吴恩达深度学习第一课第二周 具有神经网络思维的Logistic回归(包括作业)

二分分类
什么是二分类?
二分类问题简单说就是非0即1的问题,举个例子

图片中的是不是猫?只有是(1)或者不是(0)。
逻辑回归
具体查看【吴恩达机器学习】逻辑回归
广播
我们看下面这组数据,说明了每100g各种食物从碳水化合物、蛋白质和脂肪中获取卡路里的数量(g)
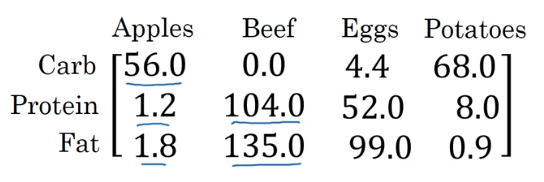
从图中我们可以看出,每100g苹果中,共有56+1.2+1.8=59g的卡库里,其中接近95%都是从碳水化合物中获取的,那么如果我们想知道每一个位置的百分比而又不使用for循环该怎么做呢?
思考下面代码
cal = A.sum(axis=0)
percentage = A / cal
print(percentage)我们经过第一步计算,获取了一个(1,4)的cal矩阵,而A是一个(3,4)的矩阵,这时候我们如果执行第二行操作,python会自动将cal从(1,4)扩展到(3,4)然后和A计算,最终达到我们想要的计算结果。
同理,对于一个 (m, n)的矩阵加上(1, n)的矩阵,可以直接相加,python会自动扩展至(m,n)然后再相加 。
测验
1. 神经元节点计算什么?
- 神经元节点先计算激活函数,再计算线性函数(z = Wx + b)
- 神经元节点先计算线性函数(z = Wx + b),再计算激活。
- 神经元节点计算函数g,函数g计算(Wx + b)。
- 在 将输出应用于激活函数之前,神经元节点计算所有特征的平均值
(2)
2.下面哪一个是Logistic损失?
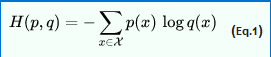
3. 假设img是一个(32,32,3)数组,具有3个颜色通道:红色、绿色和蓝色的32×32像素的图像。 如何将其重新转换为列向量?
x = img.reshape(32*32*3,1)4. 下面的这两个随机数组“a”和“b”, 请问数组c的维度是多少?
a = np.random.randn(2, 3) # a.shape = (2, 3)
b = np.random.randn(2, 1) # b.shape = (2, 1)
c = a + b(2,3)
5. 下面的这两个随机数组“a”和“b” ,请问数组“c”的维度是多少?
a = np.random.randn(4, 3) # a.shape = (4, 3)
b = np.random.randn(3, 2) # b.shape = (3, 2)
c = a * b无法计算。因为a、b两个矩阵维度不同。.
6. 假设你的每一个实例有n_x个输入特征,想一下在X=[x^(1), x^(2)…x^(m)]中,X的维度是多少?
(n_x,m)。将输入特征转化为列向量,然后叠加m个。
7. 看一下下面的这两个随机数组“a”和“b” 请问c的维度是多少?
a = np.random.randn(12288, 150) # a.shape = (12288, 150)
b = np.random.randn(150, 45) # b.shape = (150, 45)
c = np.dot(a, b)(12288,45)。dot是矩阵点乘(矩阵乘法)。
8. 看一下下面的这个代码片段, 请问要怎么把它们向量化?
# a.shape = (3,4)
# b.shape = (4,1)
for i in range(3):
for j in range(4):
c[i][j] = a[i][j] + b[j]c = a + b.T9. 下面的代码 请问c的维度会是多少?
a = np.random.randn(3, 3)
b = np.random.randn(3, 1)
c = a * b(3,3)。由于广播机制,b会被扩展成(3,3)然后执行矩阵元素相乘。
编程作业
我们在这一节要做的就是写一个能够识别猫的神经网络,其实说是神经网络,本质上就是一个逻辑回归加上一个参数b,本质上都是一个ax+b的二分类问题。
这块说明的比较少,因为总体上和逻辑回归蛮像的,就是差了个权重b。
首先导包:
import numpy as np
import matplotlib.pyplot as plt
import h5py
from lr_utils import load_dataset然后我们初始化数据
train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = load_dataset()我们查看一下图片数据并简单查看一下数据:
# 查看一下图片
plt.imshow(train_set_x_pic[0])
plt.show()
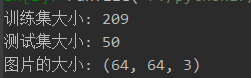
print('训练集大小:', train_set_x_pic.shape[0])
print('测试集大小:', test_set_x_pic.shape[0])
print('图片的大小:', train_set_x_pic.shape[1:])
输出如下:
然后做一些简单的数据预处理,比如将所有的图片RGB数据组成成一维的并进行标准化。
train_set_x_flatten = train_set_x_pic.reshape(train_set_x_pic.shape[0], -1).T
test_set_x_flatten = test_set_x_pic.reshape(test_set_x_pic.shape[0], -1).T
# 标准化RGB颜色,因此原值范围较大,标准化到0~1之间
train_set_x = train_set_x_flatten / 255
test_set_x = test_set_x_flatten / 255
然后就是几个需要用到的方法,
首先是激活函数sigmoid函数
def sigmoid(z):
"""
sigmoid函数
:param z:
:return:
"""
return 1 / (1 + np.exp(-z))
然后是前向传播和反馈的方法
def propagate(w, b, X, Y):
"""
前后传播以及成本计算
:param w:
:param b:
:param X:
:param Y:
:return:
"""
n = X.shape[1]
# 计算代价
A = sigmoid(np.dot(w.T, X) + b)
cost = np.mean(-Y * np.log(A) - (1 - Y) * np.log(1 - A))
# 反向传播
dw = (1 / n) * (X @ (A - Y).T)
db = (1 / n) * np.sum(A - Y)
return dw, db, cost
然后是调用n次传播以获取一个比较好的结果:
def optimize(w, b, X, Y, iterations_times, learning_rate, print_cost=False):
"""
运行梯度下降来优化w和b
:param w:
:param b:
:param X:
:param Y:
:param iterations_times:
:param learning_rate:
:param print_cost:
:return:
"""
costs = []
for i in range(iterations_times):
wb, db, cost = propagate(w, b, X, Y)
w = w - learning_rate * wb
b = b - learning_rate * db
# 记录成本
if i % 100 == 0:
costs.append(cost)
if print_cost and i % 100 == 0:
print('迭代次数:%i,误差值:%f' % (i, cost))
