<GPT-2>、<端到端>、<任务型对话>
论文解读仅代表个人观点,才疏学浅,如有错误欢迎指正,未经授权禁止转载。
论文原文:http://arxiv.org/abs/2005.00796
摘要
该论文是第一个在端到端任务型对话上达到SOTA的模型。本文通过使用一些就间隔符来间隔输入信息,使用文本生成模型并采用贪心策略一次性的输出belief state、act state随后生成连贯的文本。同时通过消融实验验证了端到端模型能够避免多模型集成来完成任务型对话时产生的错误传播,因此获得了更加优秀的结果。
该论文的主要贡献如下:
- SimpleTOD是DST生成模型的SOTA。
- SimpleTOD是第一个将DST、acton decision和回复生成统一到一起并获得SOTA的端到端模型。
- 在一些噪音数据中,SimpleTOD的表现依然不错。
- 证明了user/system和end token的重要性。
- 证明了预训练语言模型的重要性。
方法
训练阶段如下图所示:
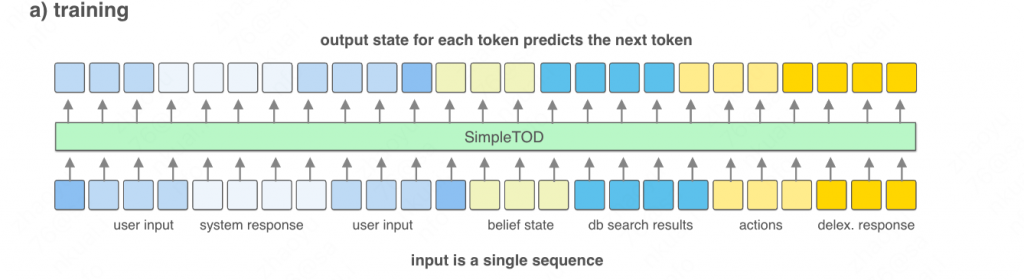
其实就是分4部分的拼接:
- 输入文本C(包含用户和系统回复的拼接,使用标识符分割)。
- belief state(dialogue state) B,为置信状态。
- DB result D,为数据库查询结果。
- act state A,系统的行为状态。

随后由模型生成回复:
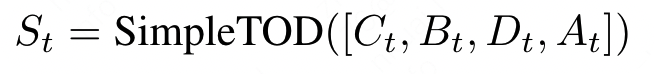
而在推理阶段,则是分阶段生成,首先输入上下文C:

生成belief state后进行数据库查询,将数据库结果继续输入到模型中:
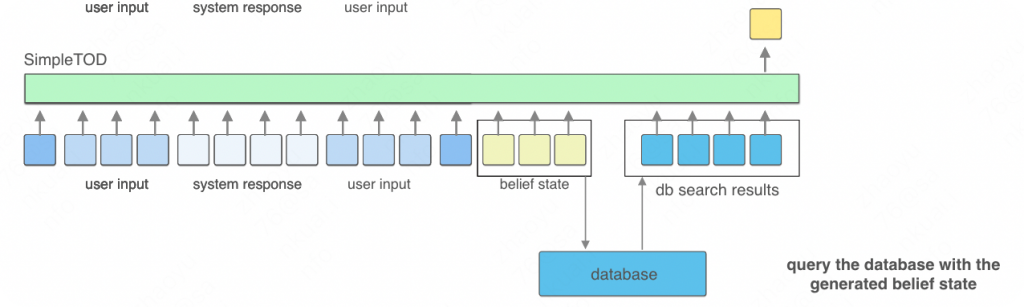
在经过多轮的迭代后,最终生成系统回复:
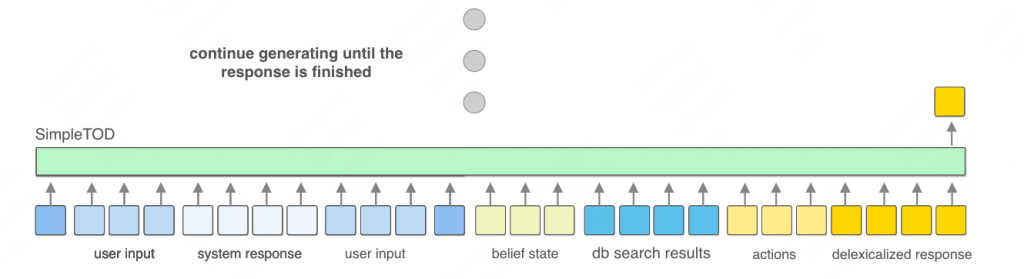
可以看到,其实就是一个比较简单的文本生成过程,只不过在生成过程中需要首先输出belief state以供数据库查询使用,使得最终的生成文本具有数据库结果支持。
实验
模型方面,本文使用了DistilGPT2(GPT-2的蒸馏版本)作为文本生成模型。
