汇总用过或者见过的一些比较新奇的bert变种。
- roberta
- xxx wwm
- albert
- nezha
- WoBert(WoNEZHA)
- ELECTRA
- xxx ext
- MacBert
- RoFormer
1.RoBerta:
在Bert的基础上继续进行微调,包括更改部分超参,进行跟多的训练。
可以把Bert当作未训练完全的RoBerta,反之一样。
1.使用了动态mask
相比Bert的固定mask(同一条数据的不同批次mask的位置一样),RoBerta使用了动态mask,提升了效果。
2.预训练任务变更
将效果不太好的NSP(Next Sentence Predict)任务换成了Full-Sentence,也即是将句子尽可能的填满512个长度,在最后加一个句子间隔标识符,而不是Sentence <SEP> Sentence。
3. 更大的batch size
2.XXX WWM
Bert的全字掩码版本(whole word masking)。他减轻了预训练过程中掩码不分word pirce的弊端。
比如:playing在token部分会被分为play和##ing,而原生bert会随机的mask play或者##ing或者两者全部mask,而wwm则只会mask两者。
3.Albert
Bert的变种,使用了Bert 70%的参数,超过了Bert的性能。但是虽然减少了参数,推理性能依然和bert不相上下(bert large的速度为albert xxlarge的1.2倍)。
1.压缩了词嵌入大小
bert的词嵌入大小为768,最终的输出也为768,而词嵌入并不包含那么多信息,最终的输出则需要包含上下文信息,因此有一种直觉就是词嵌入可以变小。
因此albert通过将词嵌入变小,通过映射到768维,因此缩小了词嵌入部分参数大小。
比如:词典3w个,位置编码512长。
Bert为(30000+512)=768=23,433,216
Albert为(30000+512)*128+128*768=4,003,840。
节省了19429376个参数,也就是19M。
2.参数跨层共享
Albert通过共享参数达到缩小参数的目的。
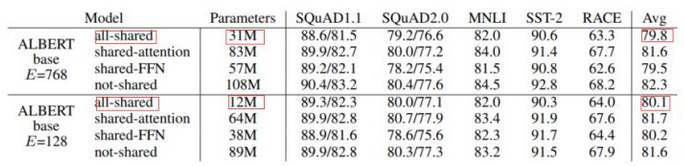
可以看到共享注意力的效果最好,但是出于“共享”的原则,最终的albert连FFN也一起共享了。
3.预训练任务变更
Albert依然更改了Bert的预训练任务,将NSP(Next Sentence Predict)任务换为了更有挑战的SOP(Sentences Order Predict)任务。
将预测两个句子是否连续变为判断两个句子是否被交换顺序(这要求模型对语义具有更好的了解)。
4.NEZHA
华为开源的预训练语言模型,全称为“ NEural contextualiZed representation for CHinese lAnguage understanding ”。
1.增加相对位置编码函数
Bert中学习了绝对位置编码,Transformer中也是用了函数式编码。
NEZHA通过在注意力机制中引入相对位置的概念,提升了在NER等任务中的效果。
2.全词掩码
3.混合精度训练
在训练过程中的每一个step,为模型的所有weight维护一个FP32的copy,称为Master Weights;在做前向和后向传播过程中,Master Weights会转换成FP16(半精度浮点数)格式,其中权重、激活函数和梯度都是用FP16进行表示,最后梯度会转换成FP32格式去更新Master Weights。
由于float16的运算速度大于float32,因此能够显著提升训练速度。
4.优化器改进
NEZHA使用了《 Large Batch Optimization for Deep Learning:Training BERT in 76 minutes》的一个优化器,它可以将预训练bert时间从三天降到76分钟。
5.WoBert(WoNEZHA)
追一科技开源的词级别Bert(nezha)
相比bert(nezha)采用字符级不同,wobert(wobert)采用的是词级别token,因此对于相同的序列长度拥有更快的速度(词比句短)。
该模型从哈工大的roberta中进行蒸馏随后进行词级别预训练。
6.ELECTRA
详见 ELECTRA
7.XXXXX ext
各种ext,比如bert wwm ext,bert base ext等等。
由哈工大讯飞联合实验室发布的中文预训练语言模型,主要改进如下:
- 预训练数据集做了增加,达到5.4B;
- 训练步数增大,训练第一阶段1M步,训练第二阶段400K步。
8.MacBert
该模型通过用相似的单词mask,减轻了预训练和微调阶段两者之间的差距。
相比Bert,改模型采用了WWM(whole word mask) 和 NM(N-gram mask)结合的方式。同时将NSP任务替换为了SOP(sentence order predict)任务。
对于Mask任务,MacBert做了一些比较大的改动:
不使用[MASK]token进行mask,因为在token微调阶段从未出现过[MASK]。转而使用类似的单词进行masking。 通过使用基于word2vec相似度计算的同义词工具包获得相似的单词。 如果选择一个N-gram进行masked,我们将分别找到相似的单词。 在极少数情况下,当没有相似的单词时,我们会降级以使用随机单词替换。
最终,对15%比例的输入单词进行masking,其中80%替换为相似的单词,10%将替换为随机单词,其余10%则保留原始单词。
9.Roformer
苏建林提出的一个新的position embedding方式:RoPE。通过使用乘性位置编码,从而将相对位置编码与绝对位置编码统一的方式。
最妙的点就是这个乘性位置编码,使得它具体很好的物理性质:因为乘性和复数的形式,这种位置编码实际上可以看做是一个二维向量的旋转变化矩阵。而对于attention的内积,这时候可以看做是做了另一个旋转变化,更妙的是它的位置编码是一个正交矩阵,并不会破坏模长。所以这种位置编码,可以看做是一个token根据当前m的位置编码,进行旋转,与n位置的token点乘的时候,再根据n的位置编码进行旋转,而最终点乘完之后的旋转角只和m-n相关
知乎 飞奔的啦啦啦
图例:
而著名团队EleutherAI也对RoPE做出了一些实验,结果表明,RoPE能够较为明显的改善模型性能以及困惑度。
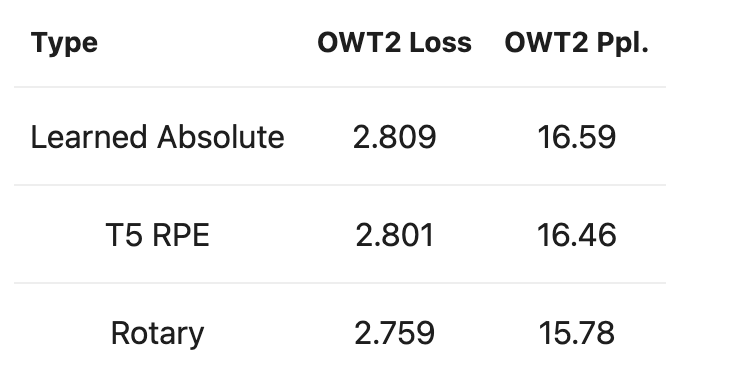
具体详见Rotary Embeddings: A Relative Revolution
不过目前从我们在ECISA中的使用来看,Roformer并没有什么提升。当然,我的对比实验较少,并不能证明什么。
0 条评论