<GPT-2>、<端到端>、<任务型对话>
论文解读仅代表个人观点,才疏学浅,如有错误欢迎指正,未经授权禁止转载。
论文原文:http://arxiv.org/abs/2012.03539
摘要
本文提出了一个基于session级别的端到端任务型对话系统,不同于之前的turn级别的,session级别的能够捕获到全局更多的信息(因为加入了beilef state、act state等息息),生成效果更出色,达到了SOTA。
同时本文还做了大量的对比实验,包括
- 模型使用session级别要比turn级别要优秀。
- 模型在当前轮次使用之前轮的生成结果要比使用之前轮的ground true的效果要好。
- 相比语句生成和belief state生成,belief state的难度更大一些。
- UBAR的DST能力十分优秀并且做实验验证。
- UBAR的领域外迁移能力。
以及作者还分析了很多实验结果,具体见下文。
方法
整体模型比较简单粗暴,既将所有的输入序列拼接到一个文本生成模型中,十分类似于SimpleTOD的做法。

但是不同的是,SimpleTOD只输入了当前轮的belief state,和所有轮次的对话。而UBAR则是将历史轮次的belief state和act state一同作为输入输入到模型中,由于输入信息的变多,模型就可以获取到整个对话的全部信息,而不是单一的一轮次。
另外,UBAR在预测当前轮时,不同于SimpleTOD等模型使用的是历史轮次的ground true,而是使用了预测值作为输入。文中的解释是因为在实际生产环境中,不可能有ground true的历史输出,所以使用预测值作为输入更加贴近实际环境。当然,在后续的实验中还发现,使用预测值相比使用真实值还会获得性能上的增益。
与之前的做法类似,UBAR也在输入的对应位置使用了特殊的token以标识分割这些输入信息。

同时,UBAR并没有像类似于MultiWOZ那样使用三元组的belief state(domain slot_name value),而是将domain解耦出来,允许一个domain后接多个slot_name 和value,例如:[domain1] slot_name value slot_name value [domain2] slot_name value,同时还将act state继续细分为执行操作[request]和查询[inform]操作,以方便模型更好的学习。
实验
训练方式:UBAR在训练过程中,没有使用多任务学习,只使用了下一个词预测。使用的是蒸馏版的GPT-2,既DistilGP2。
数据集方面,本文使用了任务型MultiWOZ(Multi-domain Wizard-of-Oz)
最终结果评估依然采用三个指标:
- Inform,用来度量系统提供的实体准确率。
- Success,用来度量系统是否能够回答用户所有的请求。
- BLEU,用来度量系统生成响应的流畅程度。
整体的评价指标采用BLEU+0.5*(Inform+Success)。
结果
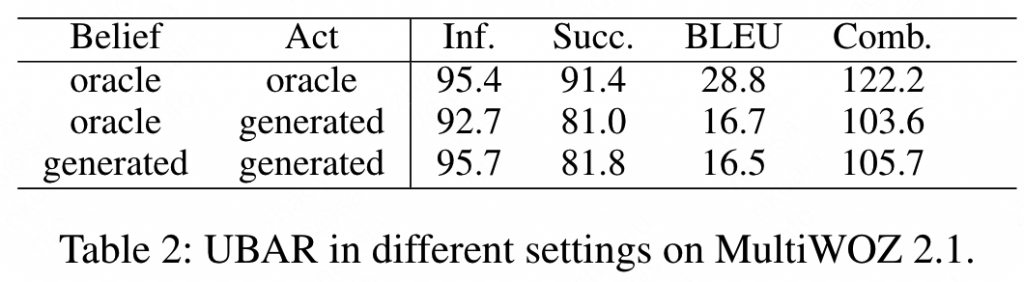
实验结果分为三部分,首先是使用真实的(oracle,ground true)的belief state和act state,结果如下表第一个区间所示。可以看出UBAR在inform和success以及最终结果的表现达到了SOTA,但是流畅程度略逊于HDSA。
第二个区间为使用真实的belief和生成的act,可以发现UBAR的效果依然要好很多。值得一提的是,SOLOIST是在大规模对话语料上进行过预训练并且在MultiWOZ上进行了微调。

