最近打了一个比赛,算是第一次比较认真系统的打比赛,搞了两个月,最后A榜第一,B榜第四,也算还行,写个笔记总结一下。
任务描述如下:
本届中文隐式情感分析评测任务为中文隐式情感句识别与情感分类。任务描述如下:
文本情感分析是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。从文本的语言表达层面,依照是否含有显式情感词,可分为显式情感分析和隐式情感分析。显式文本情感分析作为该领域的基础性研究,已有大量的相关研究成果。然而,在日常表达中,人们在对客观事物体验及其行为所反映出的情感是丰富而抽象的,除采用显式情感词表达情感外,还采用客观陈述或者修辞方式来隐式地表达自己的情感。根据我们对收集的文本数据的标注结果,隐式情感句占总情感句的15%-20%左右。
【中文隐式情感句示例】
例1 你们公司一年的销售额也赶不上我们一个月的。(贬义隐式情感)
例2 有种活着诗里的感觉:烟笼寒水月笼沙,夜泊秦淮近酒家。(褒义隐式情感)
例3 我去的时候,客栈标间大多开价100元一间,还价到70元住下。(不含情感)
数据集以xml形式发布,格式为:
<Doc ID="5">
<Sentence ID="1">因为你是老太太</Sentence>
<Sentence ID="2" label="1">看完了,满满的回忆,很多那个时代的元素</Sentence>
</Doc>带有label=”1″标记的标注句子,含有完整的上下文,标签为:0-不含情感,1-褒义隐式情感,2-贬义隐式情感。
1.数据分析与处理
数据分析
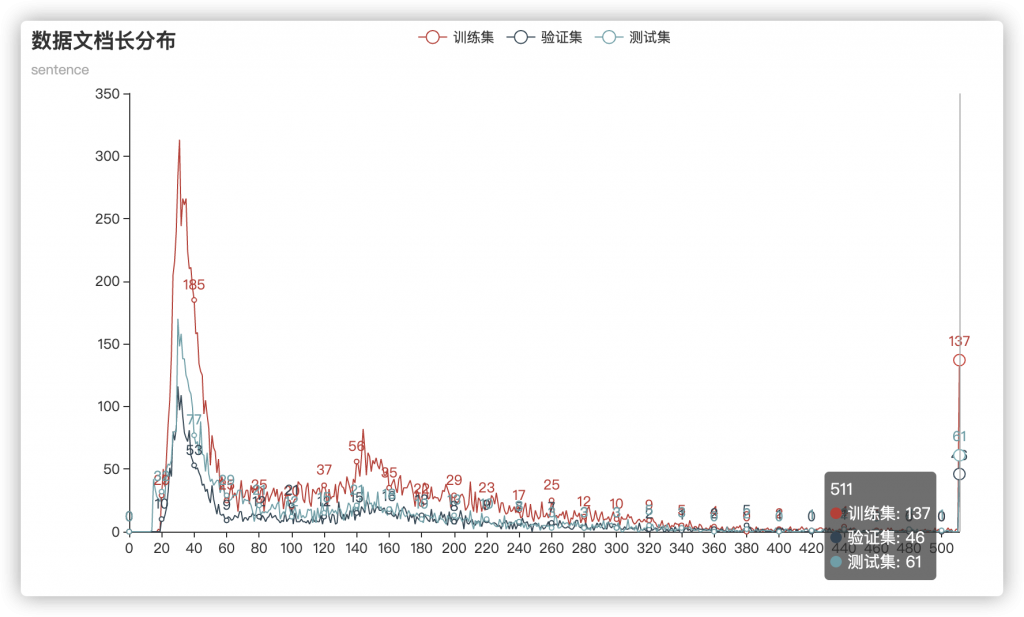
首先进行数据分析,分析了一下句子长度频率分布:
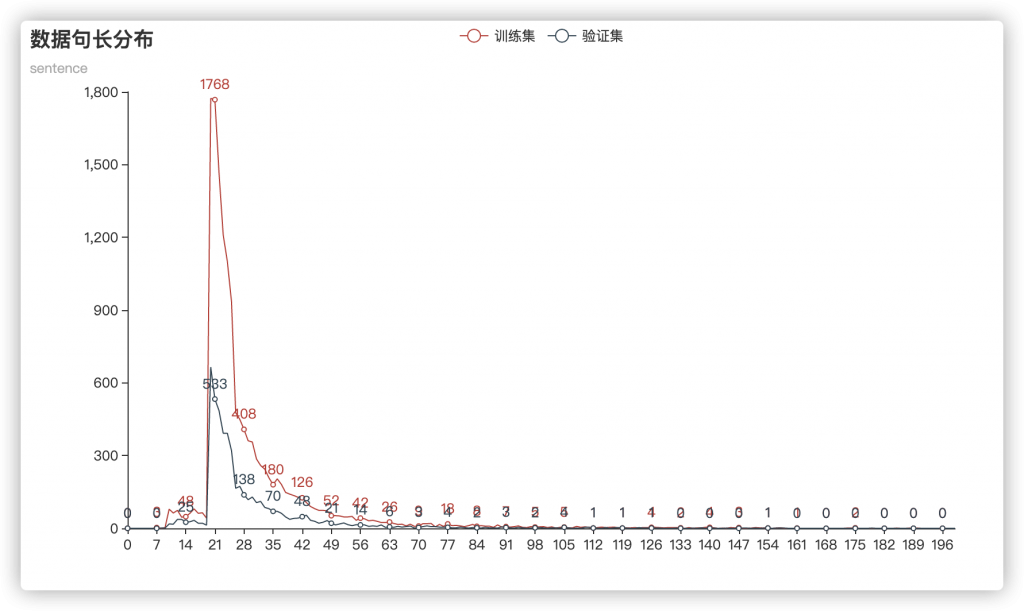
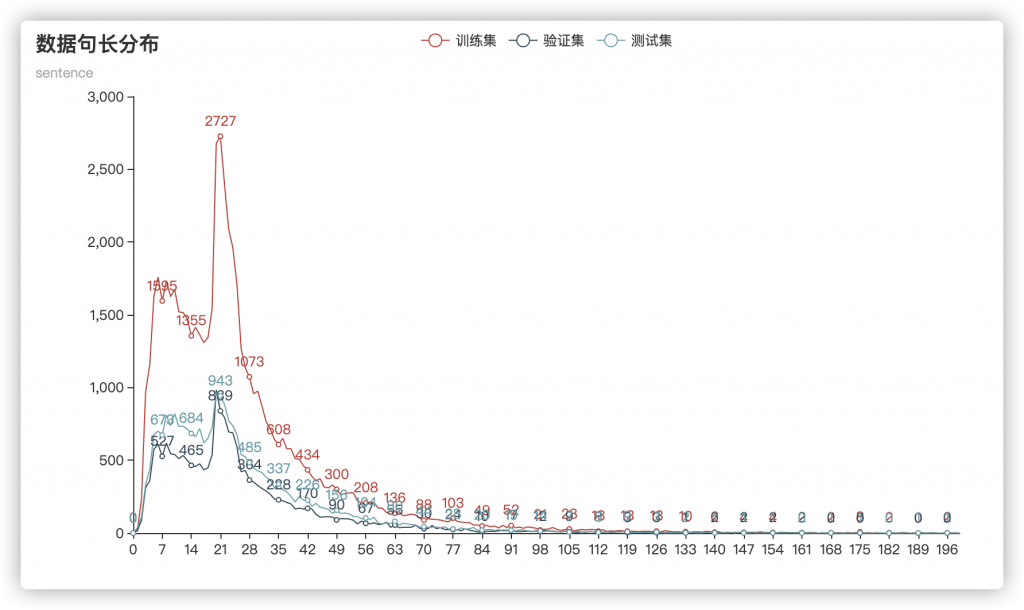
可以看出,数据长度基本是同分布的,并且长度在20~50之间有明显的聚集。
而对于句长分布:
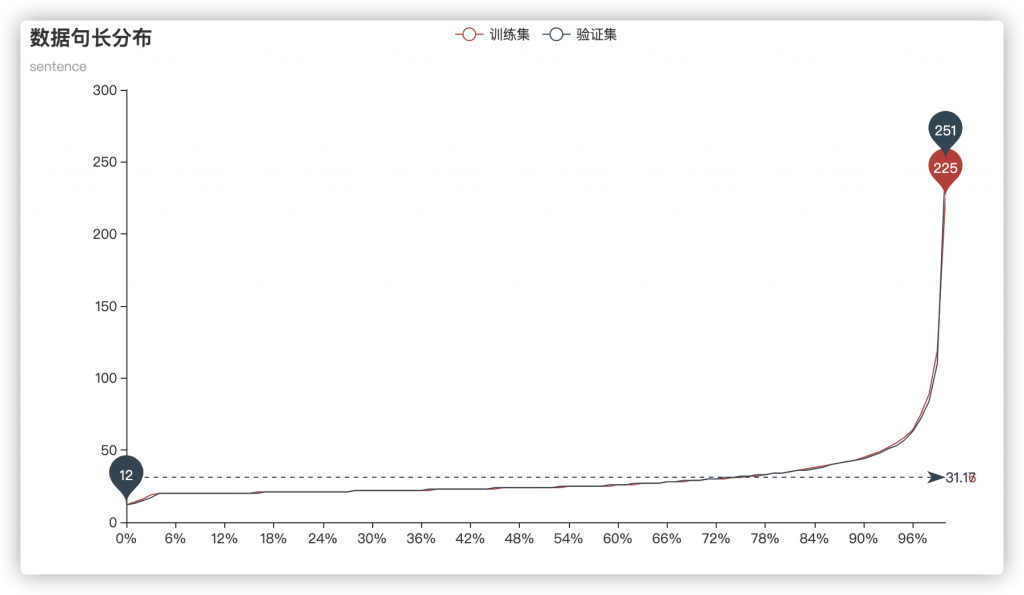
