MoE介绍
MoE(Mixture of Experts)和标准Dense模型的整体区别如下:
- 同参数下与Dense模型相比,预训练速度更快、推理速度更快。
- 需要更高的内存来装载MoE模型。
- 更大的训练挑战。
和标准Transformer模型的结构区别如下如所示[5],主要是将FFN层进行了更改,添加一个gate层,并将FFN变成n_expert个,由gate来对每一个token进行路由,选择不同的expert,最终再将这些expert的输出使用某种方式(大多数为相加)合并成output。
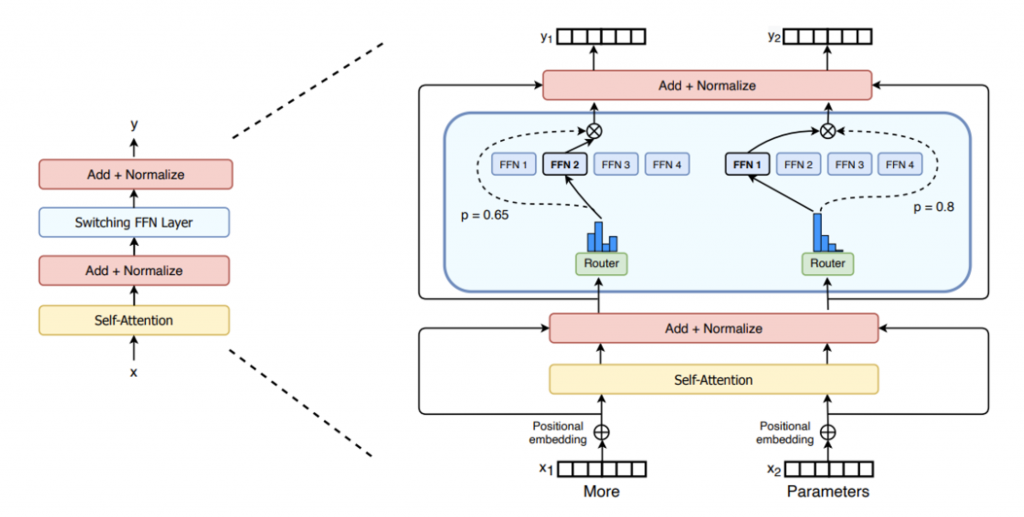
直觉上,由于使用了多个expert来对不同的token进行操作,使得每一个expert可以更加专注于某一项任务。类似于多领域推荐任务,每一个领域都有一个expert,由一个前置路由(或者请求来源)来决定具体执行的expert,并进行汇总返回。
但是这种结构的训练相对较难,由于使用门控来控制token进入的expert,因此直觉上需要保证每一个expert都会得到较好的学习,否则模型就会坍缩到一个expert上,变成了一个Dense模型,失去了MoE结构的意义。因此有些工作会在gate上添加z-loss来保证选择的expert的logit相对平衡。
