<prompt>、<T5>
论文解读仅代表个人观点,才疏学浅,如有错误欢迎指正,未经授权禁止转载。
论文地址:http://arxiv.org/abs/2110.08207
摘要
本文通过使用多个数据集创建多个task,对于不同的task和不同的prompt/instruct来对T5进行instruction turning,最终使模型具备了较好的zero-shot能力。
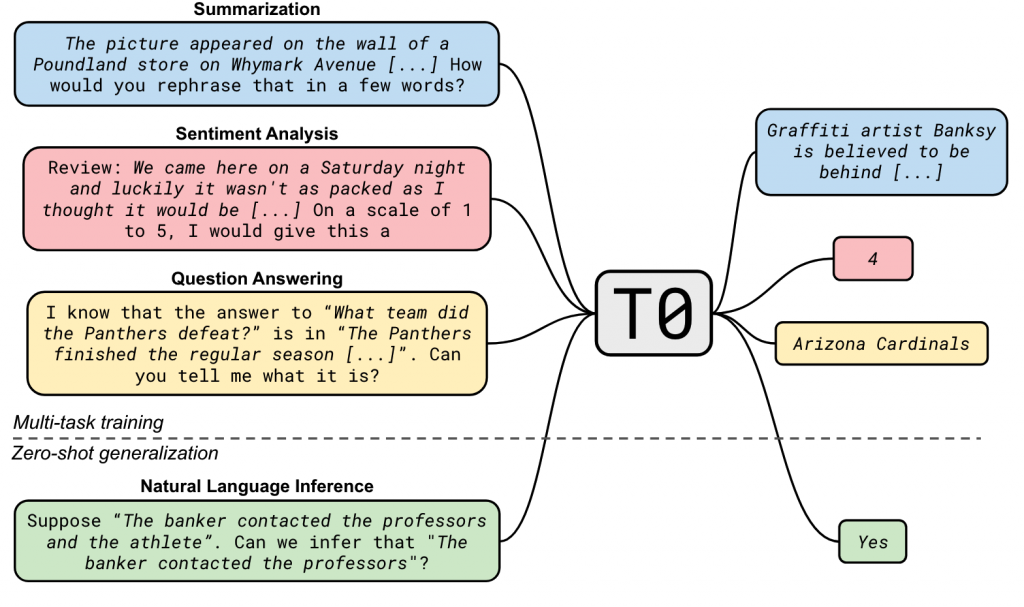
本文在prompt的数量和dataset个数两个角度验证了他们对模型产生的影响,并做了大量的对比实验。
实验结果表明,T0的效果在部分任务上超过了GPT-3的表现,增加prompt可以显著的提高模型的zero-shot能力。而增加dataset个数在一定程度之后,并不会获得特别明显的收益。