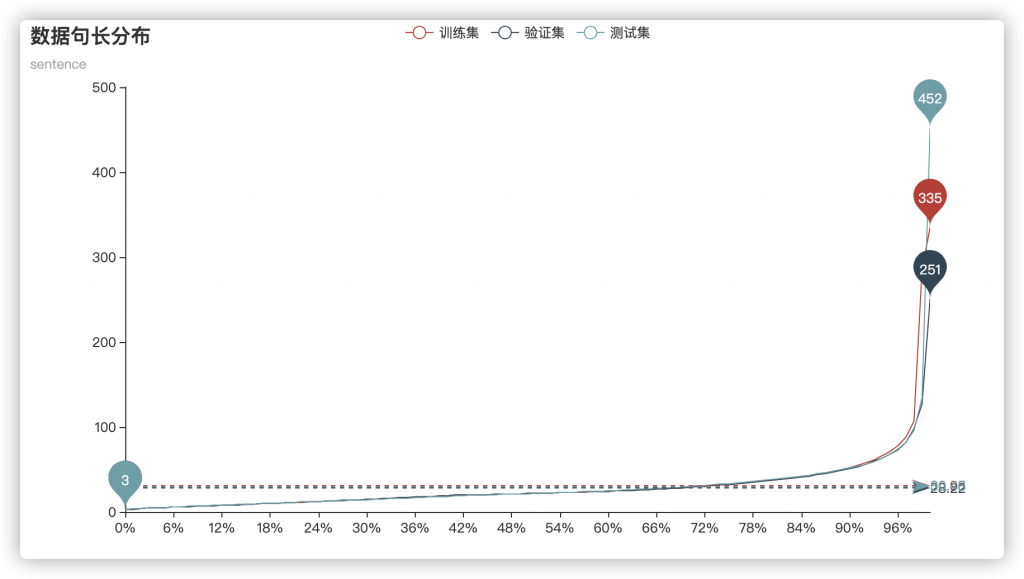
基本可以确定,几个集合的数据分布没有太大差距,并且平均句子长度均在30左右,而句长限制在100则可以覆盖到96%以上的句子。
但考虑到数据集中仍然提供了标签句的上下文(也就是文档 doc)来作为训练数据,因此对文档进行数据可视化:
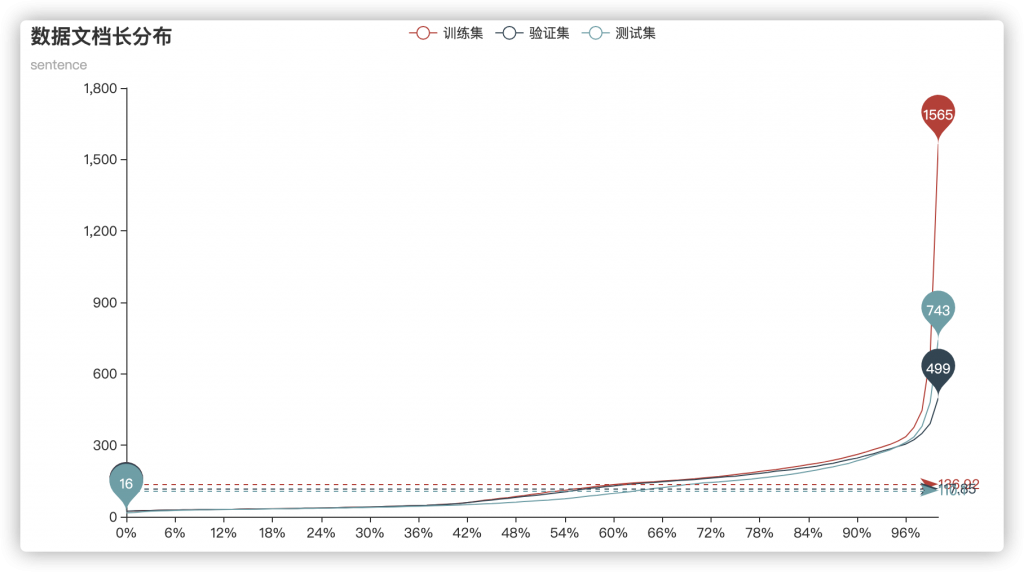
可以看到,即使是从文档角度,各个集合依然有一个较为统一的数据分布,平均长度为120左右,序列长度在400左右即可覆盖96%以上的训练数据。但即使序列长度设为512,仍然有244条数据无法完全覆盖(其中,训练集137条,验证集46条,测试集61条)。
数据处理
通过观察数据,发现大量的无意义文本,例如:
<Doc ID="3">
<Sentence ID="1" label="1">回复@沃阁酒店任宁:说定了![心][萌]</Sentence>
<Sentence ID="2">//@沃阁酒店任宁:嗯 哈哈 我们绝对好生接待你啊 ~~~</Sentence>