而对于专家的数量和选择也是一个挑战,可能存在知识混合和知识冗余等问题,这在很大程度上限制了专家的专业性,影响了模型的整体性能。
MoE训练
现在主要的涉及到MoE的资料主要有Mixtral[4]、DeepSeekMoE[3]和上海人工智能研究院的Llama-MoE[2]。他们采用了不同的训练和初始化策略。
from scratch训练
DeepSeekMoE采用了从头训练,进行了多尺寸实验。大部分认知和结构验证都是在2B(等效0.3B)上完成,随后扩展到了16B(等效7B)、145B(等效22B)。
DeepSeekMoE采用了更加细致的expert划分,并使用了一个共享专家。主要动机是:
- 需要一个共享专家来提供综合性的知识。
- 使用更多的expert来将知识进行分解,同时提供更多样性的专家组合方式,更加有针对性的对知识进行获取。
模型整体性能在2B规模时,达到了Dense模型相当的性能。在16B规模下,使用40%的计算量达到了Llama2-7B的性能。在145B的规模性,使用28.5%的计算来那个达到了DeepSeek-67B的性能。
训练细节
对于2B的MoE模型,使用了9层Transformer,1280的hidden size,10个注意力头,维度为128。
参数初始化标准差为0.006,64个expert(1+63),每一个expert的大小为1/4个FFN大小。也就是整个MoE层为16*FFN。
AdamW+0.9&0.95。weight decay 0.1,batch size token 4M。学习率调度没有使用cosine及其变种。而是:
- warmup 2000个step到1.08e-3。
- 在80%step时,学习率缩小到0.316。
- 在90%step时,学习率继续缩小0.316(0.316^^2)。
论文中并没有交代为什么是1.08这种精确到-2级别的学习率以及0.316这种数,猜测是做了一些相关的scaling law实验。
通过对几个结构的验证,在小模型上验证了当前结构的有效性。性能超过同尺寸的Dense模型。
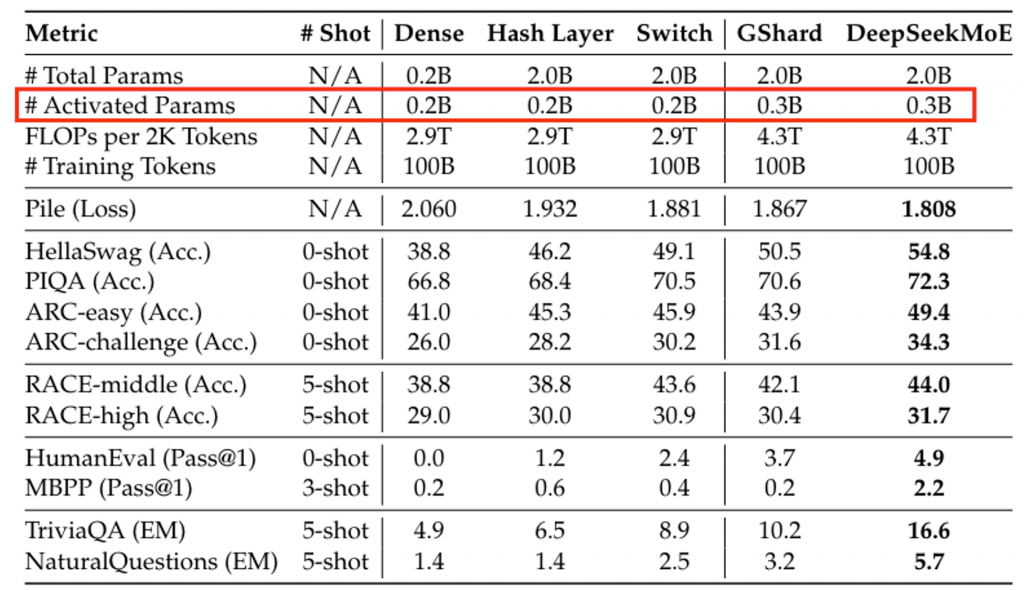
即使是和同参数量的Dense模型相比,该结构也具备一定的优势,说明了共享专家的有效性。
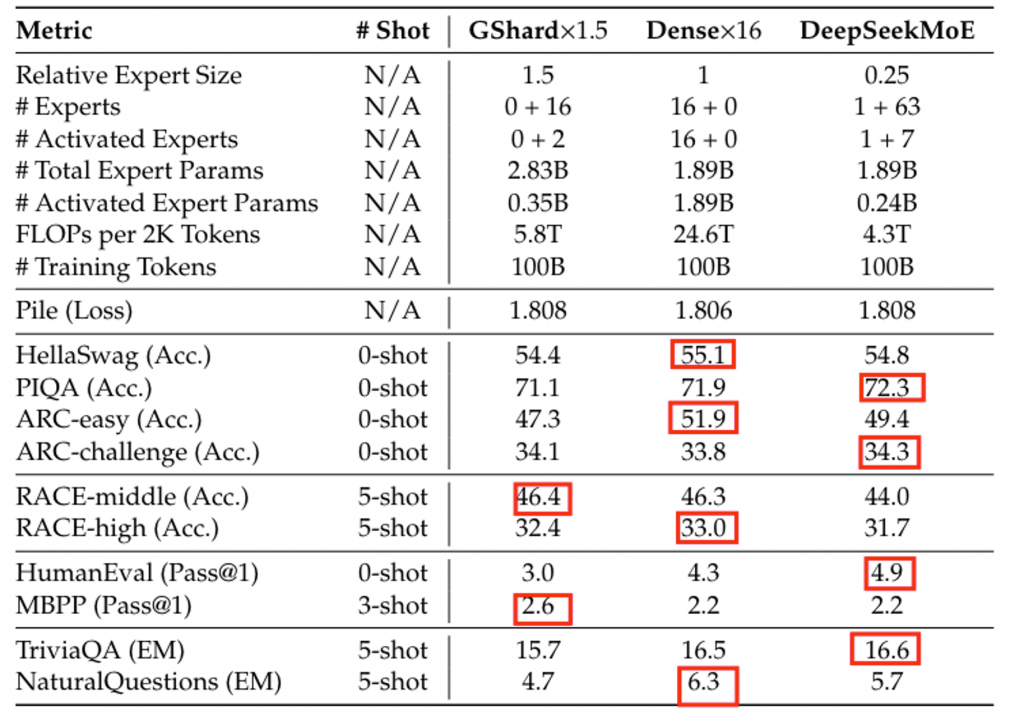
在16B的试验下,仅用40%的计算量就达到了DeepSeek-7B的性能,同时MoE结构在知识密集型任务上的表现更加出色。
