1.动机
–
2.数据集
BLOOM使用ROOTS数据集进行训练,BLOOMZ在BLOOM的基础上,继续使用xp3进行了训练。
ROOTS与xp3的多语言数据分布如下:
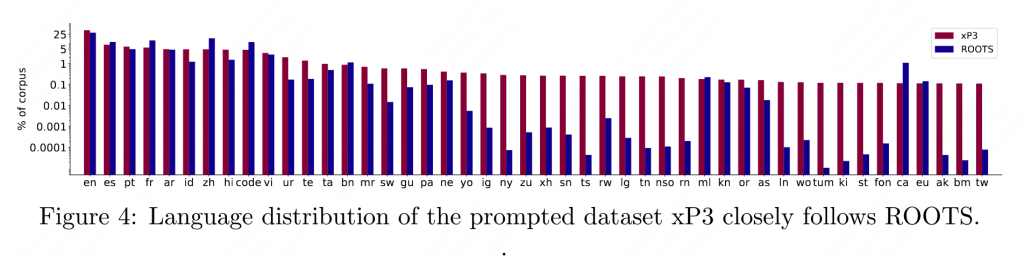
2.1 ROOTS
ROOTS包含了46种人类语言和13种变成语言,涵盖了huggingface中的498个数据集,总计1.6T的空间,341B的token。
数据预处理方式如下:
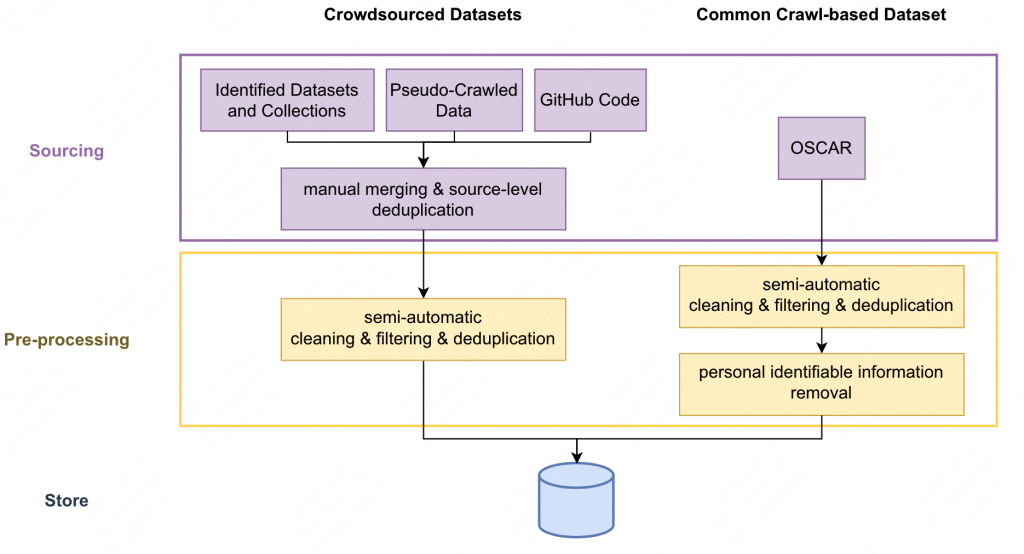
数据处理主要分为以下几种方式:
- 过滤一些不是高质量的文本(比如垃圾邮件、SEO页面等),但是有意地将高质量文本定义的较为宽松,仅仅定义成为“人写的”,区别于一些自动生成的文本,不区分内容和语法。
- 对于代码(github数据集)会去重。
- 会使用正则删除OSCAR中涉及到个人信息的部分文本。
- 对多种符号进行标准化。(如下图)

