在最前面提一嘴chromedriver的下载地址:http://npm.taobao.org/mirrors/chromedriver/,注意要和自己chrome的版本对应。
在使用selenium经常会被检测,比如一个淘宝等网站,都会对selenium进行检测。
我们在这里以一个测试网站https://antispider1.scrape.center/为例进行说明。
首先编写代码:
from selenium import webdriver
url = 'https://antispider1.scrape.center'
chrome = webdriver.Chrome('./chromedriver.exe')
chrome.get(url)运行后被拒绝访问
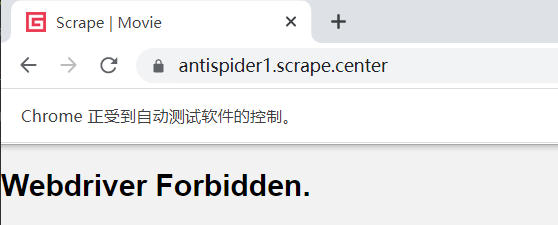
这时候我们只需要简单地更改一些代码:
from selenium import webdriver
# add
from selenium.webdriver import ChromeOptions
url = 'https://antispider1.scrape.center'
# add 隐藏提示条和自动化扩展信息
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
# change
chrome = webdriver.Chrome('./chromedriver.exe', options=option)
# add 执行CDP
chrome.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator,"webdriver",{get: () => undefined})'
})
chrome.get(url)可以正常访问该网站:
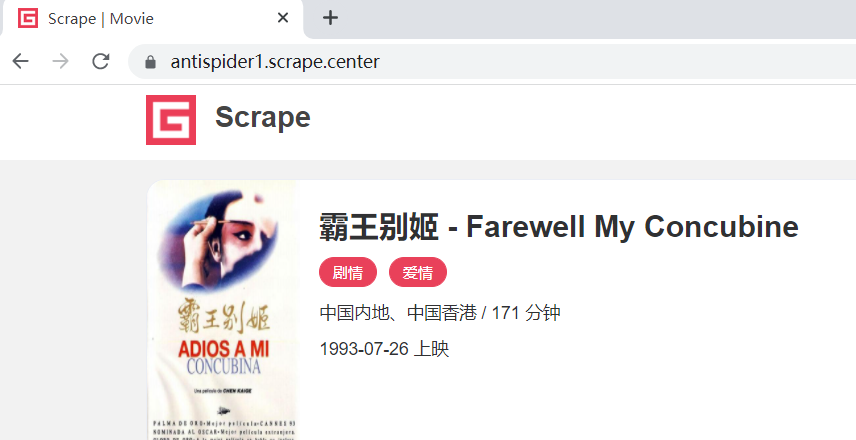
原理是:
网站通过检测当前浏览器窗口下的window.nevigator对象中是否包含webdriver属性,我们通过使用CDP(chrome devtools protocol,Chrome开发工具协议)在每个页面刚加载时,将这个属性置空。
0 条评论