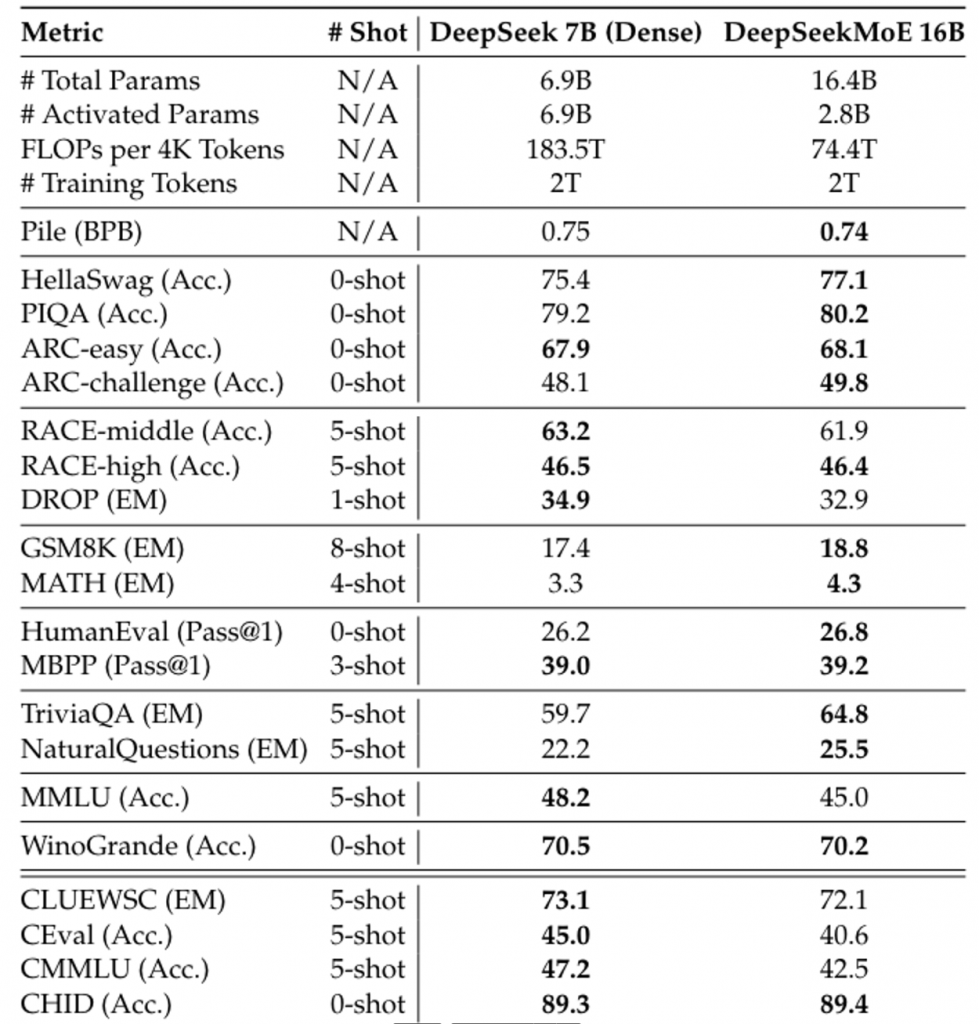
从现有模型扩展
Mixtral和Llama-MoE均使用了从现有的模型进行初始化随后微调的策略。但是他们却选择了不同的FFN初始化方向。
向上扩展
Mixtral使用了向上扩展的初始化策略,既用mistral-7B”扩展”出一个47B等效与12B模型的MoE模型。
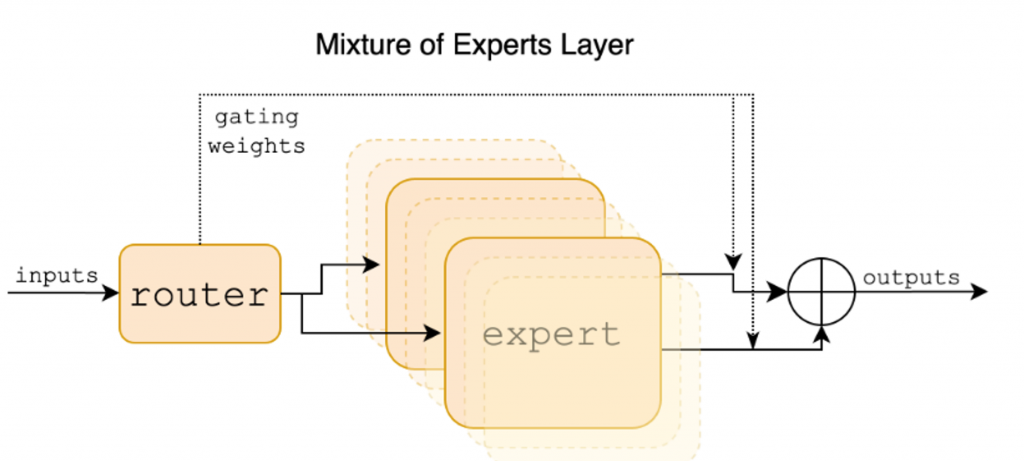
Mixtral(2/8)选择复用Mistral,并将FFN复制8份,其他参数完全复用。并在32k的上下文长度上进行了微调。整体性能基本接近Llama2-70B和GPT-3.5。整体结构类似于GShard。
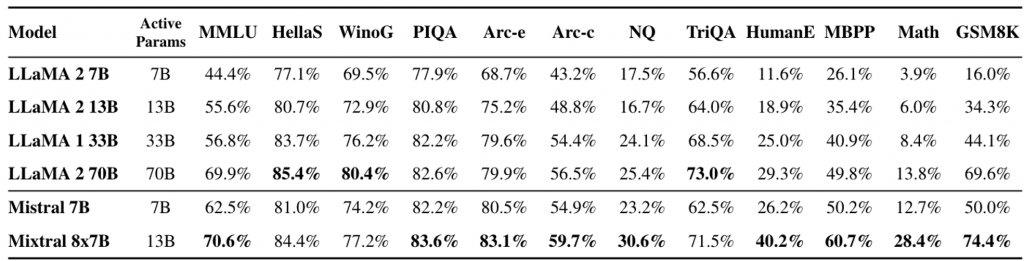
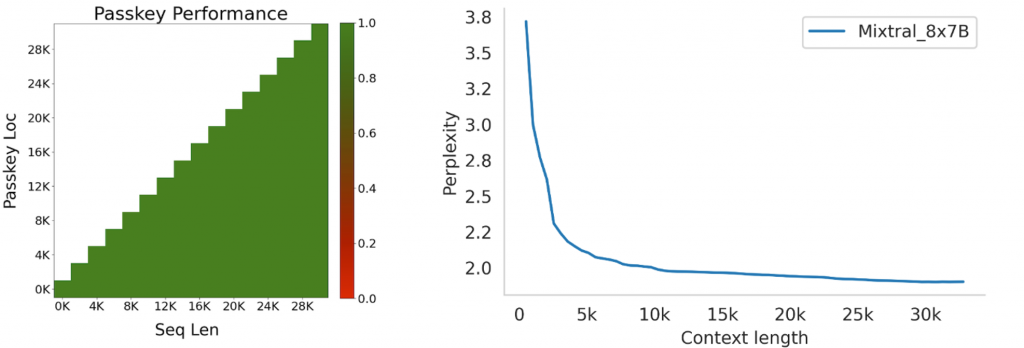
由于Mis/xtral使用的滑动窗口对长上下文具有独特的优势(因此Qwen2也是用这一结构),Mixtral还对长文本能力进行了测试,在秘钥检索这个任务重,获得了100%的准确率。
向下扩展
Llama-MoE使用了向下扩展的初始化策略,既用Llama2-7B“缩小”出一个7B等效3~3.5B的MoE模型。
