论文解读仅代表个人观点,才疏学浅,如有错误欢迎指正,未经授权禁止转载。
论文地址:http://arxiv.org/abs/2212.10560
1.动机
由于instruction tuning严重依赖指令数据,而人工编写的指令在数量、多样性和创造力方面受到了很大的限制(人工创造的指令和label往往是常见NLP任务,多样性很差)。因此本文
- 提出了self instruct可以通过构建一批种子自动的构建instruct数据,在GPT3上达到了接近instructGPT的效果。
- 证明了self instruct的有效性
- 开放了52k的instruct以及82k的数据。
2.细节
结构如下图所示:
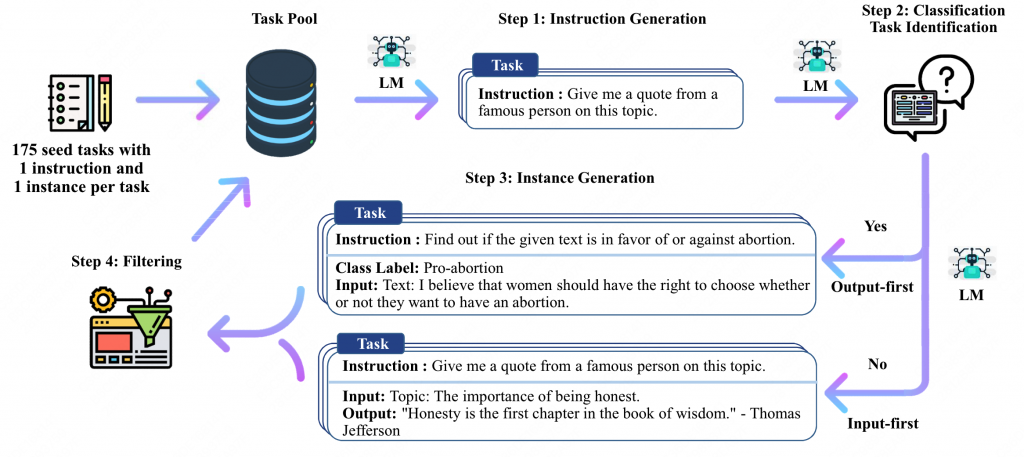
1.首先人工构造了175个任务种子加入Task Pool中。
eg:Is there anything I can eat for a breakfast that doesn’t include eggs, yet includes protein, and has roughly 700-1000 calories?
2.从Task Pool中抽取8个instruct组成的集合,输入到模型中,让它生成下一个instruct。
其中6个人工seed和2个模型生成的结构。