return w, b, costs
预测函数:
def predict(w, b, X):
"""
预测
:param w:
:param b:
:param X:
:return:
"""
n = X.shape[1]
Y_prediction = np.zeros((1, n))
A = sigmoid((w.T @ X) + b)
for i in range(A.shape[1]):
Y_prediction[0, i] = 1 if A[0, i] > 0.5 else 0
return Y_prediction
将所有的方法整合起来,方便调用:
def model(X_train, Y_train, X_test, Y_test, num_iterations=2000, learning_rate=0.01, print_cost=True):
"""
总体模型
:param X_train:
:param Y_train:
:param X_test:
:param Y_test:
:param num_iterations:
:param learning_rate:
:param print_cost:
:return:
"""
w, b = init_weight(X_train.shape[0])
wb, db, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost)
Y_prediction_test = predict(wb, db, X_test)
print('训练集准确率:', (1 - (np.mean(np.abs(Y_prediction_test - Y_test)))) * 100, '%')
return wb, db, costs
最后我们来调用一下看看
d = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations=2000, learning_rate=0.005, print_cost=True)
可以看到输出如下:
完整代码:
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import h5py
from course_1_week_2.lr_utils import load_dataset
# 训练集图片, 训练集标签, 测试集图片,测试集标签,分类标签文本描述
train_set_x_pic, train_set_y, test_set_x_pic, test_set_y, classes = load_dataset()
# 查看一下图片
plt.imshow(train_set_x_pic[0])
plt.show()
print('训练集大小:', train_set_x_pic.shape[0])
print('测试集大小:', test_set_x_pic.shape[0])
print('图片的大小:', train_set_x_pic.shape[1:])
train_set_x_flatten = train_set_x_pic.reshape(train_set_x_pic.shape[0], -1).T
test_set_x_flatten = test_set_x_pic.reshape(test_set_x_pic.shape[0], -1).T
# 标准化RGB颜色,因此原值范围较大,标准化到0~1之间
train_set_x = train_set_x_flatten / 255
test_set_x = test_set_x_flatten / 255
def sigmoid(z):
"""
sigmoid函数
:param z:
:return:
"""
return 1 / (1 + np.exp(-z))
def init_weight(dim):
"""
初始化维度
:param dim:
:return:
"""
w = np.zeros((dim, 1))
b = 0
return w, b
def propagate(w, b, X, Y):
"""
前后传播以及成本计算
:param w:
:param b:
:param X:
:param Y:
:return:
"""
n = X.shape[1]
# 计算代价
A = sigmoid(np.dot(w.T, X) + b)
cost = np.mean(-Y * np.log(A) - (1 - Y) * np.log(1 - A))
# 反向传播
dw = (1 / n) * (X @ (A - Y).T)
db = (1 / n) * np.sum(A - Y)
return dw, db, cost
def optimize(w, b, X, Y, iterations_times, learning_rate, print_cost=False):
"""
运行梯度下降来优化w和b
:param w:
:param b:
:param X:
:param Y:
:param iterations_times:
:param learning_rate:
:param print_cost:
:return:
"""
costs = []
for i in range(iterations_times):
wb, db, cost = propagate(w, b, X, Y)
w = w - learning_rate * wb
b = b - learning_rate * db
# 记录成本
if i % 100 == 0:
costs.append(cost)
if print_cost and i % 100 == 0:
print('迭代次数:%i,误差值:%f' % (i, cost))
return w, b, costs
def predict(w, b, X):
"""
预测
:param w:
:param b:
:param X:
:return:
"""
n = X.shape[1]
Y_prediction = np.zeros((1, n))
A = sigmoid((w.T @ X) + b)
for i in range(A.shape[1]):
Y_prediction[0, i] = 1 if A[0, i] > 0.5 else 0
return Y_prediction
def model(X_train, Y_train, X_test, Y_test, num_iterations=2000, learning_rate=0.01, print_cost=True):
"""
总体模型
:param X_train:
:param Y_train:
:param X_test:
:param Y_test:
:param num_iterations:
:param learning_rate:
:param print_cost:
:return:
"""
w, b = init_weight(X_train.shape[0])
wb, db, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost)
Y_prediction_test = predict(wb, db, X_test)
print('训练集准确率:', (1 - (np.mean(np.abs(Y_prediction_test - Y_test)))) * 100, '%')
return wb, db, costs
d = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations=2000, learning_rate=0.005, print_cost=True)
0 条评论