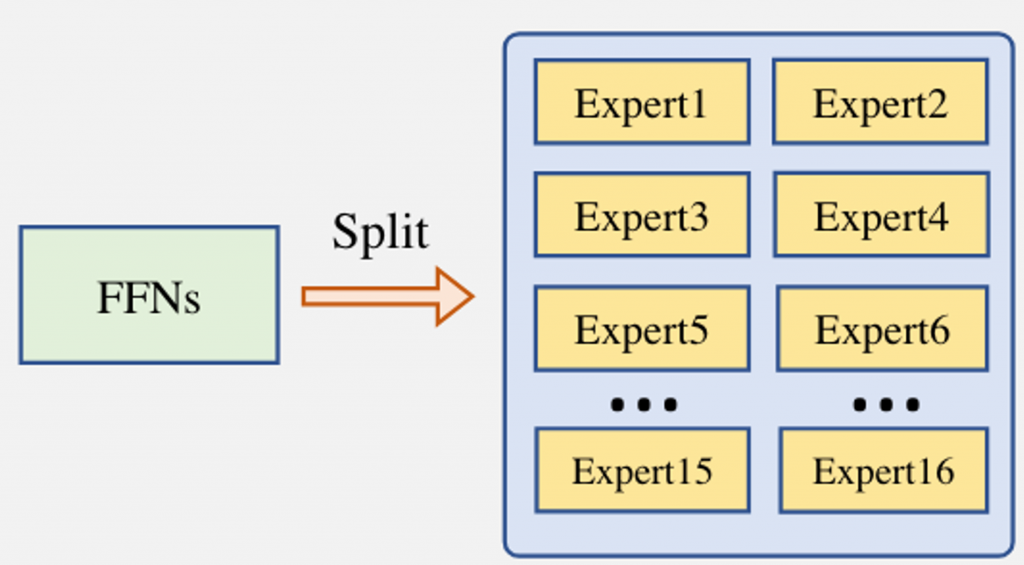
Llama-MoE-v1的性能显著低于Llama2-7B,因为采用向下扩展,因此整个模型的激活参数显著减少(根据不同的expert配置,在3~3.5B间)。不过Llama-MoE-v1既然在同激活量的Dense模型上获得了较为出色的表现。
训练细节
在Llama2-7B的基础上,使用112块A100 80G,global batch token 15M。
学习率使用cosine调度,从2e-4 ~ 2e-5。总计训练200B token(13.6k step)。
测评如下:
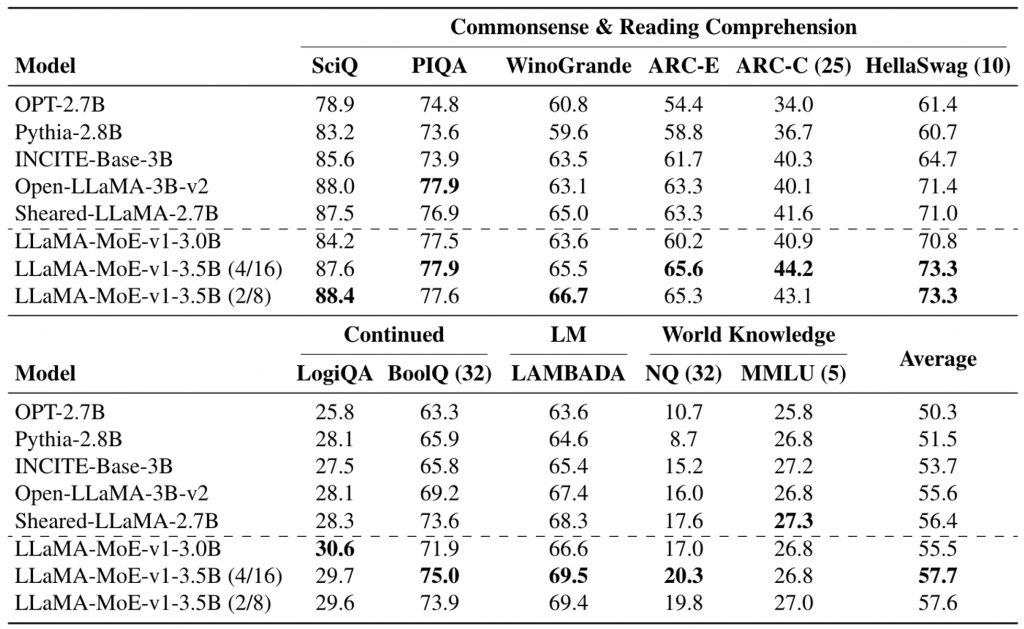
整体看,多expert似乎是一个正确的路线(和DeepSeekMoE一致)
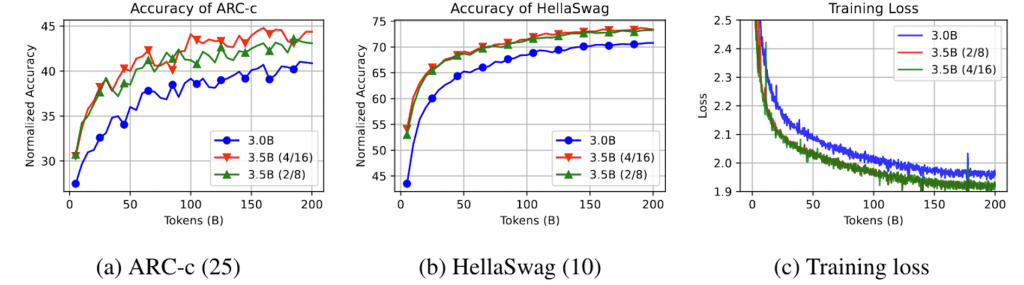
认知
这几篇文章提到了一些涉及到expert和数据上的一些认知。不过比较粗,可以当做一个坑留下,后面填。
expert认知
expert初始化
对于expert的初始化,对于Mixtral和DeepSeekMoE相对简单。对于Llama-MoE这类向下拆分的结构,会存在如何拆分expert的问题。均等拆分?聚类拆分?