本文开源了P3数据集、3B~13B的T0、以及所有的prompt模板。
方法
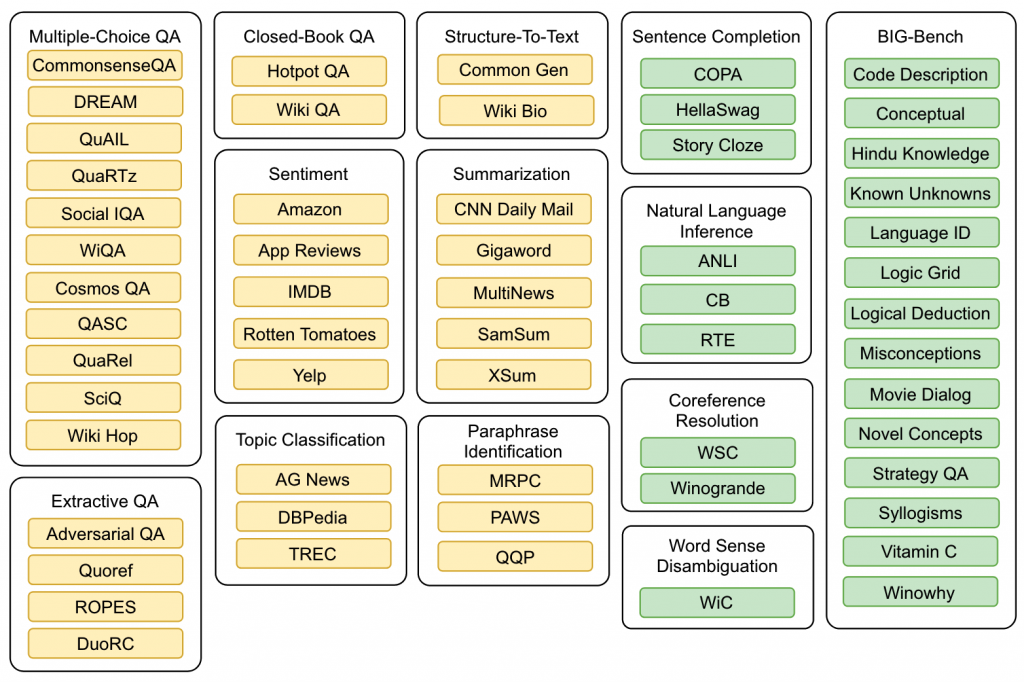
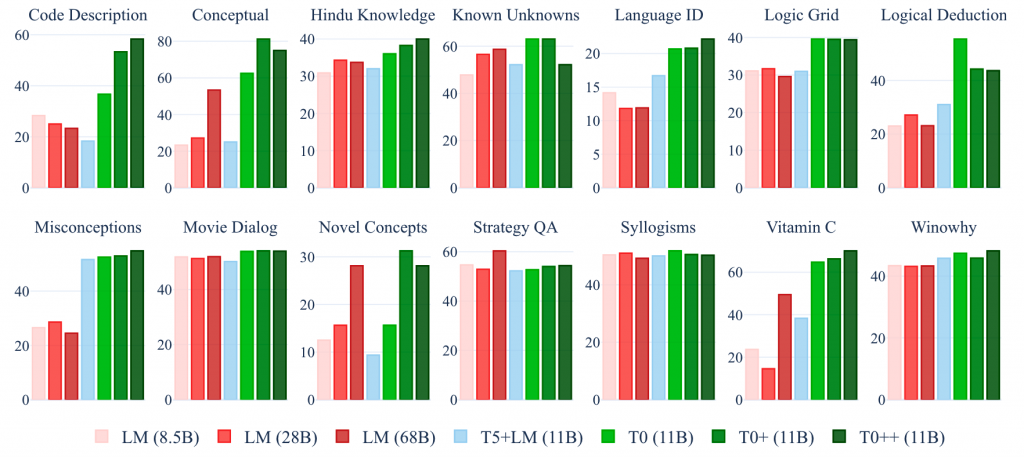
作者收集了62个数据集组成了12个任务。如下图,其中黄色部分为参与训练的数据集和任务。而绿色部分则用来做测评,从任务层面的zero-shot,并还是用了在大模型(LLM)领域使用的BIG-Bench来进行zero-shot测评。
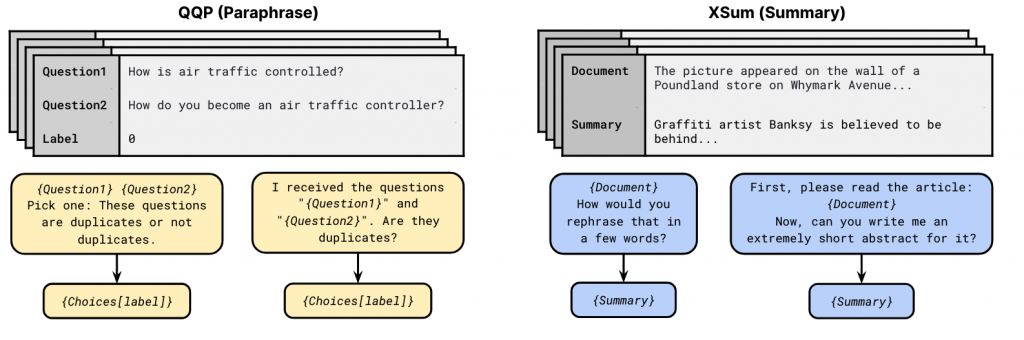
同时,对于每一条数据,通过人工的方式,设计了多个prompt模板,这些模板开源在https://github.com/bigscience-workshop/promptsource。方式如下图所示
实验
