<T5>、<微调>、<任务型对话>
论文解读仅代表个人观点,才疏学浅,如有错误欢迎指正,未经授权禁止转载。
论文原文:http://arxiv.org/abs/2109.14739
摘要
本文提出了一个统一的即插即用任务型对话模型,主要通过使用T5+prompt learning [PS:说道prompt learning,推荐阅读:近代自然语言处理技术发展的“第四范式”——刘鹏飞] ,通过在同一个T5模型上完成多个对话任务(比如TOD、POL等),使得模型可以得到充分的训练,从而获得较为优秀的效果。
整体来看,本文创造性的尝试了多个任务一个模型,并使用prompt来进行任务区分,获得了SOTA。并且PPTOD在低数据量下的表现依然较为出色。但是有一些实验结果本人有一些质疑。
本文的主要贡献如下:
- 提出了一个异构的生成模型,可以节省生成时间(存疑)
- 在全量与低数据量下均达到了SOTA
方法
本文方法如下图所示,使用T5作为PPTOD的预训练语言模型,区分了四种任务,分别为:
- 生成beilef state
- 生成act state
- 判别用户intent
- 生成系统回复
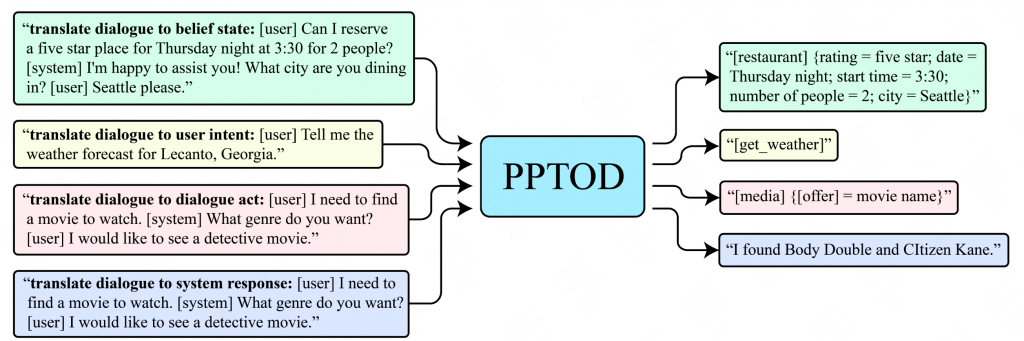
其中这四个任务都在最开始拼接上对应的prompt提示以增强效果(具体提示词见上图)。
这四个任务可以使用各自相关的数据集,并且都训练同一个预训练语言模型,因此共享的参数与共享的数据有利于模型更好的理解数据集。
同时,对于识别用户intent(意向),可以和文本生成任务并行,从而节省了系统时间开销(这里我就有第一个疑问了。。从哪儿节省的,其他的对话系统(即使是串行系统)也并没有intent这个步骤啊。。)
之所以存疑是因为常规的端到端对话系统(使用db信息),如果是使用MultiWOZ这类的belief state ->db state -> act state -> response 的那本文的生成策略也依然需要belief state -> db state -> act state -> response ,并没有减少步骤,上文说的intent可以并行但是之前的模型也没。。这个步骤哇。
如果是类似于TicketTalk这种API call的生成策略,那人家仅需要input -> api call -> response,轮次上甚至比PPTOD要少。
而对于不使用db信息,PPTOD倒是确实可以并行输出beilef state、act state和response。确实会节省一些时间。
实验
最终结果评估采用三个指标:
- Inform,用来度量系统提供的实体准确率。
- Success,用来度量系统是否能够回答用户所有的请求。
- BLEU,用来度量系统生成响应的流畅程度。
整体的评价指标采用BLEU+0.5*(Inform+Success)。
