<数据增强>、 <基于角色的对话系统>、 <GPT-2> 、 <Transformer>
论文解读仅代表个人观点,才疏学浅,如有错误欢迎指正,未经授权禁止转载。
论文原文:http://arxiv.org/abs/2204.09867
摘要
构建基于角色的对话机器人的有两个难点,一个是并没有很多数据集,并且扩充这些数据集的代价是昂贵的。一个是此任务相比普通的对话数据会更加难以学习。
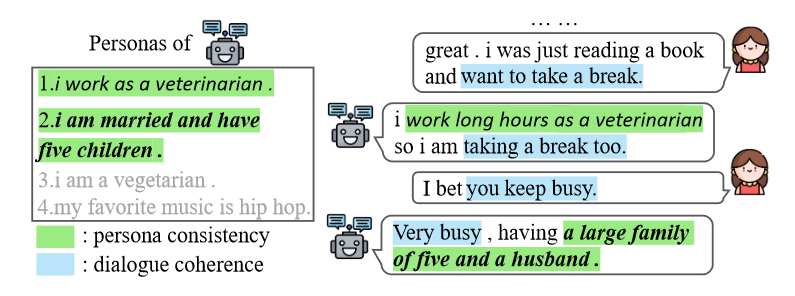
因此, 本文介绍了一个新型的数据增强方式。
本文的数据处理主要包含三个流程:
- 数据蒸馏:通过将原始数据进行去冗余操作。尽可能包含有用的信息和最低的冗余性和对话言论。为了方便后续的训练
- 数据多样性:对于容易进行蒸馏的样本,我们还可以对他们进行数据增强。本文设计了多种方法来编辑新的角色信息,然后将他们与新的对话回复结合成新的数据,从而增强数据的多样性
- 数据学习:首先使用蒸馏处理后的数据先训练基础模型,随后使用更加难的原始数据训练模型
这些方式可以通过扩充已有的数据集,在多个基础模型上获得了较为优秀的效果。
方法
首先定义数据集,对于基于角色的对话数据集,包含L个角色描述句子P={P1,P2,…,PL},对于对话历史H={H1,H2,…,HM},包含M论对话以及当前的Ground True(GT)回复R。
需要注意的是,L和M并不一定相等。
理由如Warm up一样,很多实验已经证明,在初期对于CV的研究中已经发现,模型前期学习由于batch size设置或者其他一些问题导致模型学习方向错误在后期是很难被改正的。而在NLP方面,也有很多研究表明一些脏数据回打乱attention的分布,而这些分布并不容易被修正。而对于基于对角色的对话生成这一难题,本文尝试从简如难,先从简单地数据入手,让模型先获取到大概正确的attention分布。
数据蒸馏
数据蒸馏分为角色对话蒸馏和对话历史蒸馏。
角色对话蒸馏
通过使用NLI(自然语言推理)能力,判断每一个角色的描述句子和最终的回复R是否相关,从而去除掉一些冗余的角色和对话。使用的是在DialogueNLI数据集acc达到 90.8%的ROBERTa来完成。
对话历史蒸馏
只使用最有效的最后一句话当作历史(实验证明有效) 。
数据多样性
由于蒸馏后的数据集只包括大概40%的原始数据集和4.5k个角色信息。同时由于蒸馏后的用户角色和对话高度依赖于Ground True的回复(因为是根据与R的NLI相关性获取的),因此在这个基础上进行数据多样性的扩展。
角色多样性编辑
采用token编辑和短语编辑,分别通过随机mask掉 Ground True 信息随后使用Bert预测这些token,和随机去掉结尾的一段长度使用GPT-2来恢复这些段落。
同时,为了验证GPT生成文本的流畅性以及和原文的,本文还是用了一个新的指标:
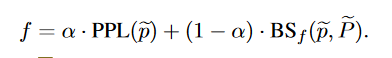