每种语言的数据分布,可以看到中英比例相对比较高,480G vs 260G+76G。
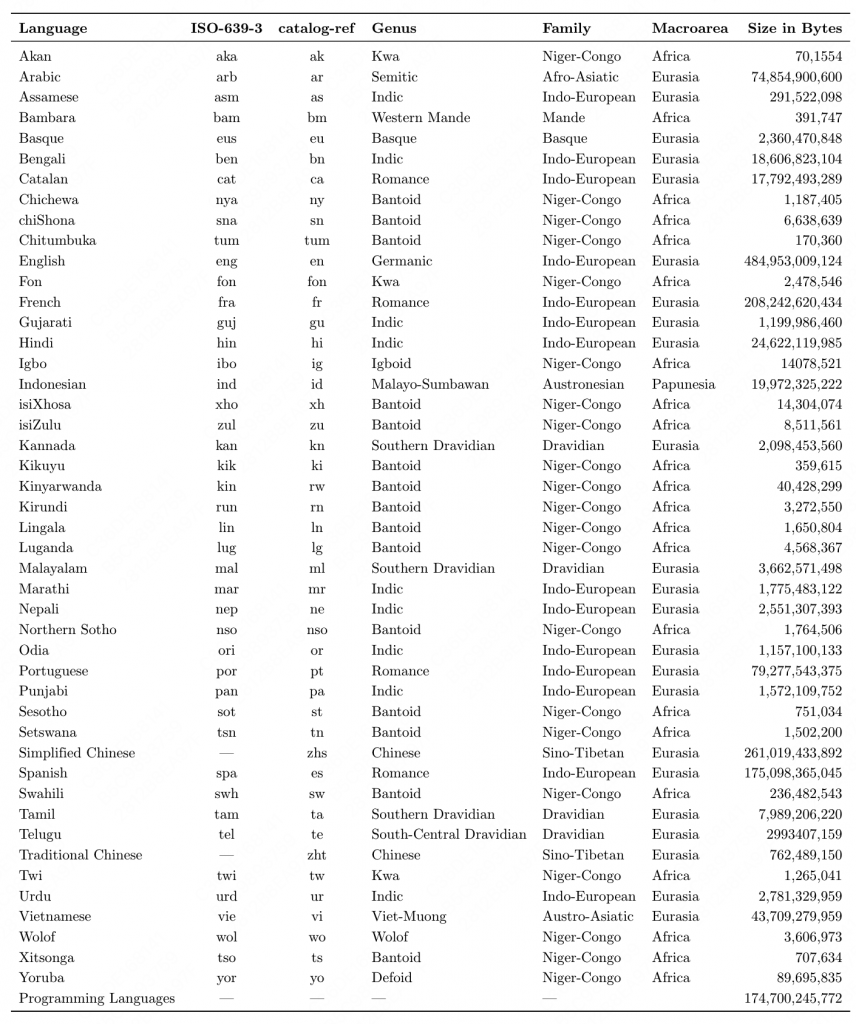
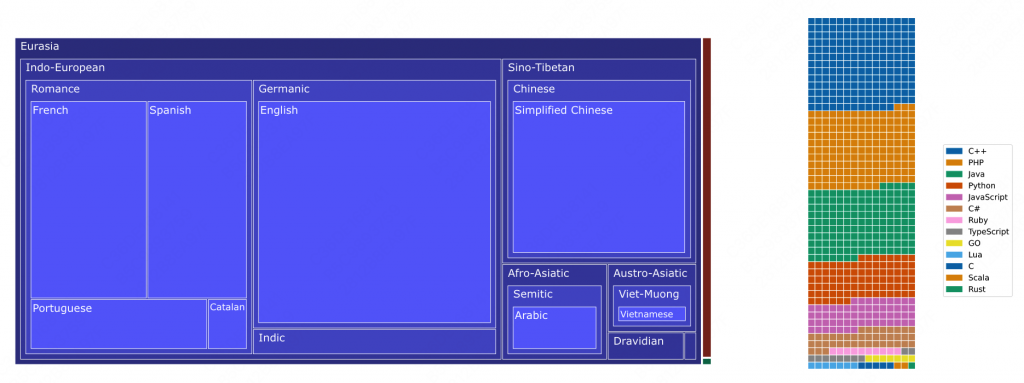
2.2 xp3
在T0的P3(包含2000+ prompt 和170+ 数据集)的基础上,扩充了例如翻译等任务,包含16个语言和16种任务,得到了xP3。
3.模型结构
3.1 为什么是decoder only?
本文尝试了很多种结构,最终确定decoder only是一个最优秀的llm结构。详见
https://proceedings.mlr.press/v162/wang22u.html
不过本文提到,任务型的最优结构其实是T5这类的en-decoder结构(lm的最优结构是decoder only),有点好奇为什么既然最终的结果是要做任务型,但是还在拼命地卷decoder的llm。
3.2 为什么是AliBi?