预训练语言模型使用T5,并使用了12个数据集共计2.3M个对话进行微调。(这里我就有第二个疑问了,首先2.3M的微调过于豪华,其次微调数据集中包含了随后跑SOTA验证的MultiWOZ数据集,使用跑指标的数据集进行微调算不算作弊?虽然我注意到,像SOLOIST确实使用了MultiWOZ进行了微调,但是其他模型并没有使用MultiWOZ进行微调)
结果&分析
PPTOD的结果如下图所示:
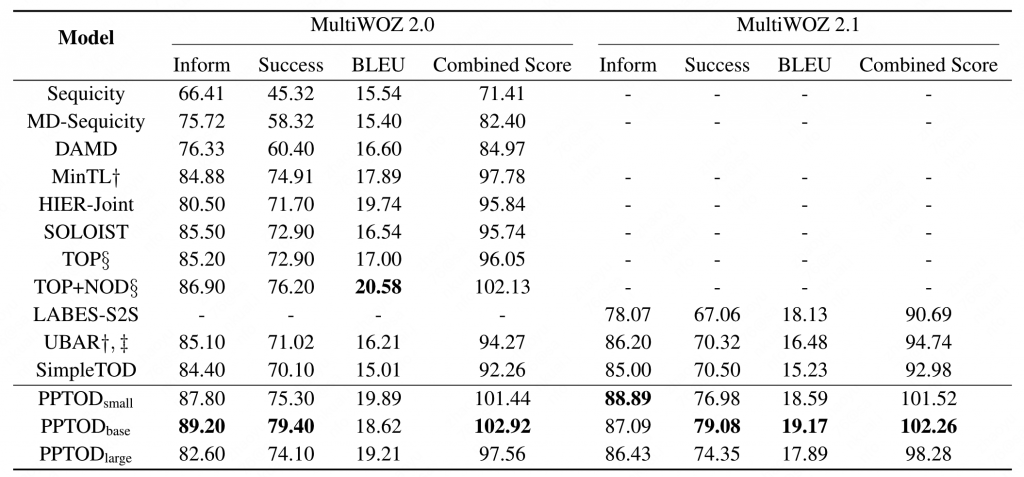
PPTOD small base large分别使用了T5-small base 和large,分别包含60M,220M和770M(前面是原文数据。google research的github的数据分别为77M、250M、800M。。是我魔怔了吗?为啥感觉哪里都有问题,还是这里去掉了哪部分。。但是论文里并没提)。
These three models are initialized with T5-small, T5-base, and T5-large models (Raffel et al., 2020) that contain ∼60M, ∼220M, and ∼770M parameters, respectively.
可以看到PPTOD-base的效果要好一些。
这里我又有第三个疑问了,上表UBAR的指标说明如下:
†: the models require the history of oracle dialogue states when making predictions at current turn. ‡: UBAR scores are acquired with the author-released models.
这里使用了UBAR作者释放的模型跑的数据,而不是UBAR论文中的数据,我倒是没有去跑UBAR,只是这个指标前后差了10个多点,如果UBAR是这个指标甚至不会达到当年SOTA。而例如SimpleTOD则和原论文指标一致。
随后作者还尝试了PPTOD在1%、5%、10%、20%几个规格训练数据上的表现,均达到了不错的效果。
随后作者还从速度上进行了一些对比,证明PPTOD不管是质量还是生成速度上(并行)相比其他模型都具有很大的优势。
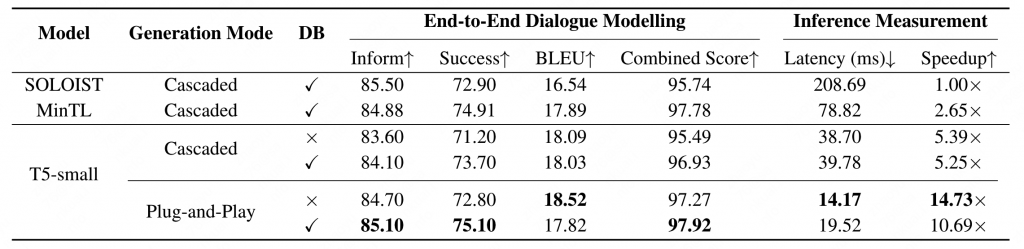
如上表所示,60M的T5-small和117M的GPT-2(SOLOIST)差了10倍的速度。
总结
总结就是思路确实不错,而且prompt也是一个十分有前景的新方向,但是里面很多说法和做法以及实验数据和我的前置知识有一些冲突,由于我也是初入茅庐的弱鸡,写出来大家一起思考,如果大佬们有什么见解麻烦在评论区指正或者邮件 zhaoyu@sniper97.cn
这篇论文我有较多疑惑,希望大佬能够批评指正
0 条评论