论文对拆分方式做了验证。
- Independent Random: 这种方法涉及随机地将原始FFNs的参数分割成多个专家网络。每个专家网络都是独立且不重叠的,这意味着它们不共享任何中间神经元。这种方法简单直接,但可能不会考虑到专家网络之间的潜在结构和相互关系。
- Independent Clustering: 这种方法基于聚类来构建专家网络。它首先对FFN的权重进行聚类,然后将聚类结果用作专家网络的划分依据。这种方法试图找到权重之间的自然分组,以便每个专家网络都能专注于处理特定的输入特征。
- Sharing Inter: 这种方法涉及到在专家网络之间共享中间神经元。具体来说,不是将所有中间神经元随机分配给不同的专家网络,而是将一些神经元设置为共享的,而其他神经元则根据重要性分配给各个专家。这种方法试图在保持模型结构的同时,通过共享来减少模型的复杂性。
- Sharing Inner: 这种方法类似于Sharing Inter,但它在专家网络之间共享更多的中间神经元。这种方法可能会保留更多的模型结构,因为它允许专家网络有更多的重叠,这可能有助于模型更好地捕捉输入数据的复杂性。
Independent可能不会充分利用共享神经元的优势,而Sharing可能会导致专家网络之间的功能重叠,但也可能有助于捕捉输入数据的复杂性。
整体看,独立随机拆分的效果最好,不过这个效果好需要再15B token之后才能显现出来,聚类的效果一开始很好,长期效果不太行。猜测是降低了expert的表达性。
expert区分
几个模型也都验证了不同的expert是否有效,究竟在捕捉什么信息?
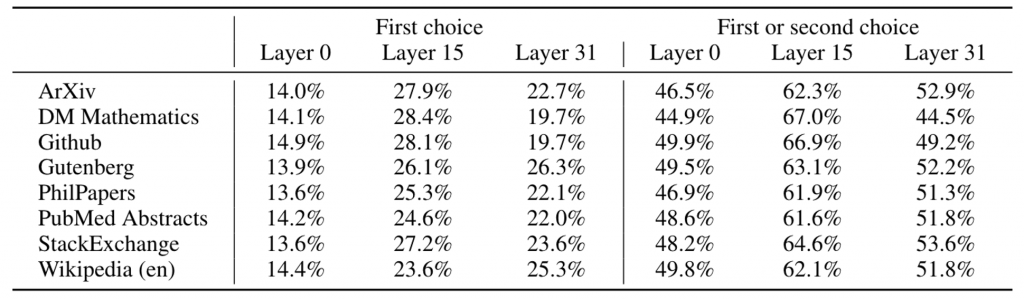
