吴恩达深度学习 第三课第一周 机器学习(ML)策略(1)

1.为什么是ML策略?
当我们当前的网络表现并没有达到我们预期的效果时,我们应该怎么办呢?我们可以有很多的选择, 比如
- 收集更多的训练数据
- 收集更多不同姿势的猫咪图片,或者更多样化的反例集。
- 训练久一点。
- 尝试用一个完全不同的优化算法,比如Adam优化算法。
- 尝试使用规模更大或者更小的神经网络
- dropout或者正则化
- 修改网络的架构
- 修改激活函数
- 改变隐藏单元的数目之类
等等,那么在众多的选择中毫无疑问的有重要的,也有相对不那么重要的,因此怎么选择下一步需要干什么就是接下来两周的内容。
2.正交化
我们举个两个例子,一个是老式电视,一个是汽车来说明正交化的必要性。
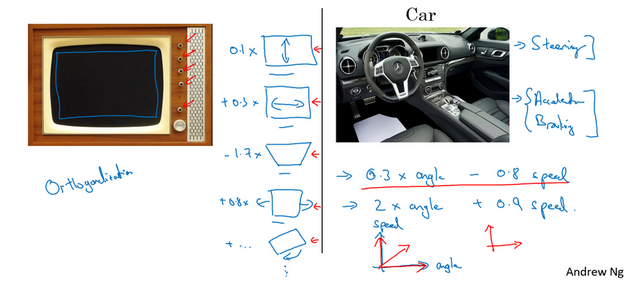
假如电视上的各种按钮分别又调整图像长宽提醒比整体长宽还有图像旋转6个按钮,那么我们基本上不能或者很难将图像调整到一个合适的位置。
同理,如果我们现在的汽车不再使用方向盘来控制方向,也不使用刹车油门来控制速度,而是使用两个 按钮,一个是0.2*angle-0.8*speed,一个是2*angle+0.9*speed,那么我们可以用这两个按钮来完成任何想要的速度和方向,但是操作的难度则会大大增加。
因此我们需要引入两个正交的变量,对彼此互不影响,每一个变量的改变只会对一个方向进行改变。
3.单一数字评估指标
提前说两个定义:查准率(precision)和查全率(recall)。
查准率就是当前网络在整个数据集(正向负向均有)中对结果的准确度,而查全率则是对于正向数据有多少概率判断正确。
现在有如下两个网络:
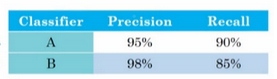
对于怎么评价这两个网络的表现,我们引入新的变量F1

计算得:

因此我们可以看到,A网络的表现是优于B网络的。
4.满足和优化指标
对于如下几个网络:
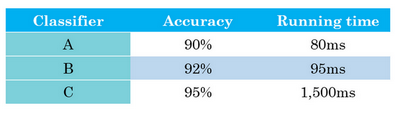
我们可以看到对于C网络效果很好,但是运行时间比较慢,因此假如我们有一个在100ms内运行完成的指标,我们就应该选择B网络。
类似的,如果对于图片分类,虽然网络错误率只有3%但是有时候会出现将xx图片识别为目标分类,这是不被允许的,因此也不应该是首选。
5.训练/开发/测试集划分
之前已经讲过了,不再赘述(【吴恩达深度学习】深度学习的实用层面)
同时需要注意比如多颜色的猫应该在训练开发测试集中均匀分布。
6. 为什么是人的表现?
由于众所周知的原因,问题的准确度不可能达到100%,因此我们将这个最高的理论上限成为贝叶斯最优错误率,如下图,当网络的性能在人类以下时增长很快,因为可以有很多手段来帮助它变得更好,但是当超过人类之后就很艰难的上升直至逼近贝叶斯最优错误率。
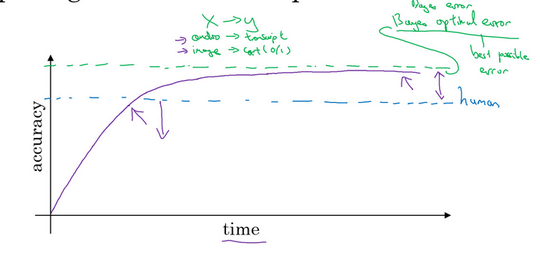
7.可避免偏差
我们考虑如下网络结果:

比如识别某一类事物,人类的错误率只有1%而网络错误率达到了8%,这时候我们需要考虑的是使网络更加准确,考虑的是偏差问题,因此应该向着降低偏差的方向处理。
而对于下图:

我们人类错误率接近训练集错误率的8%,因此这时候我们就需要将注意力放在训练集和交叉验证集这2%的错误率差距上,开始将注意力放在方差上,进行防止过拟合的操作。
测验
现在你是和平之城的著名研究员,和平之城的人有一个共同的特点:他们害怕鸟类。为了保护他们,你必须设计一个算法,以检测飞越和平之城的任何鸟类,同时警告人们有鸟类飞过。市议会为你提供了10,000,000张图片的数据集,这些都是从城市的安全摄像头拍摄到的。它们被命名为:
- y = 0: 图片中没有鸟类
- y = 1: 图片中有鸟类
你的目标是设计一个算法,能够对和平之城安全摄像头拍摄的新图像进行分类。
1. 市议会告诉你,他们想要一个算法
- 拥有较高的准确度
- 快速运行,只需要很短的时间来分类一个新的图像
- 可以适应小内存的设备,这样它就可以运行在一个小的处理器上,它将用于城市的安全摄像头上
有三个评估指标使您很难在两种不同的算法之间进行快速选择,并且会降低您的团队迭代的速度,是真的吗?
正确。
2. 经过进一步讨论,市议会缩小了它的标准:
- “我们需要一种算法,可以让我们尽可能精确的知道一只鸟正飞过和平之城。”
- “我们希望经过训练的模型对新图像进行分类不会超过10秒。”
- “我们的模型要适应10MB的内存的设备.”
如果你有以下几个模型,你会选择哪一个?
- 准确率97% 运行时间1sec 内存大小3MB
- 准确率99% 运行时间13sec 内存大小9MB
- 准确率97% 运行时间3sec 内存大小2MB
- 准确率98% 运行时间9sec 内存大小9MB
4。
3.根据城市的要求,您认为以下哪一项是正确的?
- 准确度是一个优化指标; 运行时间和内存大小是令人满意的指标。
- 准确度是一个令人满意的指标; 运行时间和内存大小是一个优化指标。
- 准确性、运行时间和内存大小都是优化指标,因为您希望在所有这三方面都做得很好。
- 准确性、运行时间和内存大小都是令人满意的指标,因为您必须在三项方面做得足够好才能使系统可以被接受。
1。
4. 在实现你的算法之前,你需要将你的数据分割成训练/开发/测试集,你认为哪一个是最好的选择?
- 训练集 3,333,334 开发集 3,333,333 测试集 3,333,333
- 训练集 6,000,000 开发集 3,000,000 测试集 1,000,000
- 训练集 9,500,000 开发集 250,000 测试集 250,000
- 训练集 6,000,000 开发集 1,000,000 测试集 3,000,000
3。
5. 在设置了训练/开发/测试集之后,市议会再次给你了1,000,000张图片,称为“公民数据”。 显然,和平之城的公民非常害怕鸟类,他们自愿为天空拍照并贴上标签,从而为这些额外的1,000,000张图像贡献力量。 这些图像与市议会最初给您的图像分布不同,但您认为它可以帮助您的算法。
你不应该将公民数据添加到训练集中,因为这会导致训练/开发/测试集分布变得不同,从而损害开发集和测试集性能,是真的吗?
错误。
6. 市议会的一名成员对机器学习知之甚少,他认为应该将1,000,000个公民的数据图像添加到测试集中,你反对的原因是:
- 这会导致开发集和测试集分布变得不同。这是一个很糟糕的主意,因为这会达不到你想要的效果。
- 公民的数据图像与其他数据没有一致的x- >y映射(类似于纽约/底特律的住房价格例子)。
- 一个更大的测试集将减慢迭代速度,因为测试集上评估模型会有计算开销。
- 测试集不再反映您最关心的数据(安全摄像头)的分布。
1,4。
7. 你训练了一个系统, 训练集误差 4.0%,开发集误差4.5%, 这表明,提高性能的一个很好的途径是训练一个更大的网络,以降低4%的训练误差。你同意吗?
- 是的,因为有4%的训练误差表明你有很高的偏差。
- 是的,因为这表明你的模型的偏差高于方差。
- 不同意,因为方差高于偏差。
- 不同意,因为没有足够的信息,这什么也说明不了。
4。
8. 你让一些人对数据集进行标记,以便找出人们对它的识别度。你发现了准确度如下: 鸟类专家1:0.3%,鸟类专家2:0.5%,普通人1:1.0%,普通人2:1.2%, 如果您的目标是将“人类表现”作为贝叶斯错误的基准线(或估计),那么您如何定义“人类表现”?