本文的baseline采用了11B的T5+LM结构,不适用prompt。同时,训练时T5的encoder和decoder限制长度分别问1024和256,使用Adafactor优化器,batch size为1024,学习率为1e-3,dropout rate 0.1来进行训练。
尝试了3B的T0、11B的T0、T0+、T0++(逐步增加用于训练的dataset)。
结论
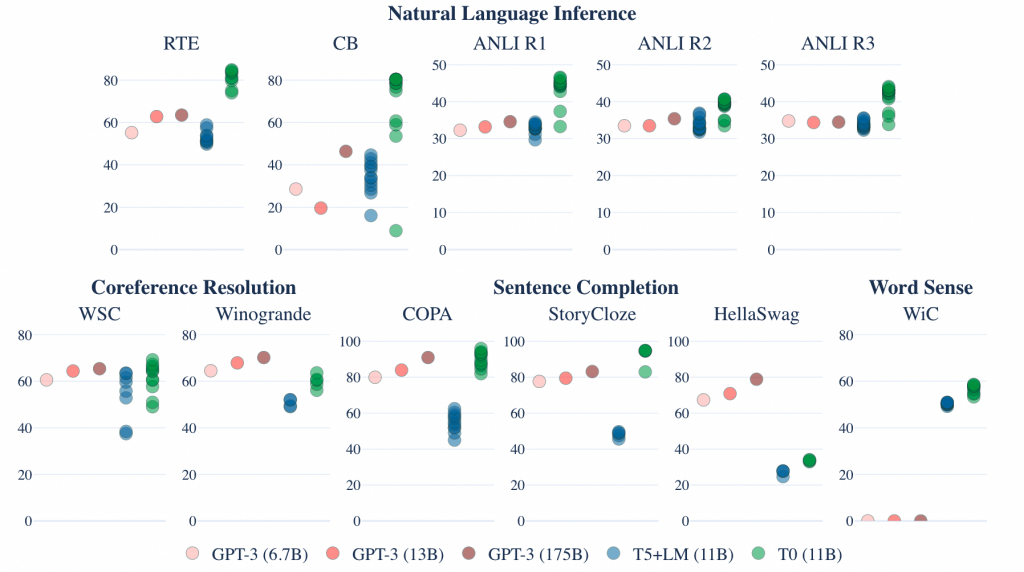
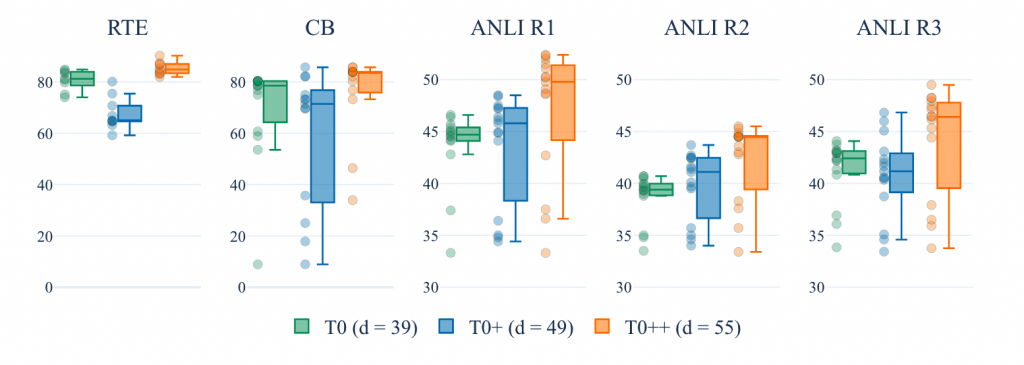
首先是不同模型的效果,下图的每一个点代表一个prompt。对于大部分数据集,11B的T0甚至由于175B的GPT-3(不过GPT-3只是用了一个prompt)。
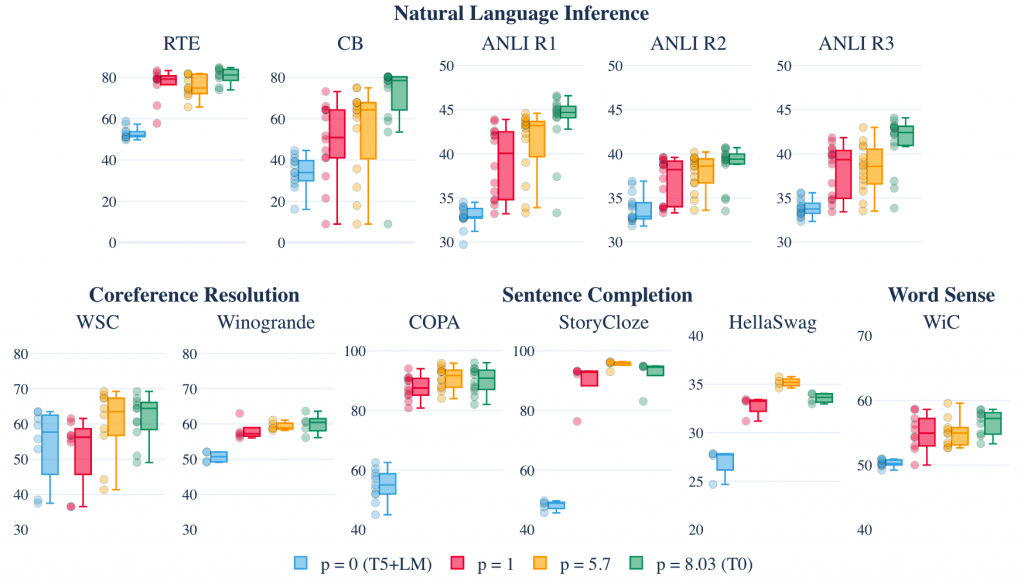