Mixtral对几个expert的选择进行了分析,通过对同一数据集的连续2个token的expert进行分析,发现浅层网络基本接近于随机分配(1/8=12.5%,1-6/8 * 5/7=46%),但是随着层数的增高,他们选择专门的expert的概率显著提升。
Llama-MoE也对expert进行了定向分析,发现不同的任务/数据类型选择的expert有明显的区分。
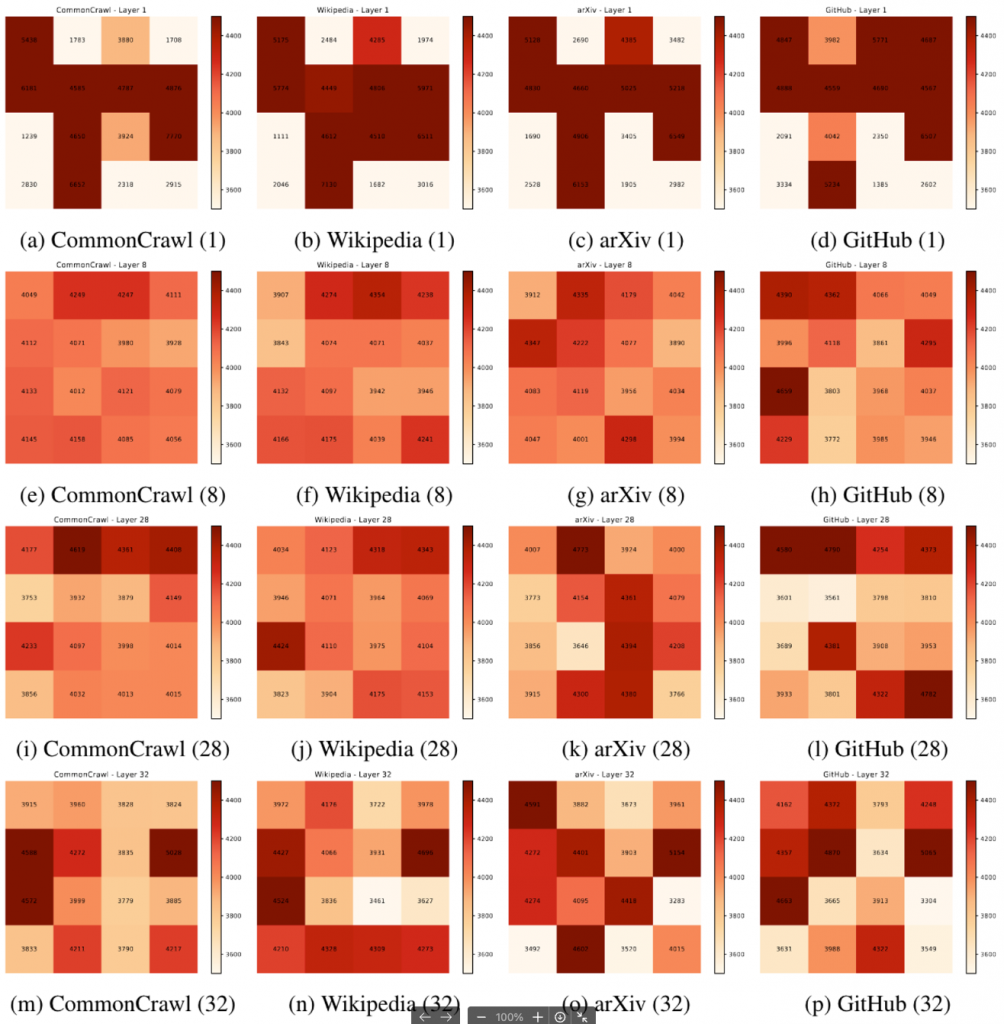
Mixtral还做了更详细的token级别分布。整体看,一些模版字符、符号、数字等 更容易被分配到一个expert中,说明了expert的有效性。也说明了expert学习到底并不像多expert的推荐系统在“领域”上学习,而是个更细致的语法级别。

数据/组合认识
Llama-MoE还实验了一些数据配比和清洗策略。
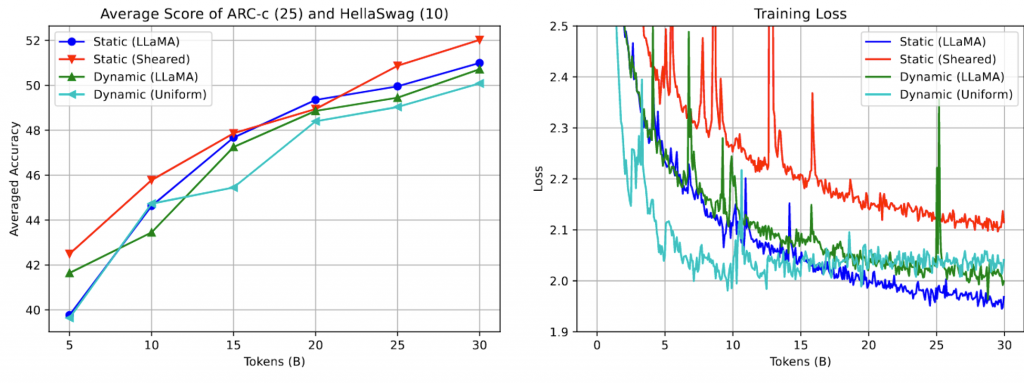
Sheared-Llama的配比似乎更优秀一点。考虑到这个MoE是基于Llama2-7B的,因此对于Llama2的后续工作似乎有指导意义。对于其他模型的后续工作,意义尚不明确。
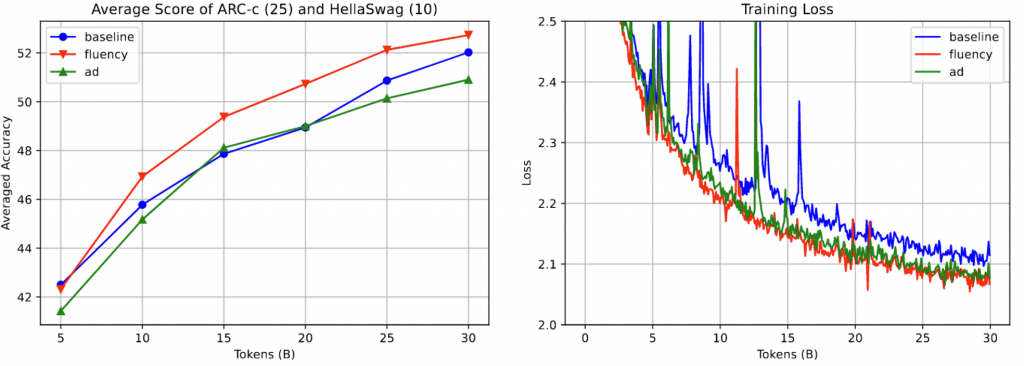
同时还对数据集中的广告和不流利文本进行了过滤,结论是不流利文本可以显著提升性能,但是广告文本性能有所下降,猜测是降低了数据多样性。
实现
Mixtral是使用megablocks来实现的MoE,Llama-MoE基于transformers进行了开发,在github进行了开源。