- 0.0% (因为不可能做得比这更好)
- 0.3% (专家1的错误率)
- 0.4% (0.3 到 0.5 之间)
- 0.75% (以上所有四个数字的平均值)
2。
9. 您同意以下哪项陈述?
- 学习算法的性能可以优于人类表现,但它永远不会优于贝叶斯错误的基准线。
- 学习算法的性能不可能优于人类表现,但它可以优于贝叶斯错误的基准线。
- 学习算法的性能不可能优于人类表现,也不可能优于贝叶斯错误的基准线。
- 学习算法的性能可以优于人类表现,也可以优于贝叶斯错误的基准线。
1。
10. 你发现一组鸟类学家辩论和讨论图像得到一个更好的0.1%的性能,所以你将其定义为“人类表现”。在对算法进行深入研究之后,最终得出以下结论: 人类表现 0.1%、训练集误差2.0%、开发集误差2.1%。 根据你的资料,以下四个选项中哪两个尝试起来是最有希望的?
- 尝试增加正则化。
- 获得更大的训练集以减少差异。
- 尝试减少正则化。
- 训练一个更大的模型,试图在训练集上做得更好。
3,4。
11. 你在测试集上评估你的模型,并找到以下内容: 人类表现:0.1%、训练集误差2.0%、开发集误差:2.1%、测试集误差:7.0%, 这意味着什么?
- 你没有拟合开发集
- 你应该尝试获得更大的开发集。
- 你应该得到一个更大的测试集。
- 你对开发集过拟合了。
2,4。
12. 在一年后,你完成了这个项目,你终于实现了: 人类表现:0.1%、训练集误差0.05%、开发集误差:0.05%,你能得到什么结论?
- 现在很难衡量可避免偏差,因此今后的进展将会放缓。
- 统计异常(统计噪声的结果),因为它不可能超过人类表现。
- 只有0.09%的进步空间,你应该很快就能够将剩余的差距缩小到0%
- 如果测试集足够大,使得这0.05%的误差估计是准确的,这意味着贝叶斯误差是小于等于0.05的。
1,4。
13.事实证明,和平之城也雇佣了你的竞争对手来设计一个系统。您的系统和竞争对手都被提供了相同的运行时间和内存大小的系统,您的系统有更高的准确性。然而,当你和你的竞争对手的系统进行测试时,和平之城实际上更喜欢竞争对手的系统,因为即使你的整体准确率更高,你也会有更多的假阴性结果(当鸟在空中时没有发出警报)。你该怎么办?
- 查看开发过程中开发的所有模型,找出错误率最低的模型。
- 要求你的团队在开发过程中同时考虑准确性和假阴性率。
- 重新思考此任务的指标,并要求您的团队调整到新指标。
- 选择假阴性率作为新指标,并使用这个新指标来进一步发展。
3。
14.你轻易击败了你的竞争对手,你的系统现在被部署在和平之城中,并且保护公民免受鸟类攻击! 但在过去几个月中,一种新的鸟类已经慢慢迁移到该地区,因此你的系统的性能会逐渐下降,因为您的系统正在测试一种新类型的数据。你只有1000张新鸟类的图像,在未来的3个月里,城市希望你能更新为更好的系统。你应该先做哪一个?
- 使用所拥有的数据来定义新的评估指标(使用新的开发/测试集),同时考虑到新物种,并以此来推动团队的进一步发展。
- 把1000张图片放进训练集,以便让系统更好地对这些鸟类进行训练。
- 尝试数据增强/数据合成,以获得更多的新鸟的图像。
- 将1,000幅图像添加到您的数据集中,并重新组合成一个新的训练/开发/测试集
1。
15.市议会认为在城市里养更多的猫会有助于吓跑鸟类,他们对你在鸟类探测器上的工作感到非常满意,他们也雇佣你来设计一个猫探测器。(哇~猫探测器是非常有用的,不是吗?)由于有多年的猫探测器的工作经验,你有一个巨大的数据集,你有100,000,000猫的图像,训练这个数据需要大约两个星期。你同意哪些说法?(检查所有选项。)
- 需要两周的时间来训练将会限制你迭代的速度。
- 购买速度更快的计算机可以加速团队的迭代速度,从而提高团队的生产力。
- 如果100,000,000个样本就足以建立一个足够好的猫探测器,你最好用100,000,00个样本训练,从而使您可以快速运行实验的速度提高约10倍,即使每个模型表现差一点因为它的训练数据较少。
- 建立了一个效果比较好的鸟类检测器后,您应该能够采用相同的模型和超参数,并将其应用于猫数据集,因此无需迭代。
1,2,3。
0 条评论