别问,问就是做过实验,优于学习和rotary。 “outperforming both”
AliBi论文:
https://arxiv.org/abs/2108.12409
不过这点存疑,挖个坑后续补吧,既然好为啥后续工作GLM和Llama都没用捏。
3.3 layer norm
他们在embedding后立刻进行了一次layer norm,可以有效的增加模型的训练稳定性。不过呢,美中不足的是这个结论是在f16(且参数小于等于104B)的情况下得到的,而在训练176B的BLOOM时,由于大家已经普遍认知f16的性能没有bf16好,前者可能会带来训练不稳定。因此BLOOM176B可能减弱了对改LN的需求。
下图为hf的BLOOM实现,可以看见embedding后立刻进行了一次LN,不过使用的是原始LN而不是Llama使用的RMSLN。
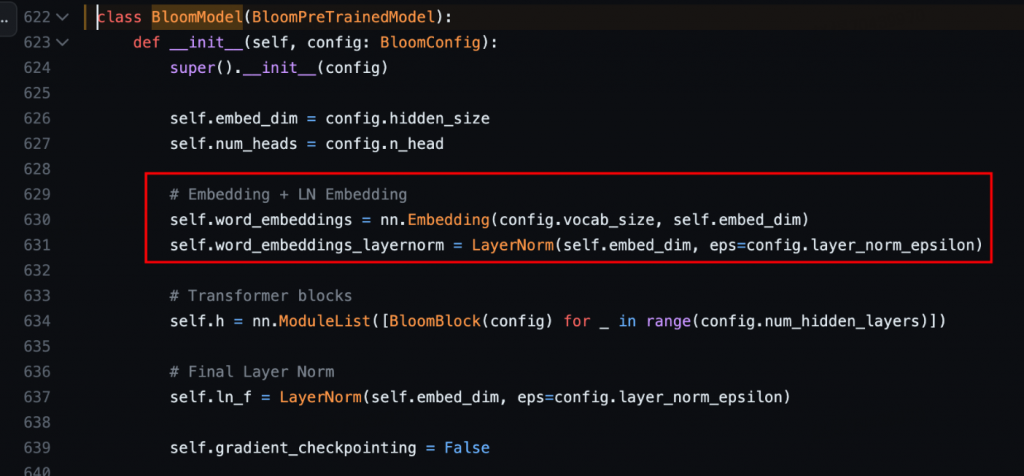
3.4 tokenizer
对tokenizer(BPE)进行了一定的分析,首先定义 fertility(生育率)为:拆分一个单词的比例。
实验表明,较高的生育率可能会影响模型对其他语言的迁移能力,最终影响多语言性能。因此将生育率限制到10%左右。
他们也在150k词表和250k词表上进行了实验,最终250k词表胜出,但是为了兼容megatron,必须是4的整数倍,因此最终词表大小为250680
整体的模型结构如下图:
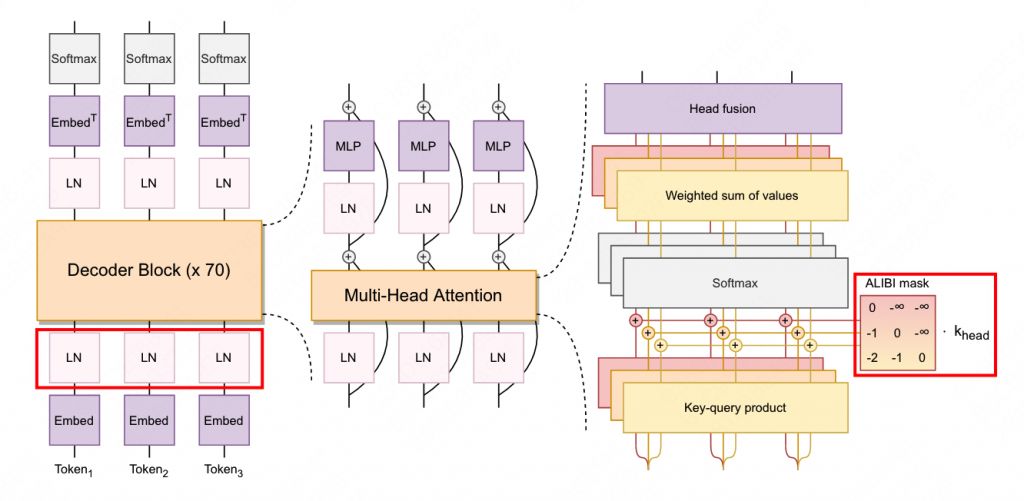
4. 训练细节
混合精度训练。参数如下
