命名实体识别
命名实体识别(Named Entity Recognition,NER),它是自然语言处理中的一项基础任务,应用范围非常广泛。
命名实体一般是文中具有特定意义或者指代性强的实体,通常包括:人名、地名、组织机构名、日期时间、专有名词等。
NER系统就是从结构化的输入文本中抽取出上述实体,并且可以按照业务需求识别出更多类别的实体,比如产品名称、型号、价格等。
在学术上NER所涉及的命名实体一般包括三大类(实体类、时间类、数字类)和七小类(人名、地名、组织机构名、时间、日期、货币、百分比)。
同时NER也是关系抽取、时间抽取、知识图谱、机器翻译、问答系统等诸多NLP任务的基础。
中文命名实体识别的挑战
1.没有明确的界限(英文单词以空格为界限)。
2.不像英文有大小写的形态指示(比如专属名词首字母大写)。
3.中文用字灵活多变,有些词在脱离上下文语境情况下无法判断是否是命名实体且在不同的上下文语境中可能是不同的实体类型。
4.命名实体存在嵌套现象。如‘大连理工大学软件学院’,在该实体中嵌套了其他机构名‘大连理工大学’。
5.中文里广泛存在简化表达,如大工、医科大等。
数据集标注方式
BIO标注集:
- B-PER、I-PER代表人名首字、人名非首字。
- B-LOC、I-LOC代表地名首字、地名非首字。
- B-ORG、I-ORG代表组织机构名首字、组织机构名非首字。
- O代表该字不属于命名实体的一部分。
BIOSE标注集 :
- B-PER、I-PER、E-PER代表人名首字、人名中间字、人名末尾字。
- B-LOC、I-LOC、E-PER代表地名首字、地名中间字、地名末尾字。
- B-ORG、I-ORG、E-PER代表组织机构名首字、组织机构名中间字、 组织机构名末尾字。
- S-X代表单字构成的实体。
- O代表该字不属于命名实体的一部分。
隐马尔科夫模型(HMM)
隐马尔可夫模型(Hidden Markov Model,HMM)描述由隐藏的马尔可夫链 随机生成观测序列的过程,属于生成模型。
HMM是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观 测的状态随机序列(状态序列),再由各个状态生成一个观测而产生的观测随 机序列(观测序列)的过程,隐马尔可夫模型由初始状态分布,状态转移概率 矩阵以及观测概率矩阵所确定。
NER本质上可以看成是一种序列标注问题(预测每个字的BIOES标记),在使 用HMM解决NER这种序列标注问题的时候,我们所能观测到的是字组成的序 列(观测序列),观测不到的是每个字对应的标注(状态序列)。
CRF(条件随机场)
上面讲的HMM模型中存在两个假设
- 输出观察值之间严格独立;
- 状态转移过程中当前状态只与前一状态有关;
也就是说,在命名实体识别的场景下,HMM认为观测到的句子中的每 个字都是相互独立的,而且当前时刻的标注只与前一时刻的标注相关。 但实际上,命名实体识别往往需要更多的特征,比如词性,词的上下文 等等,同时当前时刻的标注应该与前一时刻以及后一时刻的标注都相关 联。由于这两个假设的存在,显然HMM模型在解决命名实体识别的问 题上是存在缺陷的。
而条件随机场就没有这种问题,它通过引入自定义的特征函数,不仅可 以表达观测之间的依赖,还可表示当前观测与前后多个状态之间的复杂 依赖,可以有效克服HMM模型面临的问题。
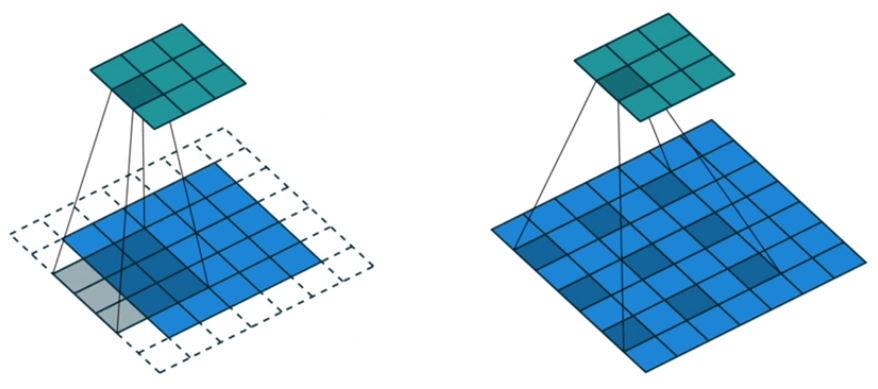
膨胀卷积神经网络(Dilation)
膨胀卷积的好处是:不做polling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者自然语言处理中需要较长的序列信息依赖问题中,有很好的应用。
代码详见:
0 条评论