同时,本文也做了一些消融实验,预先定义了prompt数量p与dataset数量d。
下图是T0、T0+、T0++的对比,可以发现他们基本都优于LM的性能,并且随着d的增加,性能并不会有一个持续的提升。并且他们的prompt内的差距会更大(最大值和最小值的差变大)。
同时对于prompt的数量p,本文也进行了实验,我们可以发现对于大部分数据集,prompt的提升可以有效并且稳定的提升模型的性能。
作者还验证了模型在政治、人种等问题上的偏置问题,在CrowS-Pairs和WinoGender两个数据集上进行了验证,模型识别准确率分别达到了60%+和80%+。
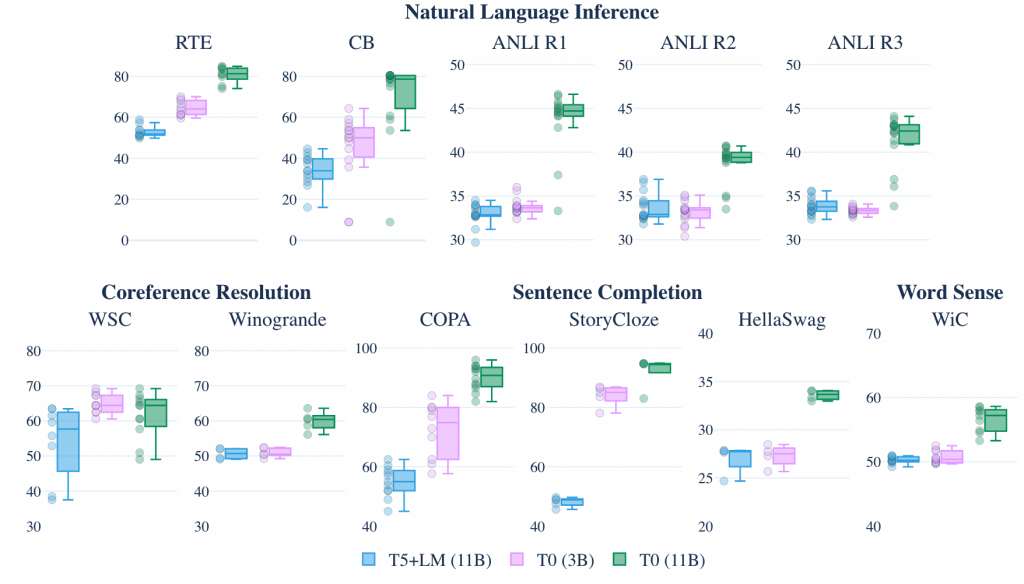
同时,作者还开源了3B的T0,性能区别如下图所示,基本均超过11B的T5+LM的性能。
0 条评论