<Sentence ID="3">//@陈宝存:回复@沃阁酒店任宁:最好下次住你们酒店!</Sentence>
</Doc>
其中 “回复@xxx”,“//@xxx”等文本并没有实际意义,并且其中还充斥着不少emoji的存在。
于是在数据处理阶段,我们将“回复@xxx”,“//@xxx”等无关文本进行了处理。
同时,由于不确定在隐性情绪识别中emoji(比如携带emoji可能会干扰阴阳怪气的识别)的有效性,最终结论是携带emoji会对结果有一个较好的收益(单句 acc+≈0.8%)
对于如何将上下文信息添加到模型中,我们采用了改变segment id的形式,即,使用segment id 为1来标记标签句
比如:

这样就可以将上下文信息添加到模型中。
但是同时还有另一个问题,那就是如果文档的文本过长怎么办?如果是拼接后长度超过512进行截取,截取掉了标签甚至是标签的上文就超过了512的长度怎么办?
我们通过数据统计发现这类标签个数并不少:
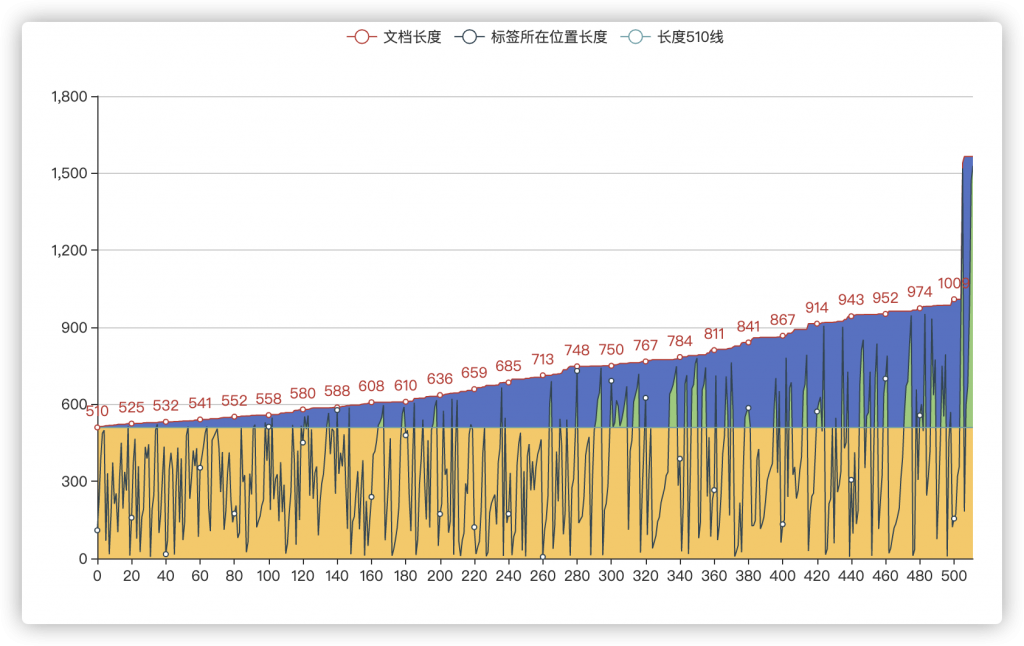