第三个区间为都使用生成的这样一个策略,可以发现UBAR的结果优于所有的模型,达到了SOTA,甚至超过其他模型10个点以上。
同时,还在MultiWOZ 2.1数据集上进行了实验,结果依然和之前保持一致。
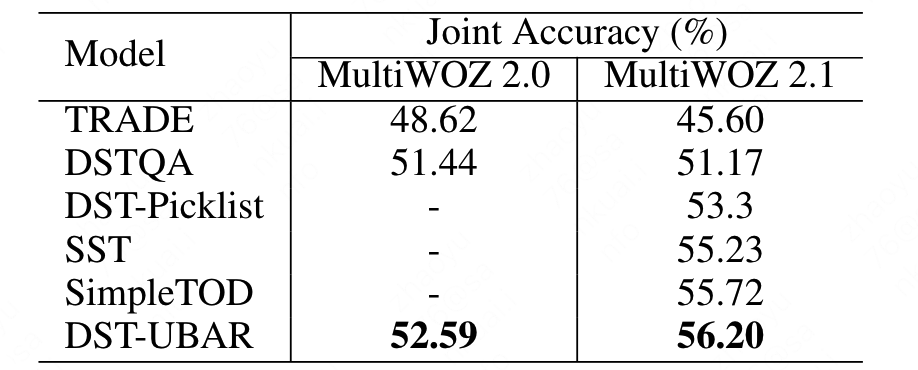
从实验结果来看,虽然UBAR是一个端到端的文本生成模型,但是似乎UBAR的DST能力十分优秀(因为belief state的分数总是很高),因此作者还尝试了一个DST版本的UBAR,结果依然吊打其他模型。
分析
由于在对话中,大量的用户信息都被保存在belief state中,因此对于当前轮对话,能否获取到之前轮的belief state就十分重要,作者尝试只使用前一轮的belief state来训练模型,实验结果表明,只使用前一轮的belief state的效果相比使用全部历史轮的belief state相比,效果有了明显的下降。
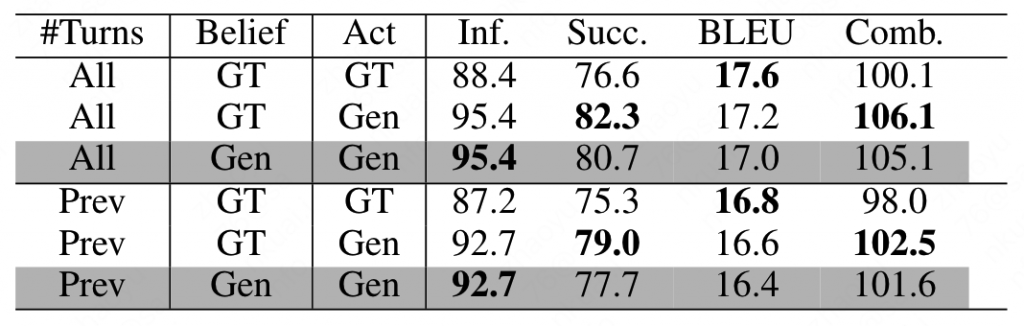
而对于turn级别还是session级别,本文也做了一些实验。如下如所示就是turn级别的UBAR,可以看出UBAR-GT相比UBAR-Gen从还要低一点,说明即使是在对话级别,在当前轮的输入中使用前一轮的输出,结果也要优于使用上一轮的GT。这一点也可以启发到SimpleTOD和SOLOIST,如果他们也是用Gen而不是GT,结果可能还会更高一点。
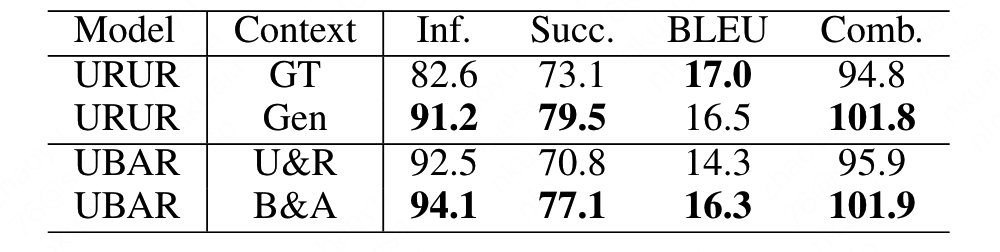
作者同样还对比了只是用user input和system response组合作为输入与belief state和act state组合作为输入,对比两组输出发现,输入belief和act的效果要更好一点,这说明,生成belief和act相比生成response对于模型来说是一个更大的挑战。
作者还对UBER的迁移能力进行了实验。作者在5个领域对UBAR进行了实验。结果如下表,其中下表第一行表示使用其他4个领域进行全量训练,然后在该领域进行实验。而第二行则和第一行类似,不同的是没有使用全量数据,只使用了100条进行训练。结果整体来说效果不错,说明UBAR的跨领域表现依然不错。

而对于zero shot的情况,作者分别尝试了zero-shot、训练100条和全量训练三种情况。作者的实验结果如下:

可以看到在只使用100条的情况下,整体指标就涨了20个点,说明模型的潜力较大,同时还可以发现100条和全量之间依然有很大的差距,说明端到端任务型对话已然是一个data hungry的一个任务。
作者还分析了模型最后一层的注意力矩阵,通过观察矩阵发现,UBAR模型很多时候并不会过多的关注历史信息,而是会预判用户接下来会说什么,这也因此产生了下面这个例子,其中左侧分支为UBAR生成的,右侧分支为强制UBAR使用GT后生成的。

可以发现UBAR在第一轮对话并没有给出很具体的信息,而是追问了一些属性,随后生成一个较为完美的结果。
而如果在第一步强行干预使用数据集的GT,UBAR会认为自己已经在之前问过这个问题获取到了这些信息,就会输出一个相对较差的输出。说明UBAR整体来说是具备一定的前瞻性的,这也从侧面印证了为什么使用Gen的效果要优于使用GT的效果。
总结
我。。我暂时不知道该说什么,只能说作者真的做了非常非常详细的对比于消融实验,模型很强大,学到了很多。
0 条评论