<T5>、<微调>、<任务型对话>、<端到端>
论文解读仅代表个人观点,才疏学浅,如有错误欢迎指正,未经授权禁止转载。
论文原文:http://arxiv.org/abs/2012.12458
摘要
本文是主要是一个端到端的任务型对话模型,相比传统的对话系统使用belief state、act state不同(比如MultiWOZ数据集),本文仅使用API call行为就可以获得较为优秀的生成结果,同时大规模的节省了标注成本。
本文使用T5作为语言模型,采用“当前轮输入<C>历史轮次输入”这种输入方式,由模型决定是否输出API call行为,如果输出API call行为则重新调用一次模型,将API call输出拼接到输入,从而生成连贯的基于API call的文本回复。
TicketTalk在大概2w条训练数据下,在API调用准确率以及回复合理性上均达到了媲美人类的水平。(由于没有beleif state、act state等信息,因此没有办法和其他模型横评,本文和人工评估做了对比,在10k数据下api call准确率就已经超过人类水平了)
方法
首先论文定义了标识符,具体的标识符如下:
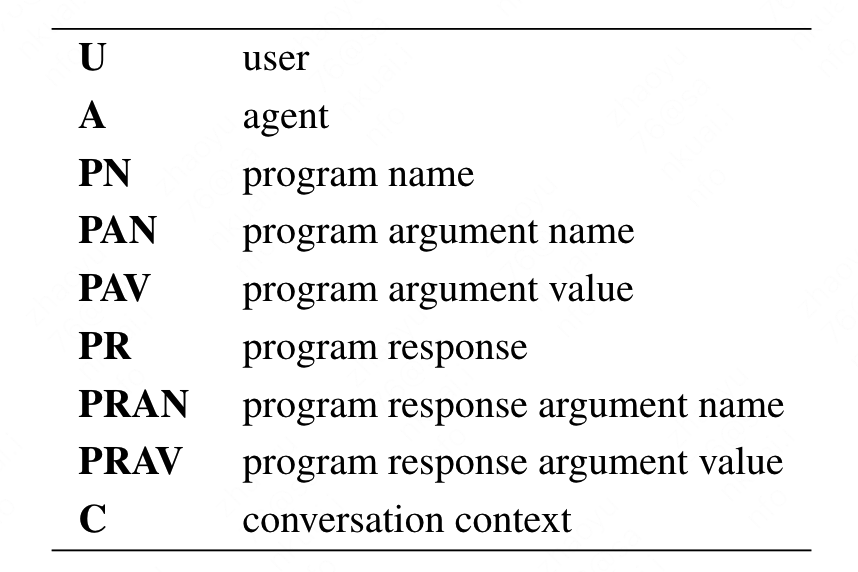
这些标识符用来区分发言角色以及API的相关信息,具体用法如下:

其中,PR、PRAN、PRAV则是根据PN、PAN、PAV调用API后的对应相应结果。
生成的整体策略如下:
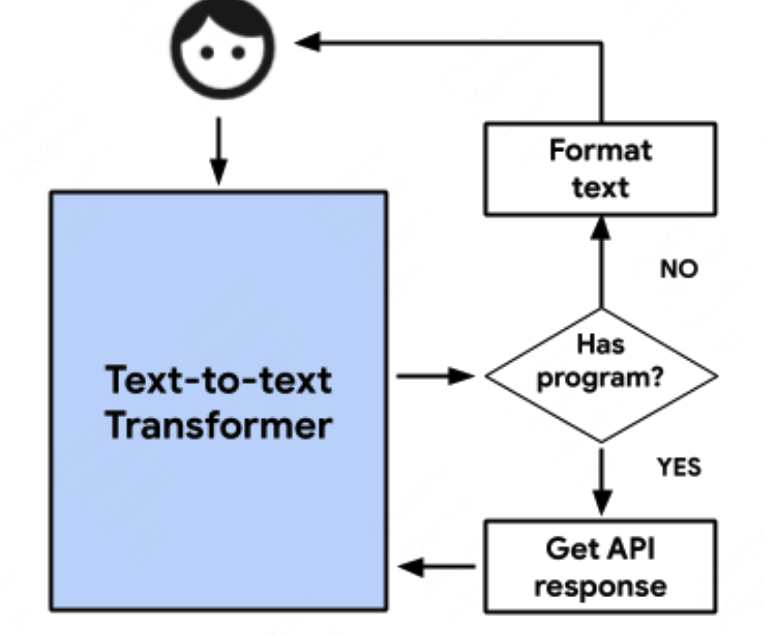
当接收到用户输入后,输入文本生成模型,判断模型输出的token是否含有API标记,如果含有API标记重新输入到文本生成模型中,如果没有则转译token后回复给用户。从而完成一轮对话。下一轮对话重复上述流程。
具体的实验细节,当前轮次的输入会放到整个输入序列的开始,同时使用间隔符与历史对话分割,猜测是为了防止超长会话阶段信息从而截断当前输入。

实验
本文使用T5作为预训练语言模型,作者首先在TaskMaster3数据集上,使用16张TPU v3 以0.001的学习率微调了4w步,batch size 为131072。最大输入长度为1024,最大输出长度为256。
评估时,使用人工评审,来评价输出的结果是否合理。
对于最终的输出,人工评审需要关注系统的输出是否合理,而对于API调用,则需要关注:
- 给出的API查询行为是否合理?