其中,最外层的蓝色部分为长度超过510的文档长度,中间的折线为这些文档中,标签句所在的位置(标签句前的文档长度有多长)以及黄色区域为小于510的区域。
我们可以发现,虽然在训练集和验证集中只有183条(137+46)文档最大长度超过了510,但是对于标签,足足有500多个,也就是这部分数据平均每个文档中有接近3个标签,而黄色区域以外依然有很多点,说明这些数据在正常的截取中会截断甚至截取不到标签数据。
而这个问题在256长度下时则更加明显
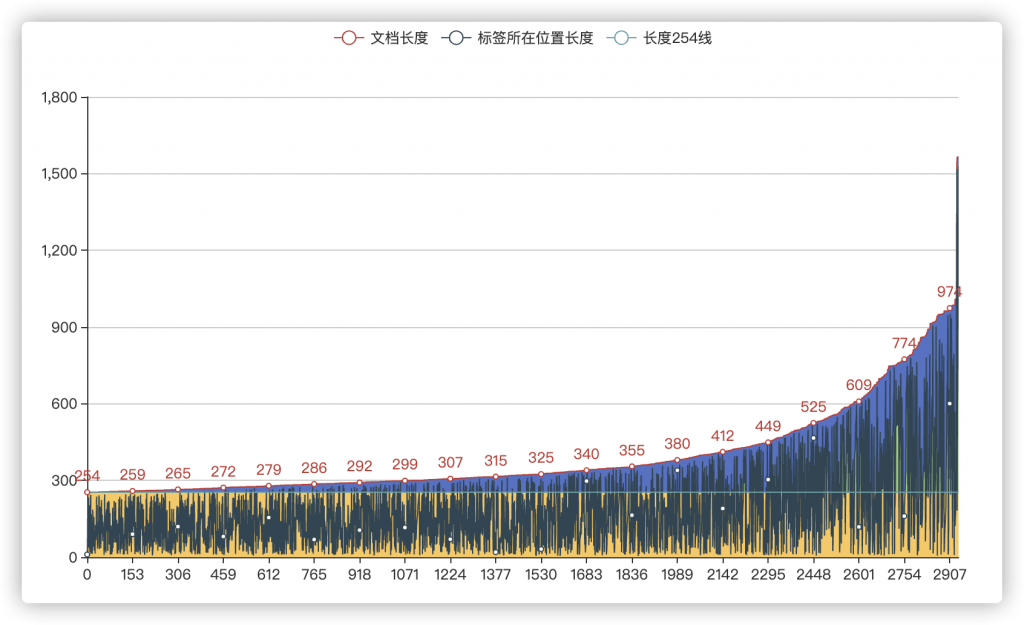
我们解决这个问题的方案就是采用前后截取策略。不同于将文档进行直接拼接,我们将整个文档分为三部分
- 标签的上文
- 标签的正文
- 标签的下文
通过计算标签的正文长度,计算出期望的标签上下文长度,分别对上下文按照期望长度进行截取,而标签的正文不做任何截取,最后将上文,正文,下文进行拼接。
比如给出一个极端例子,标签的上文长度为600,标签正文长度100,标签下文长度300.
