<对话系统>、 <知识注入>
论文解读仅代表个人观点,才疏学浅,如有错误欢迎指正,未经授权禁止转载。
论文原文:http://arxiv.org/abs/2203.11399
摘要
缺乏特异性的通用响应一直是现有对话模型的主要问题。这主要是因为对话系统训练数据相对匮乏以及在训练过程中并没有什么知识介入 。
本文设计了一种可以不经过任何格外的训练从而可以在现有的文本生成模型中注入外部知识的方法。

首先注入方式较为新颖,可以直接使用原生成器而不用格外训练(虽然这里我没太看懂,也没有开源代码,等后续开源代码回去学习清除)。
同时,就是知识获取方式较为新颖,本文通过一些无监督的方式可以会恢复出一下相关的知识,同时经过筛选后,选择一些相关度较高的知识最终影响原始生成模型的输出。
方法
本文的整体思路流程大概如下图所示:
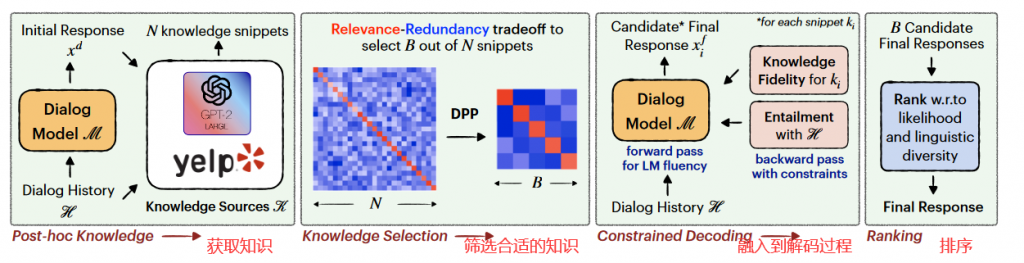
知识获取
本文主要通过两种方式获取外部知识,一种是基于参数的,另一种是基于非参数的(废话x)。
基于参数的主要是就是使用预训练语言模型来充当知识库,本文使用GPT2-large作为预训练语言模型,让模型扩充相关知识。
比如输入:
“Here is what I know about fun things around Cambridge:"模型输出:
“There are plenty of museums to visit around Cambridge. If you love hiking, you can enjoy the trails alongside the river..."从而扩展了关于关于剑桥的知识。
而对于非参数化的知识获取,则主要是通过从现有的数据集中获得知识。通过与TF-IDF计算相似度,并选取最相关的结果作为外部知识源。
筛选合适的知识
通过上一步,我们已经筛选出了不少知识了,如果将全部的这些候选知识送入文本生成则生成代价会显得很大。那么如何在这些知识挑选出相对质量更好的送入到下一步的文本生成任务中呢?
本文使用了PMI (pointwise mutual information)来作为相关性的评价指标,主要有以下两个指标:
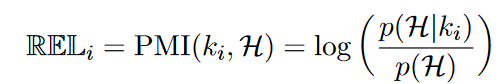
定义对话历史H和当前外部知识ki的相似度,从而获得知识的重要程度。
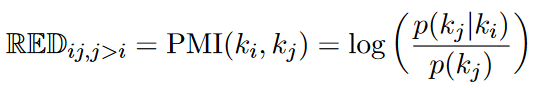
同时计算不同知识之间的两两相关性,最终构建一个相关性矩阵N。随后使用DDP算法来确定一个相对较小的子集。
DDP算法主要可以在子集选择问题的目标是从 ground set 中选择具有高质量但多样化的 items 的子集。 更多关于DDP算法的描述可以移步CSDN和知乎。
融入到解码过程
首先需要原生成模型生成一个原始答案X,然后将每个知识片段注入到回复X中形成新的回复Y。
作者定义了一个知识保真的函数定义(你这瓜保熟么),目标是将候选回复Y与当前知识片段的差距最小。
而在解码时,通过在前想和反向传播中添加扰动,同时添加约束目标函数
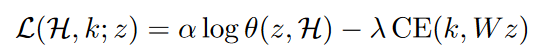
从而获取到新的输出Y。
具体这里的论文我没太看懂,论文代码目前也没有开源, 但是感觉这玩意挺牛的,留个坑回来补全。
实验
本文在MultiWOZ(Multi-domain Wizard-of-Oz)和Wow(Wizard-of-Wikipedia)两个数据集上进行实验。
对于文本生成模型,本文使用BART作为基准模型。
结果
下 表分别是在MultiWOZ和WOW上的结果:
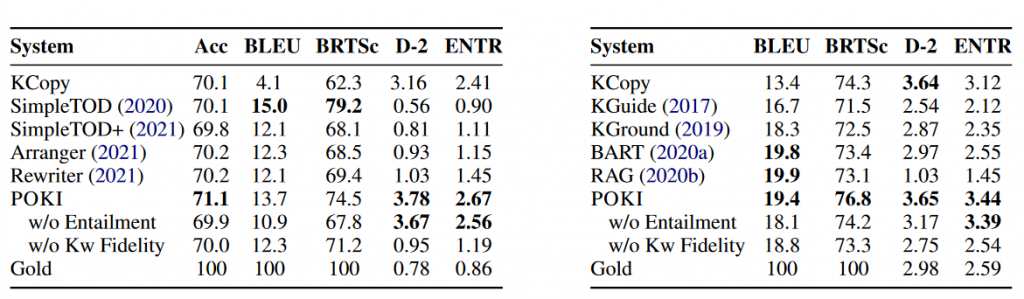
可以看到本文(POKI)的表现相对不错。
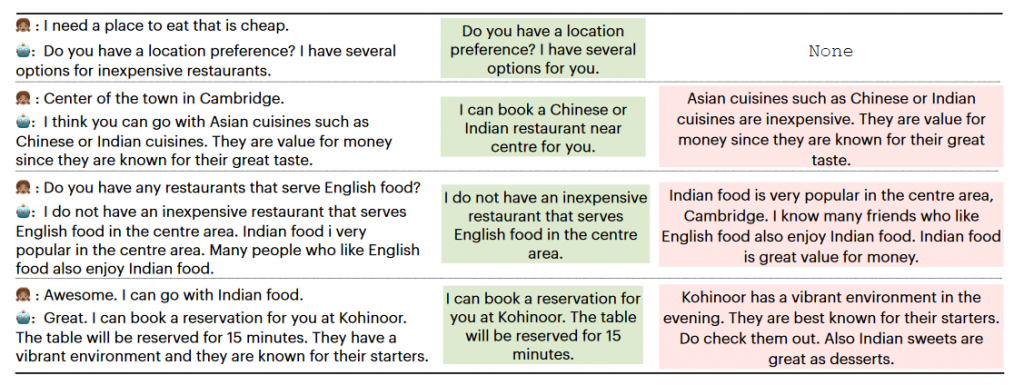
同时作者还给出了一组较为直观的输出对比图。
总结
本文提出了一个相关知识检索的方式,同时还给出了一个可以不改变任何原模型的基础上插入知识片段的方法(虽然没看懂hhh),其中知识检索相关操作可以学习,同时知识片段插入我也较为感兴趣,回头代码更新了回头学一下
0 条评论