- 是否完整的覆盖了用户的意图?
最终在1000个数据上打分。
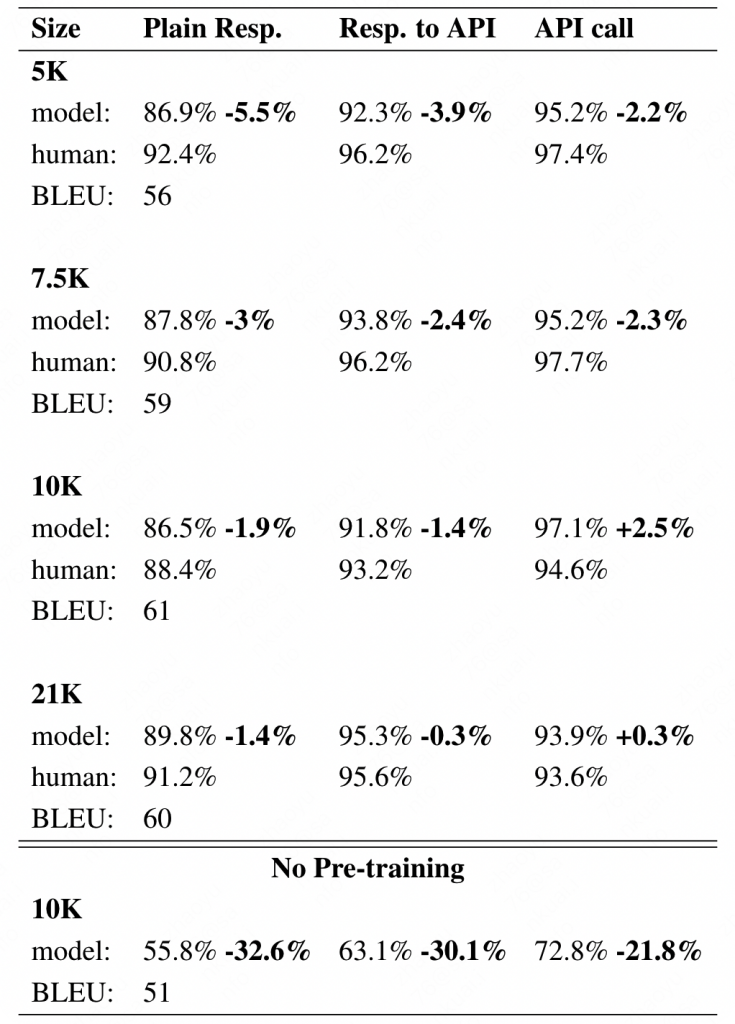
结果
通过观察下表结果,发现在10k的时候API调用准确率就已经出现了反超,整体差距也并没有很多。证明了模型效果不错。
分析
在离线分析中,TicketTalk仅使用10000个样本就能在api调用准确率上超过人类的表现。在每一轮次的回复合理性的准确率如下图所示。
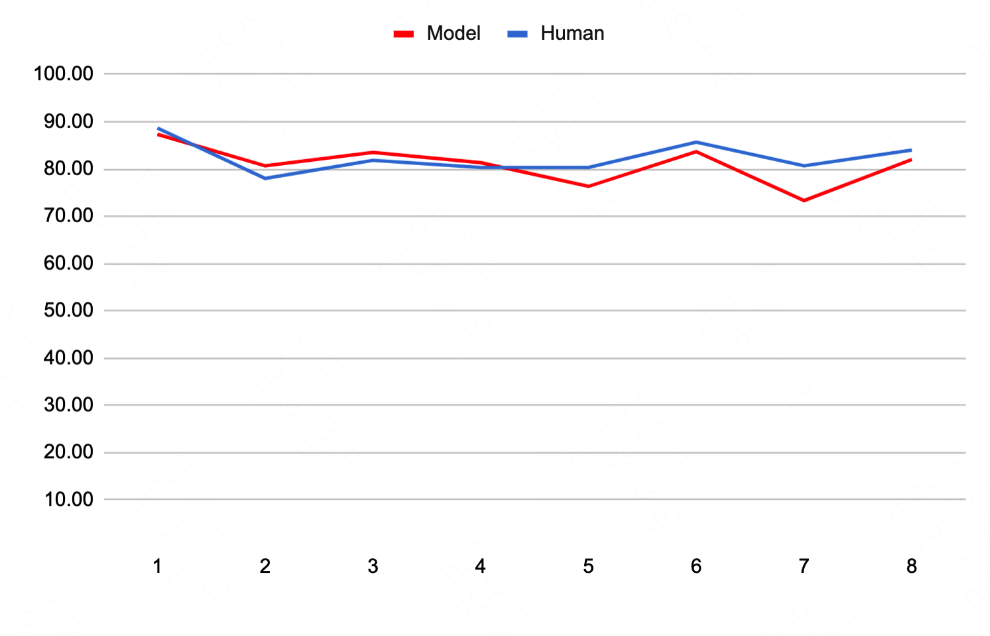
可以发现,在较低的对话轮次时,TicketTalk的回复合理性相较人工有一些优势,这些优势随着轮次上升逐渐消失。
总结
该模型使用API call作为对话生成约束,相较于之前的模型与数据集使用belief state和act state不同,API call的标注成本极低,甚至可以使用现成的线上数据作为训练样本。最终结果也表现不错。缺点就是由于使用了新的约束和数据集,无法与其他模型效果横评。
0 条评论