这时如果进行简单拼接并截断,会将1000(600+100+300)的序列长度按照512进行截断,那么根本就不会有标签被送入模型,就更别提准确性了。
而如果先计算上下文的一个期望长度412(512-100),进而可以确定上下文的最长长度(分别是206),因此对上下文分别从头和尾两个方向裁剪到206长度,最终序列长度为512(206+100+206),将标签置于最中间,最大程度的保留了标签附近的上下文。(上下文acc+≈0.7%)
甚至对于长度为256的情况,由于相比长度为512序列长度缩短了一半,因此batch size可以增长一倍,简单跑了一下实验,256长度 batch size为64的结果竟然比512长度batch size为32的结果要高出0.03%。
可见使用这种segment方式,由于尽可能的让标签句在最中间,512->256的信息损失并没有多少。反而随着batch size的提升有一定的增益。
模型及方法介绍
模型介绍
我们尝试了多种预训练模型,包括bert base,bert base ext,roberta base,roberta base ext,roberta large,roberta large ext,roberta large,roberta large wwm,nezha base,nezha large,wobert,macbert,roformer,albert large等14个预训练模型上进行了验证。
最终验证bert base,bert base ext,nezha base,nezha large以及roberta large在这个任务上比较有效。
模型的改进
通过对比模型输出的分类报告以及置信矩阵,我们发现模型在标签1上的表现欠佳,分析怀疑是对于三分类来说,0类和1类的分类边界模糊。
于是我们改变思路,设计了一个新结构,我们称之为标签树(label tree),通过将三分类拆分成两个二分类,从而让模型强化01分类边界。结构如图:
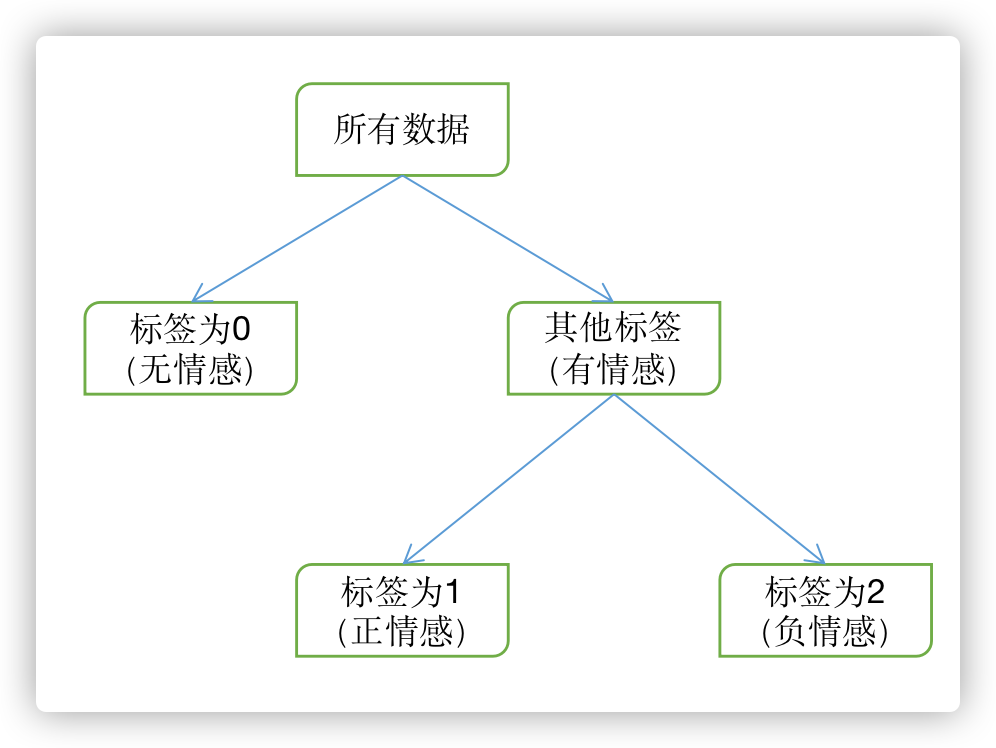
该结构虽然会有一定的错误传播(第一个分类网络的错误会传播到第二个中),但是经过计算,虽然有错误传播,但是在单分类网络均能保证90%的情况下,依然能保持较高的整体准确率。
