最近在手写Transformer,有了一些理解,之前虽然感觉自己理论(Transformer理论图解)都理解了,但是写出来依然发现有很多地方不太明白,弄明白之后写出来记录一下。
先记录一下手写的一些细节吧,最后会贴上完整的github链接。
首先就是Transformer的结构,左侧的encoder层和右侧的decoder层,实际的Transformer的encoder和decoder就是由N个encoder层和N个docoder层组成。
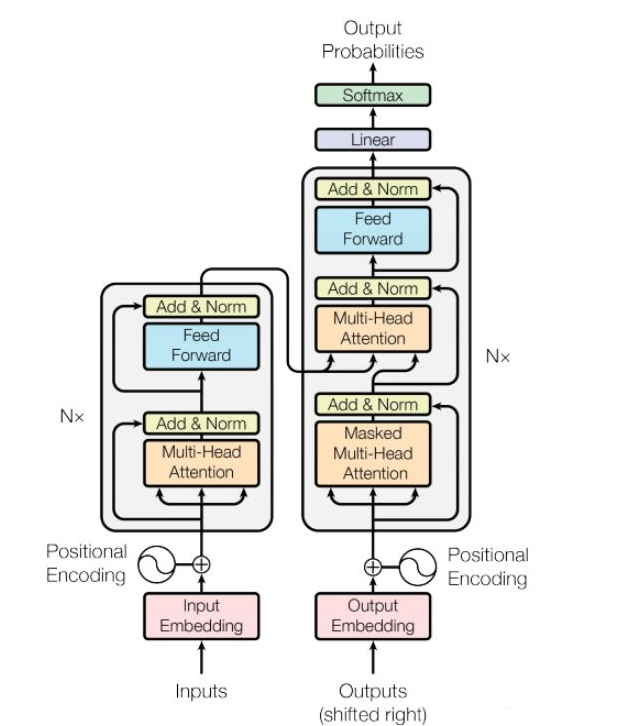
我们继续观察模型,发现多头注意力(注意力基础、注意力理论图解)有两种,一种就是单纯的Multi-Head Attention,另一种是Masked Multi-Head Attention。
那么这两种多头注意力机制有什么区别呢,很显然,就是Mask机制。
这个Mask机制实际上是一个遮蔽机制,由于Transformer的并行要求(事实上这也是Transformer相比RNN的一大优势),需要将target进行embedding然后输入到decoder中,因此就需要使用一个机制,屏蔽掉当前预测位及其之后的文本,比如:输出文本是“ 我爱你 ”,那么在预测“ 爱 ”的时候,当前网络应该只可见“我”字。
那么是怎么做的呢?就是使用一个下三角矩阵,由于最终的embedding的文本还要有开始标记(“<BOS> 我 爱 你 <EOS>”),因此对于这句话的5*5的下三角矩阵,正好可以遮蔽掉预测字后面的字,比如矩阵第二行有2个1,因此只有“ <BOS> 我 ”对网络可见,并试图使网络预测“爱”。
除此之外还有一个mask,就是要mask掉padding,由于对于短文本,我们需要将文本padding到定长,我们并不需要注意力机制关注这部分padding信息,因此我们同样可以使用mask机制强行清空注意力结果(乘0或一个极小的数字)。
详见 Multi-Head Attention 代码。
import tensorflow as tf
class MutiHeadAttention(tf.keras.layers.Layer):
"""
多头注意力
"""
def __init__(self, d_model, num_heads):
"""
:param d_model: muti attn 输出的维度
:param num_heads: 多头个数
"""
super().__init__()
assert d_model % num_heads == 0
self.num_heads = num_heads
self.d_model = d_model
self.deep = self.d_model // self.num_heads
self.WQ = tf.keras.layers.Dense(self.d_model)
self.WK = tf.keras.layers.Dense(self.d_model)
self.WV = tf.keras.layers.Dense(self.d_model)
self.dense = tf.keras.layers.Dense(self.d_model)
def split_heads(self, x, batch_size):
"""
分头,
:param x:
:param batch_size:
:return:
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.deep))
# perm 是新的维度索引,假如x维度是[1,2,3,4],perm=[0,2,1,3]转置后x维度将变成[1,3,2,4]
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, q, k, v, mask):
batch_size = tf.shape(q)[0]
q = self.WQ(q)
k = self.WK(k)
v = self.WV(v)
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
attention_output, attention_weight = dot_attention(q, k, v, mask)
attention_output = tf.transpose(attention_output, perm=[0, 2, 1, 3])
attention_output = tf.reshape(attention_output, (batch_size, -1, self.d_model))
_output = self.dense(attention_output)
return _output, attention_weight
#
#
def dot_attention(q, k, v, mask):
"""
点乘
:param q:
:param k:
:param v:
:param mask:
:return:
"""
qk = tf.matmul(q, k, transpose_b=True)
# 计算根号下dk对qk进行缩放,类似于 emm 归一化
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = qk / tf.math.sqrt(dk)
if mask is not None:
scaled_attention_logits += (mask * -1e9)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
_output = tf.matmul(attention_weights, v)
return _output, attention_weights
其他的encoder层、deocder层、以及最终的encoder、deocder这里不再描述,不是很复杂。
到这里其实还好,下面的问题一度让我怀疑我的理解出了很大的问题。
都写完之后,我想测试一下这个模型的效果,于是继续手写了一下测试,但是发现了一个问题,训练阶段传的target,在测试阶段传什么?如果只传<BOS>,那么最终的结果将天花乱坠,并且再预测阶段传完整的target也就没有意义了。
经过一段时间的研究发现,Transformer的测试阶段依然需要n次模型迭代,就类似于RNN,用n-1次得输出,作为output target,传入n次,由模型预测第n个词。
这是由于Transformer的teaching force决定的,因此在Transformer的训练和测试中就存在一个gap。
虽然知道之后感觉挺简单的,但是当时确实困惑了好久,也算掌握了一个新知识,写下来 记录一下。
0 条评论