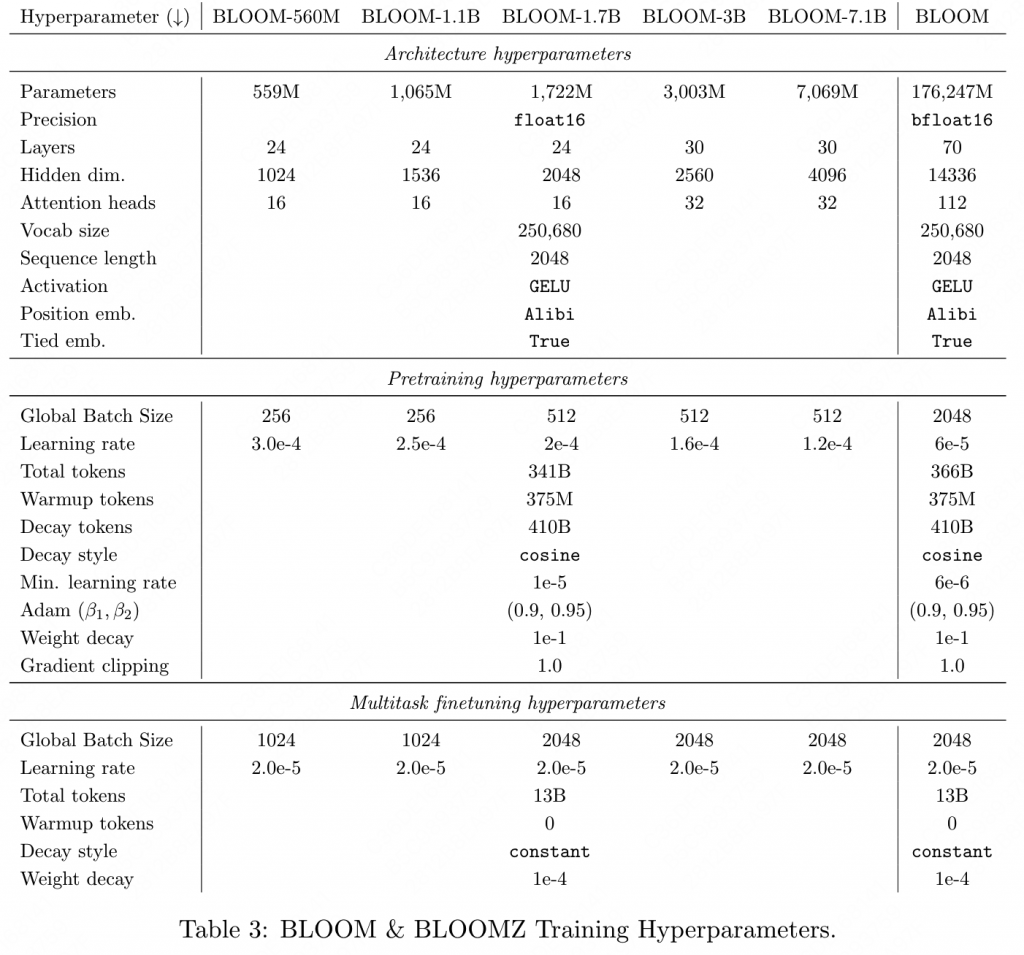
- 在训练BLOOM过程中,也尝试了更改Adam的β、权重衰减、梯度裁剪等策略,但是并没有观察到明显的性能提升。
- 在训练BLOOMZ的过程中,xp3总计有13B的token。但是由于使用最优val set来进行保存,发现在 1-6B 时的效果就开始趋于稳定。
5.模型验证
在 SuperGLUE、机翻、摘要上进行了x-shot的验证。
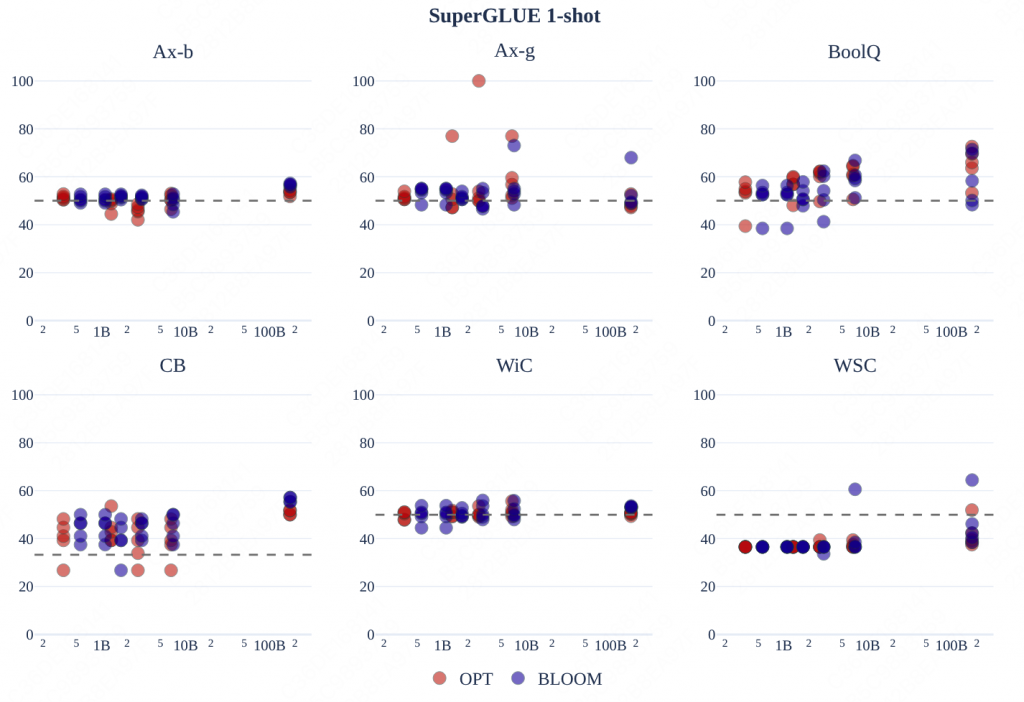
5.1 SuperGLUE
分别是SuperGLUE上 0-shot和1-shot的结果。
- T0表现出了强大的性能,但是考虑到T0是经过sft的,因此结果再对比中并不完全可信。