实验表明,两个分类网络acc分别为87.8%和90%,最终线上结果79.76%。其实算是一个还不错的结果,只不过探索这个架构时已经接近了比赛的尾声,并且并没有理论计算的高表现(理论应该在82%附近),也已经有足够多优秀更优秀的模型,因此并没有持续改进该模型。
同时也尝试了continue train,继续使用mlm+文本分类的多任务的进行训练。不过并没有效果。
方法介绍
对抗训练
我们使用了FGM来做对抗训练,结果提升明显。(上下文acc+≈0.5%)
增强模型鲁棒性
使用了几种增强模型鲁棒性的策略,包括EMA,K-fold,last2avg(arxiv 2011.05864),whole word mask,random mask五种方法。
其中EMA,last2avg证明了有效,acc分别提升≈1%和≈0.3%,K(5)-fold在部分模型上有效,最高提升0.6%
whole word mask,random mask没有提升。
引入标签信息
我们通过使用prompt embedding和 将macro F1送入损失函数来将更多的信息送入到模型的计算中。
其中prompt embedding做法如下:
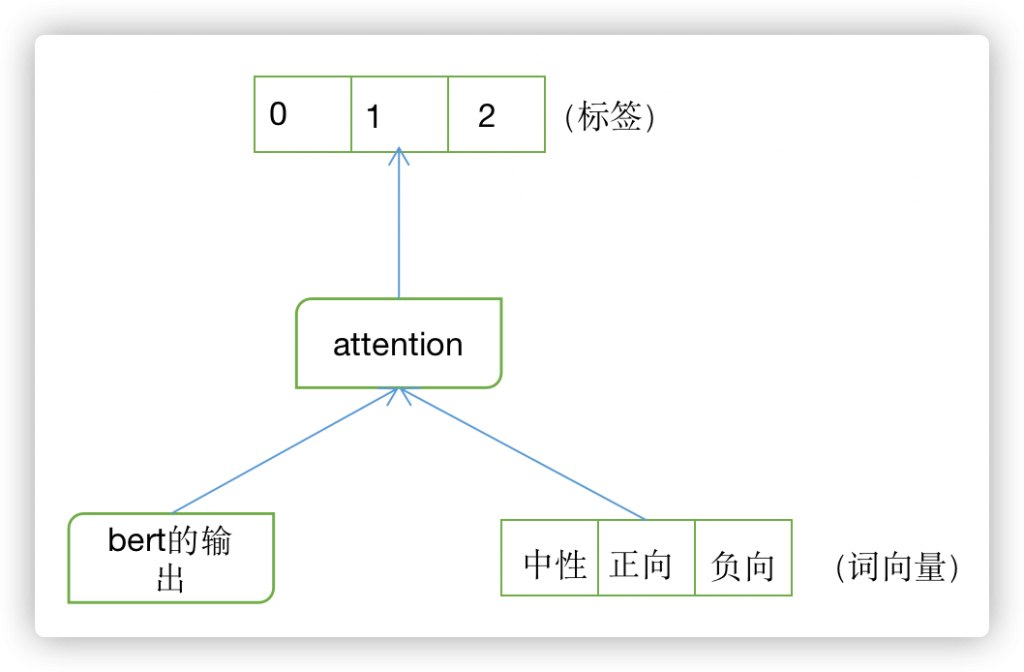
通过将bert的输出(可以是cls也可以是最后一层的池化)与分类标签的词向量(实际上可以是其他任何向量)进行attention,最终输出分类结果,使bert的输出通过与标签的attention强化各类别的边界。(部分模型有提升,最高0.2%)
F1 则是将macro F1 与交叉熵一同作为模型的损失函数(acc+≈0.2%)
数据增强
使用了R-Drop(arxiv 2106.14448),伪标签,回译等方式进行数据增强。
其中R-Drop在部分模型有提升(最高提升0.3%)。
回译(中->日->中)与伪标签均没有什么效果。
初步分析是因为构建伪标签时选择了高阈值数据,而高阈值数据对于网络来说又是相对“简单”的任务,因此对整体模型效果没有提升。
而回译通过分析数据,发现由于是隐形分析任务,往往一个词就能决定标签的结果,而回译质量有时较低,并不能识别原文语气,丢词,漏词现象频出。
比如:
<Sentence ID="1">狗的半夜不睡觉嘛,等会儿鬼就要去找你!</Sentence>
<Sentence ID="2" label="2">你又吓我嘛!!我是大学生了你还不是没睡啊!</Sentence>
回忆结果:
- 狗半夜不睡觉,鬼去找你!
2 又吓了一跳!!我上了大学你还没睡呢!
