目前大家对于提升bert的能力大体上可以分为几个方向。
一个是在embedding上添加扰动(比如ConSERT[ACL2021],和对抗训练,主要目的就是通过在embedding上添加随机性从而增加模型的泛化能力)。
一个方向是对bert的输出进行处理(比如bert-flow[EMNLP 2020],bert-whitening)
还有就是不断的挑战更有难度的预训练任务,比如NSP改成SOP等等。
今天介绍一个R-drop,介绍之前首先定义一下术语
- (大)模型:带有dropout的模型
- 子模型:当模型使用dropout时,未遮蔽的神经元组成的模型
众所周知,dropout会随机使一些元素为0,通过这个子模型训练,最终的结果就是让大模型中有多种解决问题的子模型,从而提升模型的泛化能力。
那如果我们将同一个样本直接送入一个带有dropout的模型两次呢?然后计算这两句话的crossentry loss呢?这是不是相当于多了一条数据呢?答案是肯定的。
而R-drop在这个基础上又增加了一个强干预项,就是不仅预测结果要一样,还要保证这两句话的KL散度较低,这就保证了同一个句子在不同的子模型下的输出尽可能一致。而这个约束也并不一定是KL,对于不同的任务可以切换到不同的约束即可。
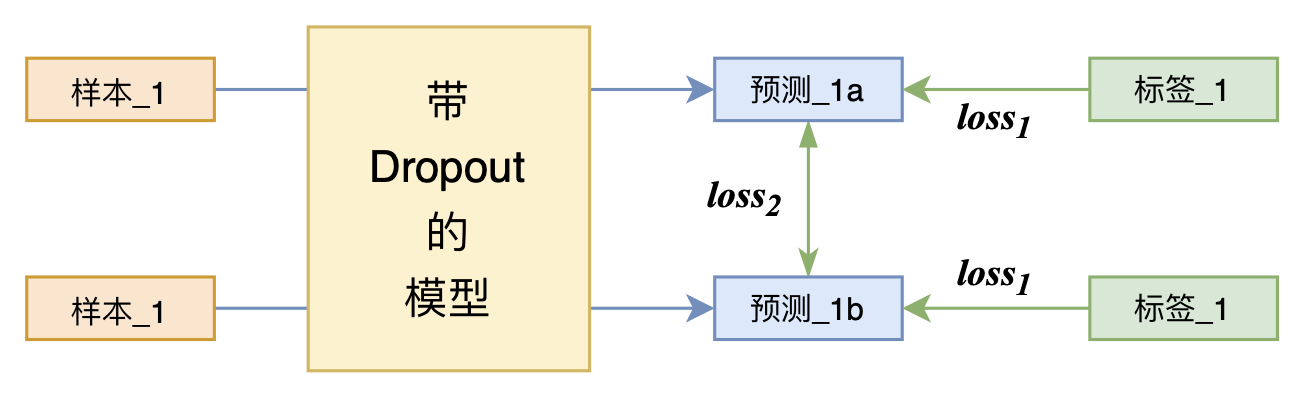
如图,最终对loss1和loss2进行加权和即可。
最后的效果提升十分明显。

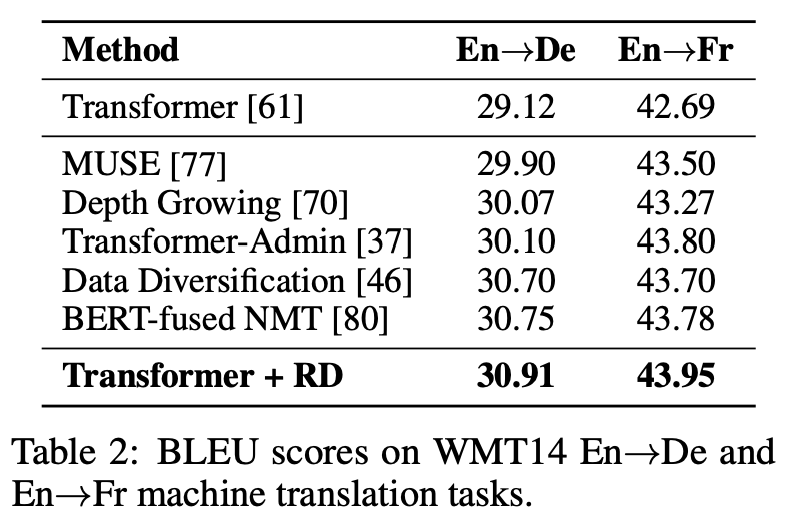
这个思路实在不得不说,是一个十分简单有效的方法,在中文分类数据集上有接近2个点的提升,而实现起来也十分简单。
只需要将数据进行复制一份,然后对loss进行改变即可(下面代码将数据连续复制,比如ABC变为AABBCC。
from keras.losses import kullback_leibler_divergence as kld
def categorical_crossentropy_with_rdrop(y_true, y_pred):
"""配合上述生成器的R-Drop Loss
其实loss_kl的除以4,是为了在数量上对齐公式描述结果。
"""
loss_ce = K.categorical_crossentropy(y_true, y_pred) # 原来的loss
loss_kl = kld(y_pred[::2], y_pred[1::2]) + kld(y_pred[1::2], y_pred[::2])
return K.mean(loss_ce) + K.mean(loss_kl) / 4 * alpha那么R-Drop为什么有效呢?
要说R-Drop为什么有效要说Dropout为什么有局限性。
其实使用Dropout时,训练阶段和预测阶段是有不同的,我们训练时,dropout启动,这时候的训练目标其实是模型融合——通过数个子模型,达到大模型结果的提高。
而预测过程,由于关闭了dropout,并没有这些“子模型”进行工作,而是直接输出结果——这相当于从模型平均变成了权重平均。
而R-Drop通过添加了一个约束项,强迫不同的子模型有相同的输出,也就是强迫“模型平均”接近“权重平均”,因此在关闭dropout之后会有性能上的提升。
而由于引入了两段loss,其中KL项并不依赖标签,因此R-Drop甚至还可以半监督训练,计算一轮CE loss,计算一轮KL loss 从而做到半监督的训练。
PS:该方法在我们ECISA中的大部分实验没有什么提升,只在相对较小一部分实验中有提升。目前还不太清楚具体原因。
0 条评论