数据集方面,本文使用了任务型MultiWOZ(Multi-domain Wizard-of-Oz)以及MultiWOZ 2.1 两个数据集,其中MultiWOZ 2.1 从MultiWOZ中删除了一些错误的belief state标注。
在一些实验细节上,最终结果评估采用三个指标:
- Inform,用来度量系统提供的实体准确率。
- Success,用来度量系统是否能够回答用户所有的请求。
- BLEU,用来度量系统生成响应的流畅程度。
整体的评价指标采用BLEU+0.5*(Inform+Success)。
结果
下表为系统在MultiWOZ和MultiWOZ 2.1 上的结果。
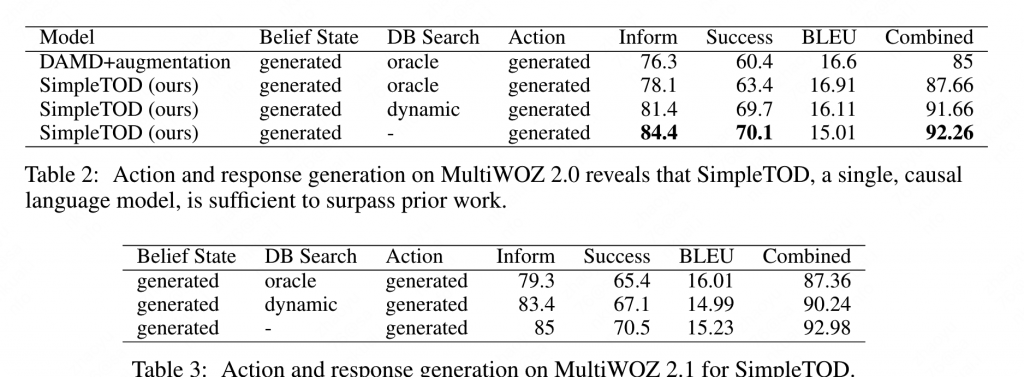
Table2可以看出,SimpleTOD整体效果不错。但是这里效果最好的是不使用DB结果,这里做出的解释是数据整体质量较低,存在错误数据(提供的数据库中实体名称没有对齐),因此错误的实体名会将整体指标拉低。
PS:但是这里的评测时,对于当前轮的结果生成,会使用上一轮的ground true作为输入,而不是上一轮的预测结果,相当于抑制了模型在多轮对话中的错误传播。这在真实场景中是不可能做到的,因此验证结果相对“不科学”。
分析
对于本文提到的特殊token标记,比如各种段落的结束符以及user/system标记符,通过消融实验验证,如果不使用这些标识符,模型更倾向于生成更加长的对话,整体效果会变差。
本文也同样验证了预训练语言模型的重要性,同样的结构是否使用预训练模型整体上会有30左右的全局(最终)指标差距。
作者还通过分析观察数据集观察到了数据集的一些错误,比如实体没有对其、意图标注错误等,这些都会造成指标降低。
作者尝试了贪心、beam search、核采样等多种方式,最终贪心策略较为优秀。
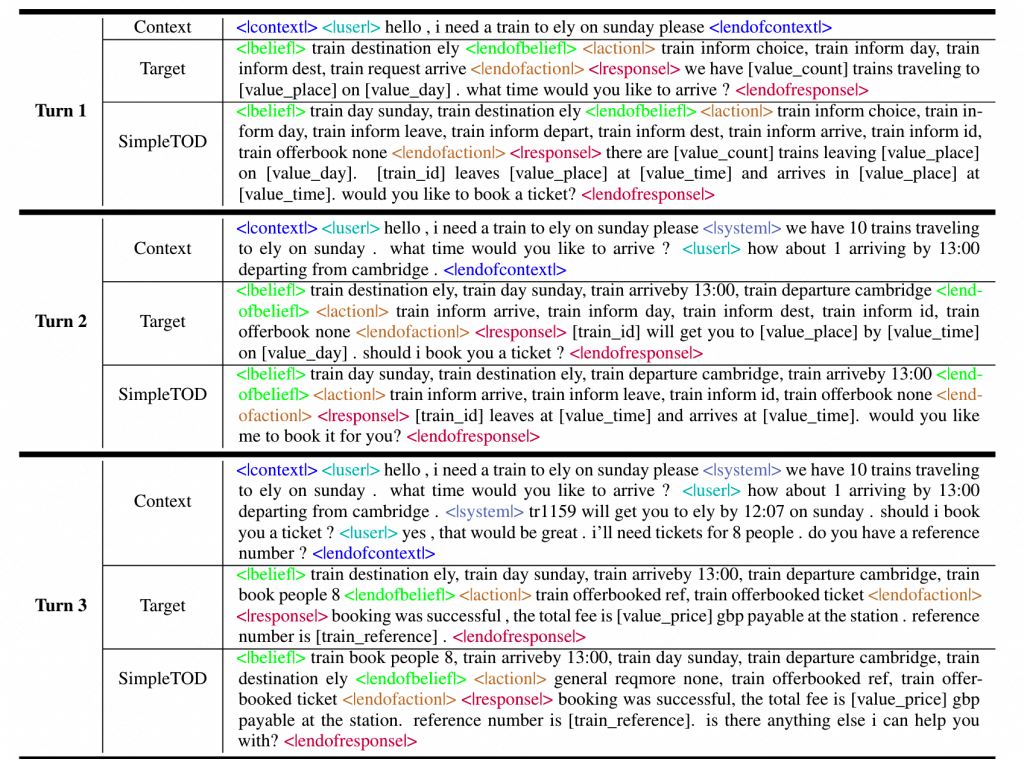
同时作者还发现该模型具备一定的belief纠正能力,在前几轮中错误的belief state识别,在后续对话如果出现了补充信息,模型有一定能力可以纠正belief state。同时模型对长对话的处理依然可圈可点。
整体的多轮生成流程如下(部分):
总结
该方法尝试了端对端的任务型会话生成策略,整体相较于分阶段模型有了一定的提升,达到了SOTA。
0 条评论