对于标签句(第二条),回译结果的第二个小句“!我上了大学你还没睡呢!“的情感就(可能)发生了改变。
总结
总结一下使用的trick
| 方法 | 效果 |
| segment | acc+≈0.7% |
| label tree | 线上79.76% |
| MLM | – |
| FGM对抗训练 | acc+≈0.5% |
| EMA参数滑动平均 | acc+≈1% |
| last2avg | acc+≈0.3% |
| k-fold | 部分有效,最高 0.6% |
| prompt embedding | 部分有效,最高 0.2% |
| macro F1 | acc+≈0.2% |
| R-Drop | 部分有效,最高 0.3% |
| 伪标签 | – |
| 回译 | – |
| whole word mask | – |
| random mask | – |
模型评估
由于每日提交次数只有一次,没办法满足日常验证需求。因此我们通过计算不同结果之间的diff绘制了一个图,用来粗略判断模型性能。
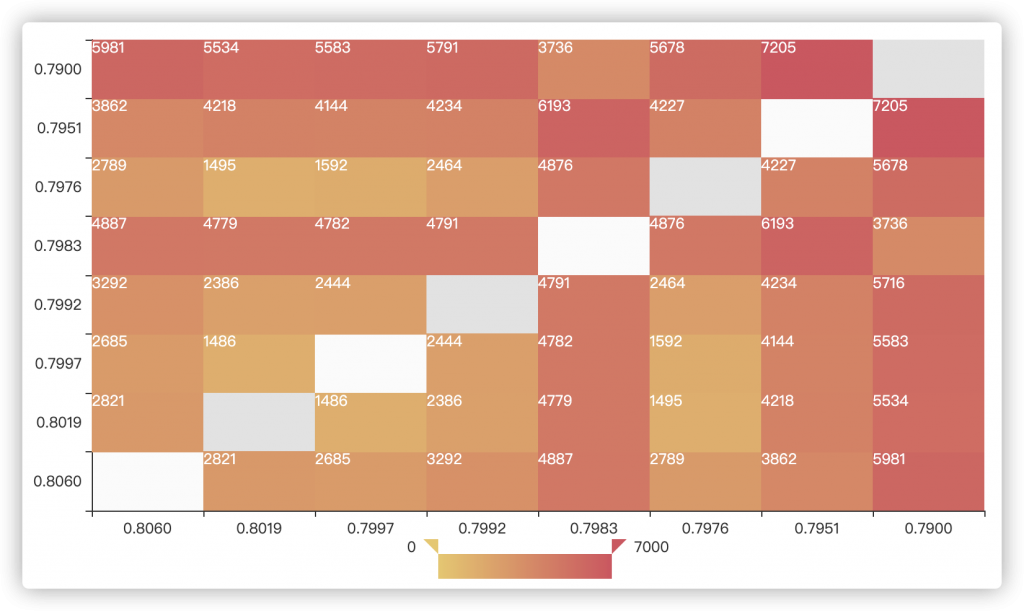
可以看出,基本呈现一个左下到右上的放射性,通过该表可以粗略判断模型性能。
同时还有一个有趣的现象,在0.7983这一列(行)并没有明显明显的放射性趋势,而其他模型均存在这种放射性。也就是说,该模型超过同等水平的diff,但却达到了其他模型类似的性能(考试你同桌比你错的多,但是你俩分数却类似)。
经过分析,该模型恰好是(唯一)一个没有融合上下文的版本,在使用机器学习或深度学习进行模型融合时也发现,该模型虽然线上指标较低(距最好的模型甚至差出1%以上)但却是所有的最优解集合中均有的模型。
推测是角度的不同导致的。使用单句而不使用上下文可以从其他的角度来进行预测,因此会造成这种情况。(考试你同桌比你错的多,但是你俩分数却类似,那就说明你俩答(对)的题不一样,而你俩的卷子综合一下就会得到很高的分数了)
模型融合
对于模型融合,我们使用了四种方式进行融合。分别是求平均,投票,机器学习融合,神经网络融合。
最终结果表明求平均的效果最好(虽然机器学习和深度学习能够找出验证集上优于求平均的指标,但是线上就不行了,推测是验证集和测试集虽然数值分布(长度等)分布相似,但是语义空间上依然有一定出入)。
思考
第一次比较正儿八经的打比赛,前前后后跑了一百多个模型,总结一下:
- 有卡非常香,可以多个模型一起跑。只有想不出来写不出来,基本不存在跑不出来。
- 将一些自己‘知道’但是没用过的知识写下来,也用了,强制自己多了很多思考。就像我在写transformer时说的那样,很多东西以为自己会了,写出来就是另外一回事了。
- 不可以轻敌啊,他们怎么都在藏分?还是太年轻了
0 条评论