其中,PPL 通过计算GPT2的困惑度来确定句子的流畅程度,而BS全称 BERTScore,通过计算两个句子的局嵌入的cosine相似度,从而判断两个句子的语义相似性 。
回复多样性编辑
由于经过编辑角色信息后,回复信息也可能被改变,因此回复也需要被更新,使用两种方式来更新。
一种依然是token级别的,通过简单的重叠词替换(比如颜色替换等)来生成新的回复。
第二种是使用在蒸馏后的小数据集上微调过的GPT-2模型来对回复进行生成。
对话历史扩充
对于对话历史的扩充,由于对话的多样性相对较多,因此采用回译(翻译到中间语言再翻译回来)的方法进行数据扩充。
通过上述的 蒸馏->多样化生成 我们就可以获得较多的扩展数据,而对于这些扩展数据,采用以下的计算公式判别该组数据好坏
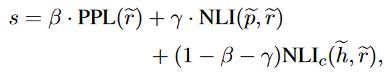
数据训练
本文并没有像之前一样增强的数据和原始数据一同训练,而是分阶段的 先让模型学习较为简单的增强数据,随后让模型学习原始数据,以获得更加优秀的attention分布。
实验
本文使用PersonaChat数据集进行试验,
对比了Transformer的encoder-decoder结构和GPT-2。对于Transformer和GPT2的微调,采用拼接角色信息和对话历史。同时使用特殊标记符来区分他们
测评分为两部分,一种是自动指标:
- PPL,通过计算GPT2的困惑度来确定句子的流畅程度
- BERTScore就是计算两个句子的局嵌入的cosine相似度。可以判断两个句子的语义相似性
- BLEU
结果
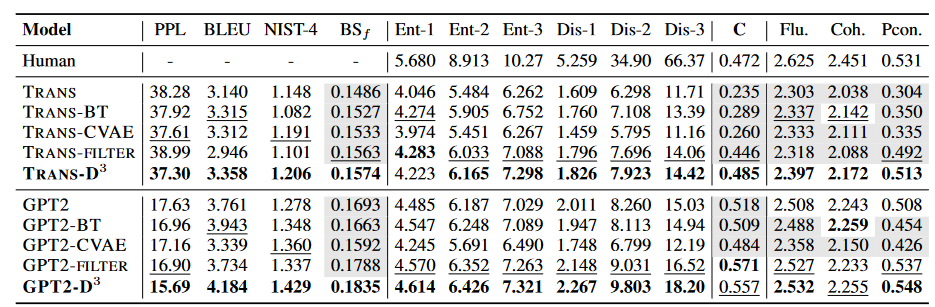
而在本文一样也做了人工评审,通过随机选取200条进行人工评比。
5个标注人员根据以下几点进行评估
- 流利性
- 合理性
- 是否包含角色信息
最终结果分别为97.5% 89.5% 100%(只有3个人以上同意才会被置为1)。
分析
提出了三个分析点:
- 数据蒸馏是否有效?
- 数据多样性扩充是否有效?
- 分阶段式的训练是否有效?
对于数据蒸馏和多样性扩充的消融实验如下,均证明了创新点的有效性。
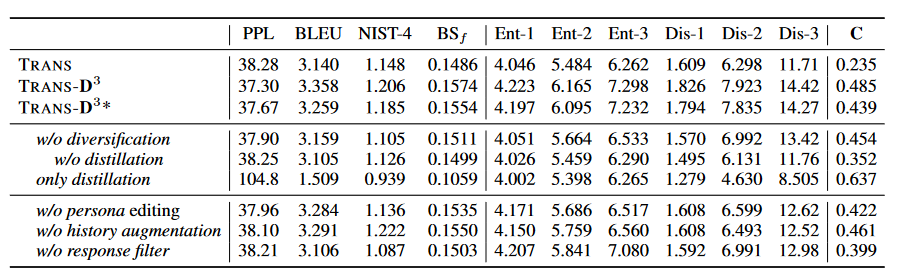
对于分阶段式的训练,本文尝试了只使用 源数据 (Original),增强的数据(Only augment),将增强数据和源数据随机打乱(shuffle)和本文的先训练增强数据随后训练源数据(Reverse)。可以看出Reverse效果最好。

总结
本文提出了一个比较新颖的数据增强方式。
对于数据增强上,整体就是尽量寻找一批任务简单的数据集(去除掉冗余的对话),赋予更多的多样性,尽量让基础模型能够完成这些简单的任务,随后完成较难的任务。
同时也要验证了在具有不同难度数据集或者可以构建不同难度数据集的情况下,先训练简单任务后训练困难任务是有性能提升的。
0 条评论