- 尽管Bloom在zero下,通常会落后OPT,但是在one下,BLOOM获得了更高的提升。猜测是多语言的模型可以在长文本中或得到更多的信息。
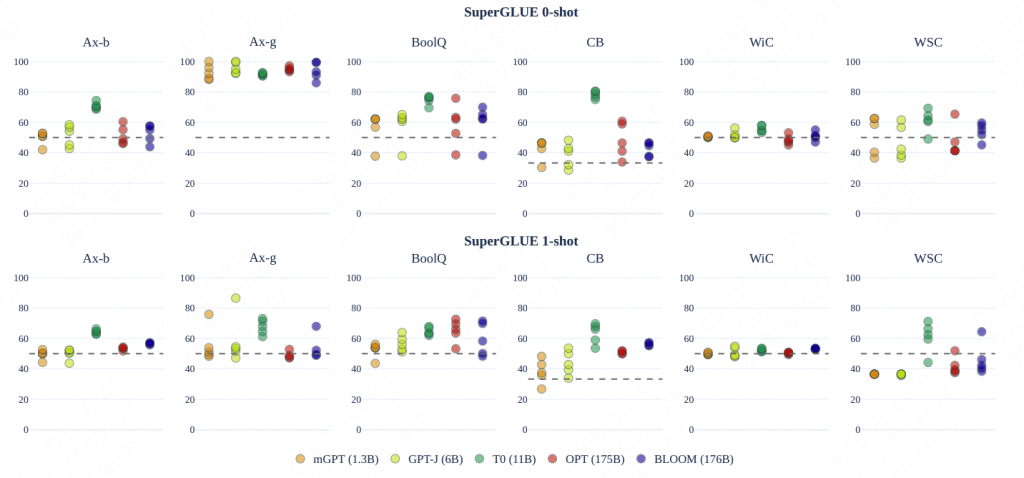
多个尺寸的BLOOM在one-shot上,在5个测评任务上性能并不落败于OPT。
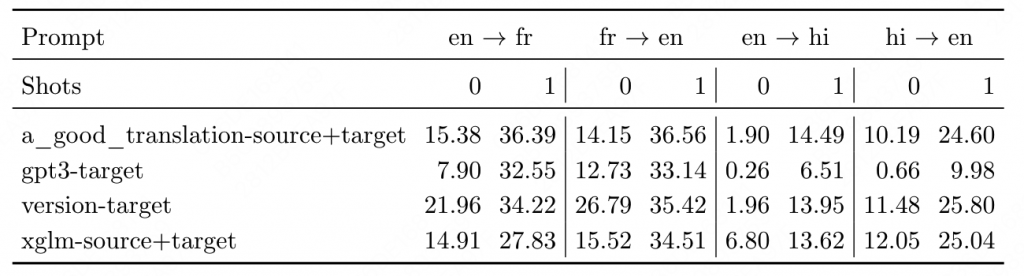
5.2 机器翻译
数据集:WMT14 en-fr en-hi Flores-101 DiaBLa
同时结束标识符是EOS或者是 \n###\n (多shot的间隔符)
在zero情况下,结果比较糟糕,原因主要是:(1) 过度生成;(2) 不能够产生正确的语言
使用了一下四种prompt构造,其中L1、L2分别为语言名称:

WMT14的结果
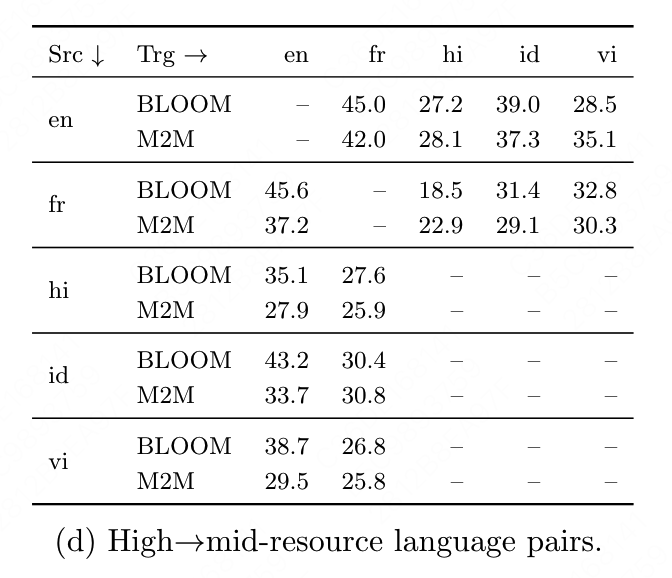
Flores结果,高资源语言->中资源语言的翻译结果(部分展示 oneshot)
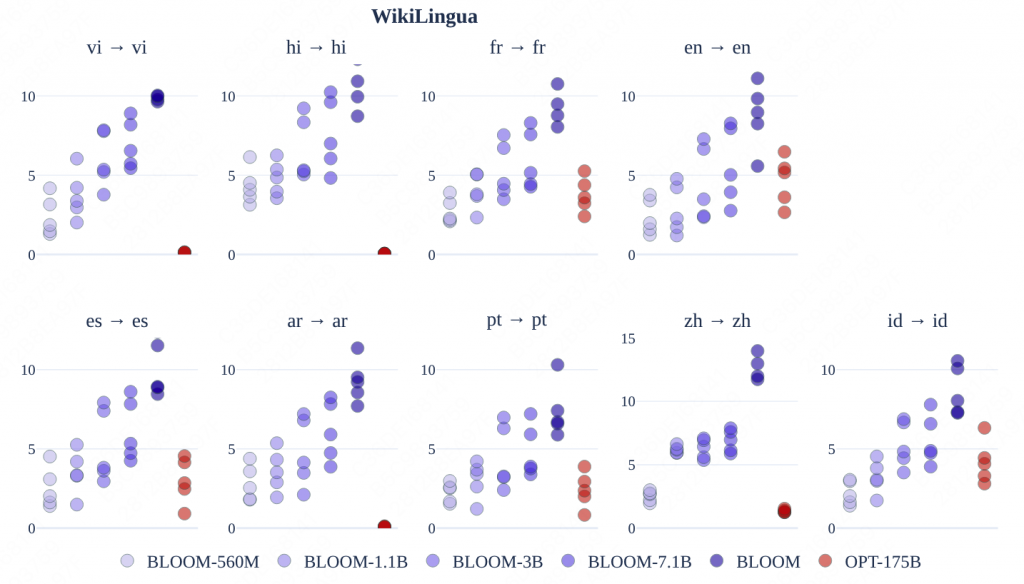
5.3 摘要
数据集:WikiLingua
指标:ROUGE2(不过论文依然指出,ROUGE2没办法完全描述模型生成的文本质量)
5.4 代码生成
ROOTS中包含了大概11%的code数据,与GPT的训练数据集Pile的13%类似,最终性能上也相似。但是BLOOM的鲁棒性更好(高k/温度 下的表现依然稳定)。更多的分析详见: https://arxiv.org/pdf/2211.01786.pdf
