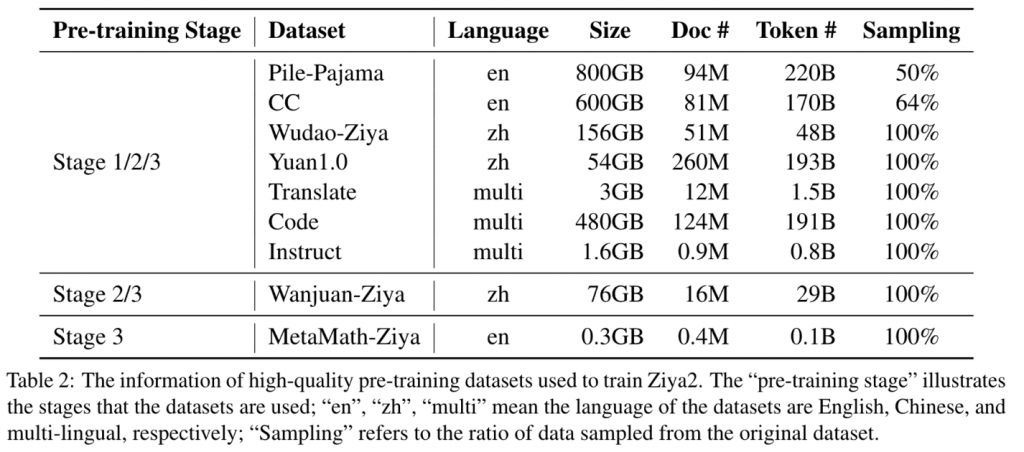
最终从13T的数据中筛选出了4.5T的token,采样使用的数据比例如下:
tokenize
添加了7400多个中文token,使用当前token的llama2多个token的平均值来初始化。
模型结构
整体上遵循llama2的结构。不过训练时有一些小变化。
position embedding上,仿照baihcuan2使用了全精度,来防止RoPE带来的精度溢出问题。
使用了APEX8 RMSNorm,也是全精度防溢出。
训练策略
初始化
tokenize初始化在前面已经说过了,由于llama2实际上有一定中文能力,将llama2tokenize后的多个token平均,作为新token的初始值。
对于数据部分,因为模型的训练整体分为了3个阶段。
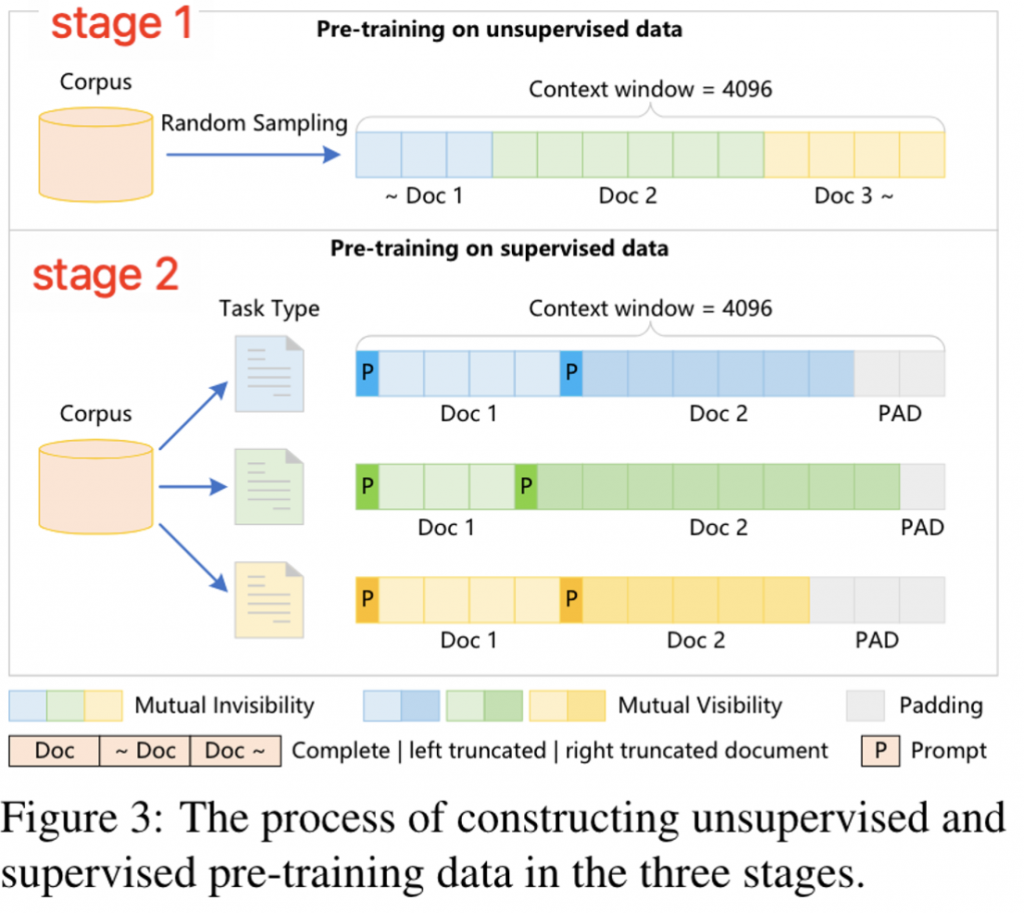
对于预训练文本,首先将所有的预训练文本打混。随后将多个预训练文档拼接,并且还对mask进行了一定的修改。防止多个数据之间产生干扰。