不过需要更新到Deepspeed 0.13.1以上,并且可能还有一些其他问题(2024.01.26),目前对于x/y架构的MoE模型可能训练还有一些问题(x!=y),当x=y时应该没有问题。主要原因是Deepspeed在数据并行时,只对一个进程进行监控,当该进程没有使用某些expert时,其他使用这些expert的进程的更新可能会产生错误。
https://github.com/microsoft/DeepSpeed/pull/5008
https://github.com/microsoft/DeepSpeed/pull/4966
对于是否需要对初始化的gate进行冻结,询问了Llama-MoE的人,结论是不需要。他们确实做过相关冻结实验,不过在大概20B参数的时候两者loss就没有明显区别(大概2.1,区别全参数微调),因此他们的训练并未使用任何“gate相关的魔法”。
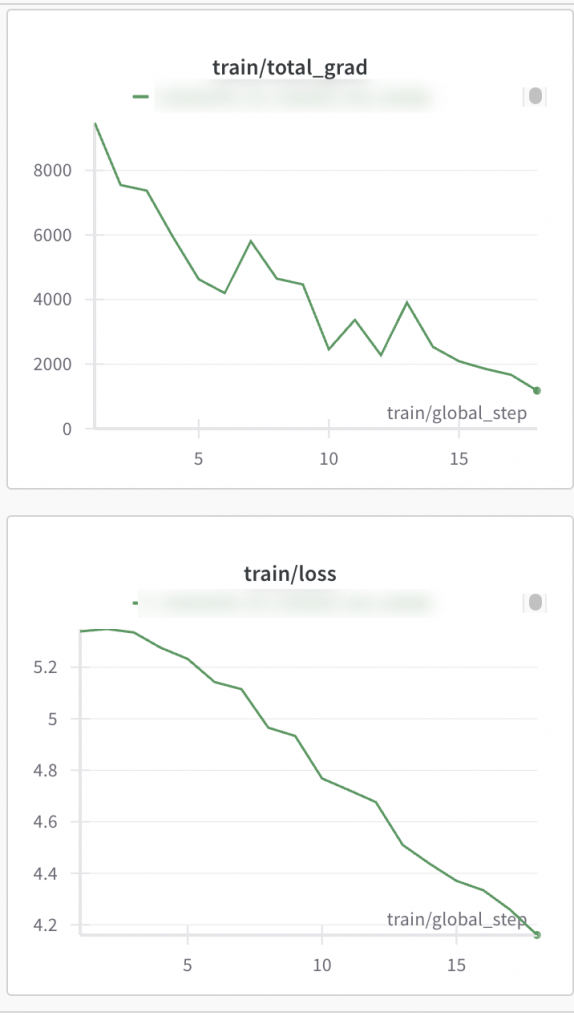
另外使用类似于Mixtral方式初始化的模型,初始阶段梯度过大,不过观察到了明显的下降。考虑到大尺寸的梯度确实会大一点,同时Deepspeed的一些问题以及参数融合等代码可能存在的bug,可能需要后续观察。
引用
1.https://huggingface.co/blog/moe
2.Llama-Moe https://github.com/pjlab-sys4nlp/llama-moe/blob/main/docs/LLaMA_MoE.pdf
3.DeepSeekMoE http://arxiv.org/abs/2401.06066
4.Mixtral http://arxiv.org/abs/2401.04088
5.Switch Transformers https://arxiv.org/abs/2101.03961
0 条评论