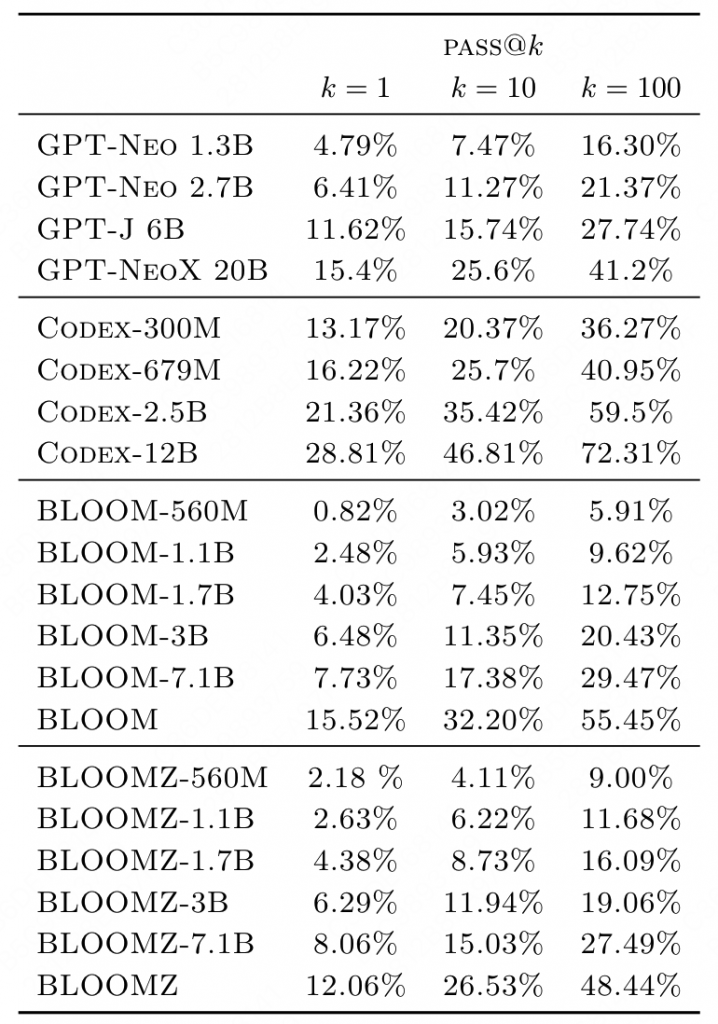
5.5 HELM测评
对比了BLOOM、GPT3 davinci 、InstructGPTfavinci v2、OPT等模型,BLOOM的整体位置中等偏上。

5.6 多任务finetune
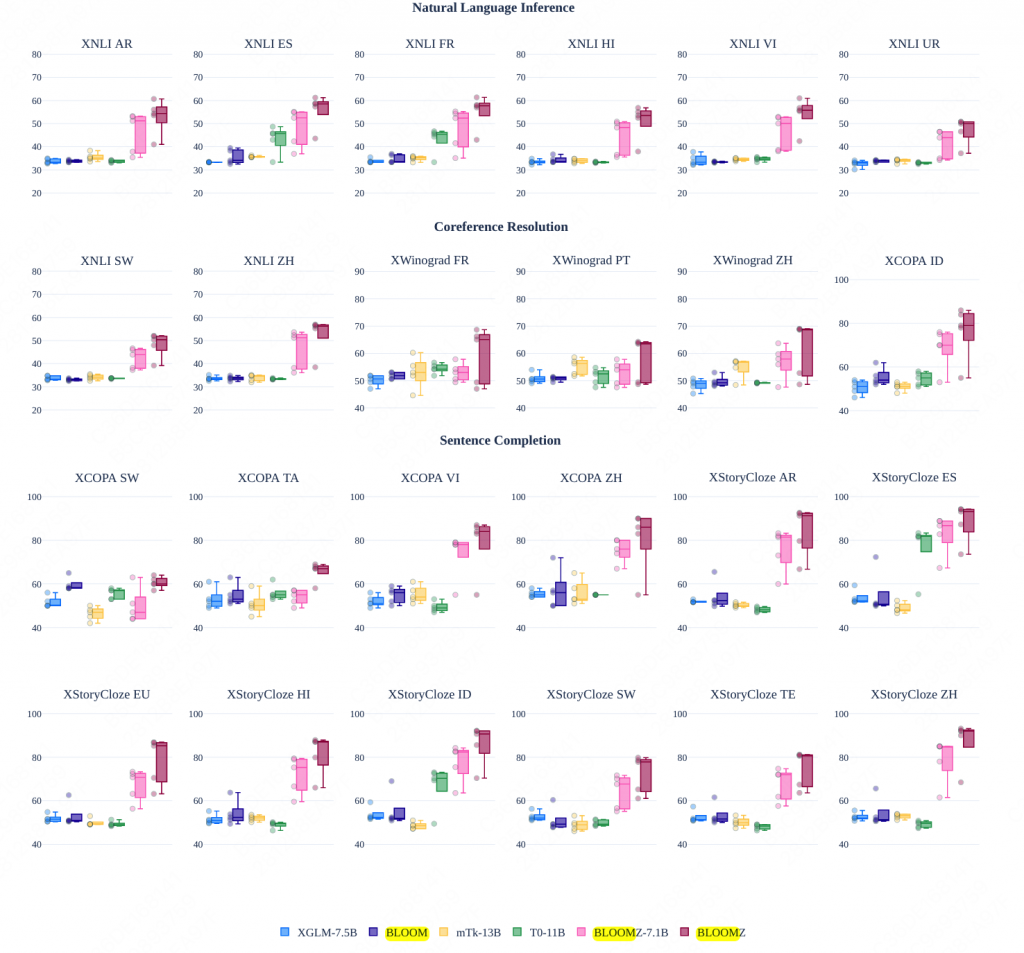
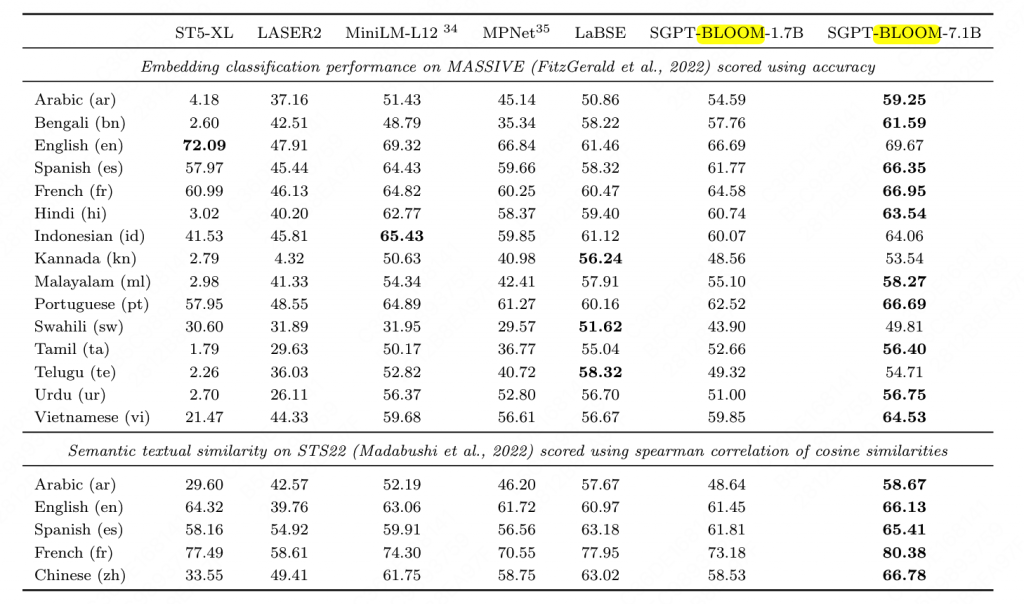
5.7 embedding
训练了SGPT-BLOOM-7B1-msmarco、SGPT-BLOOM_1.7B-nli,在Massive Text Embedding Benchmark MTEB https://arxiv.org/pdf/2210.07316.pdf 上的结果
0 条评论