对于其他几个阶段会掺杂instruct数据,会将同task的数据进行拼接。但是不会对mask矩阵进行处理。
测评
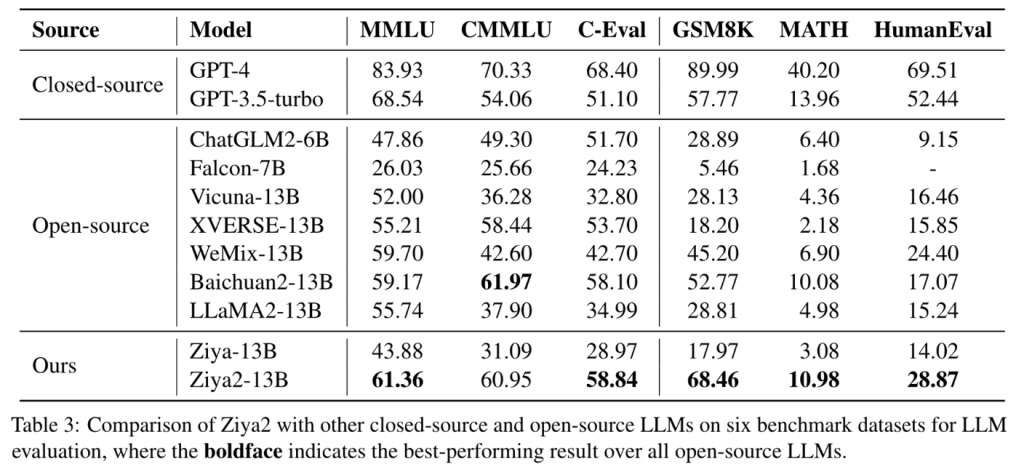
整体结果超过了一些开源模型,不过看起来没超过Qwen所以没有展示。
同时还展示了一些能力在训练过程中的变化。其实也会发现对于英文能力,都经过了先下降在上升的过程。不过中文能力似乎一直是在上升的。
第二三阶段因为有wanjuan、垂域(math)数据和instruct的加入,显著的提升了模型的部分能力。
后言
从目前的测评结果看,ziya2似乎是一个很强的基线。并且开源了数据配比、也是在llama2基础上热启的。似乎是最容易复现的一个工作。
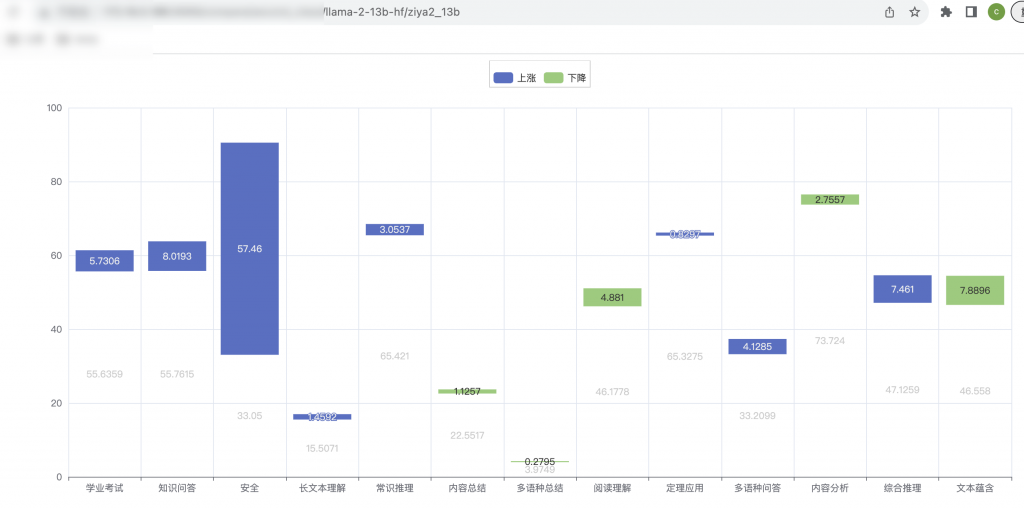
对比llama2-13b,英文能力上有了不少提升(蓝色代表提升,绿色代表下降)。中文能力应该完全碾压llama2.
0 条评论