3.验证该instruct是否为分类任务。
之所以需要区分分类任务和生成任务,是因为模型对于分类任务,会更容易倾向于生成同一个标签的文本。因此让模型先输出label(output),在输出input。可以有效缓解这一问题。而对于其他的NLG任务,可以直接输出output。

4.筛选数据。
使用ROUGE筛选掉高重复的指令、同时筛选掉例如 图片、视频等无法被llm处理的指令。
5.将筛选后的数据放到Task Pool中,执行Step2。
3.数据分析
3.1 数据多样性
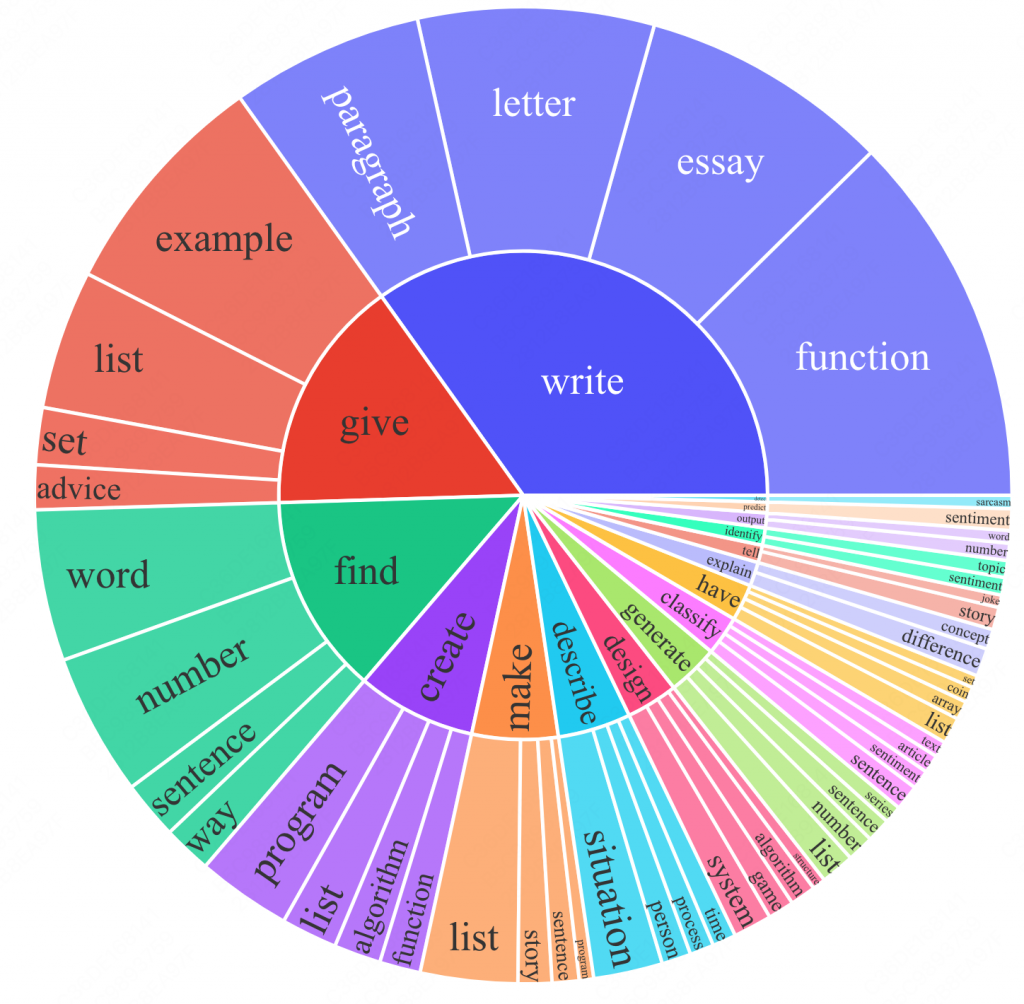
生成的指令中,常见的20个动词(内圈)以及它们后面跟的名词(外圈)。(占比14%,其余指令没办法简单建模成 动词+名词形式)。
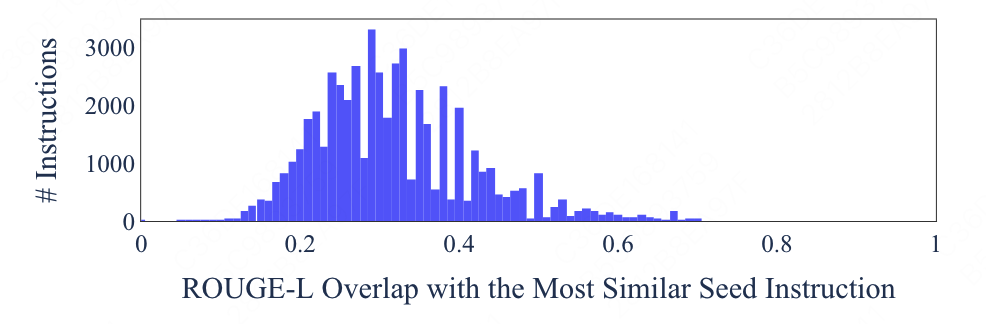
同时还对ROUGE分数进行了分析,生成的instruct与175个种子中ROUGE分数最高的占比。即如果如下图。
同时也对输入输出的长度进行了分析。
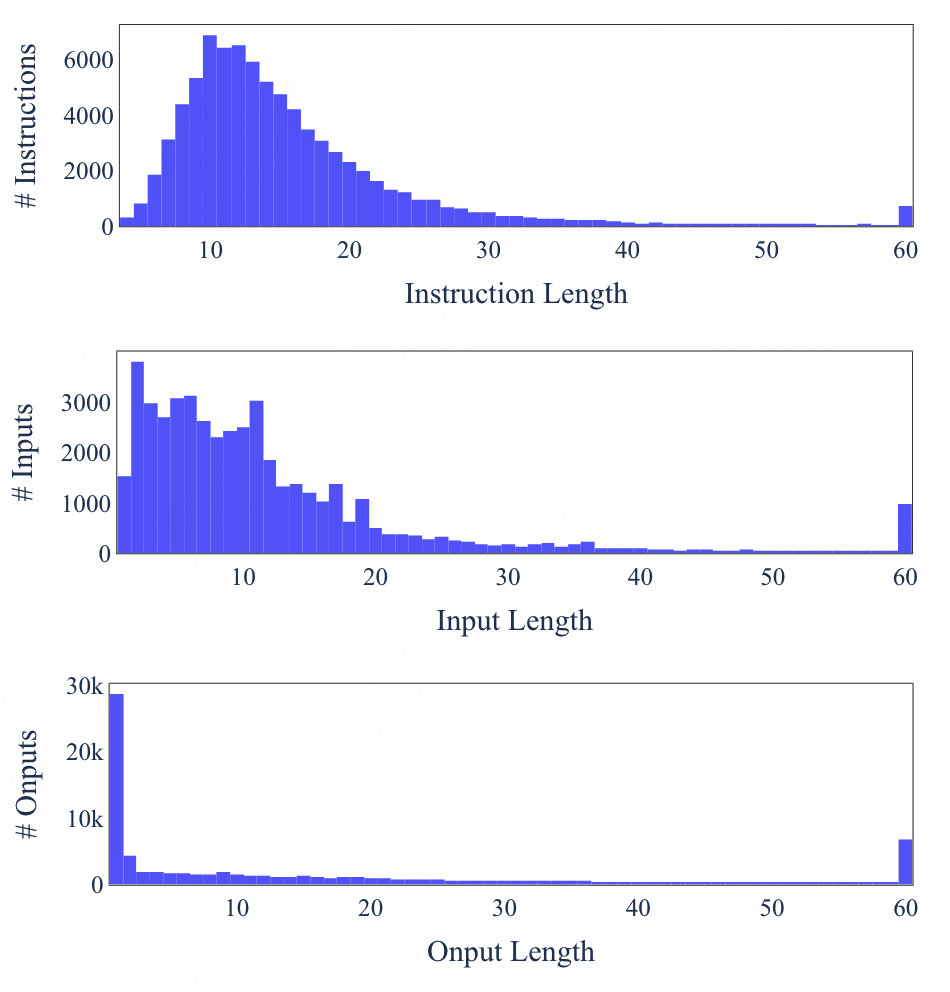
可以发现生成数据具备多样性。
3.2 数据质量
由于很多生成需要有专业能力的人才知道生成的怎么样(比如代码等),因此作者抽取了200条指令和一个随机的实例由作者进行标注。
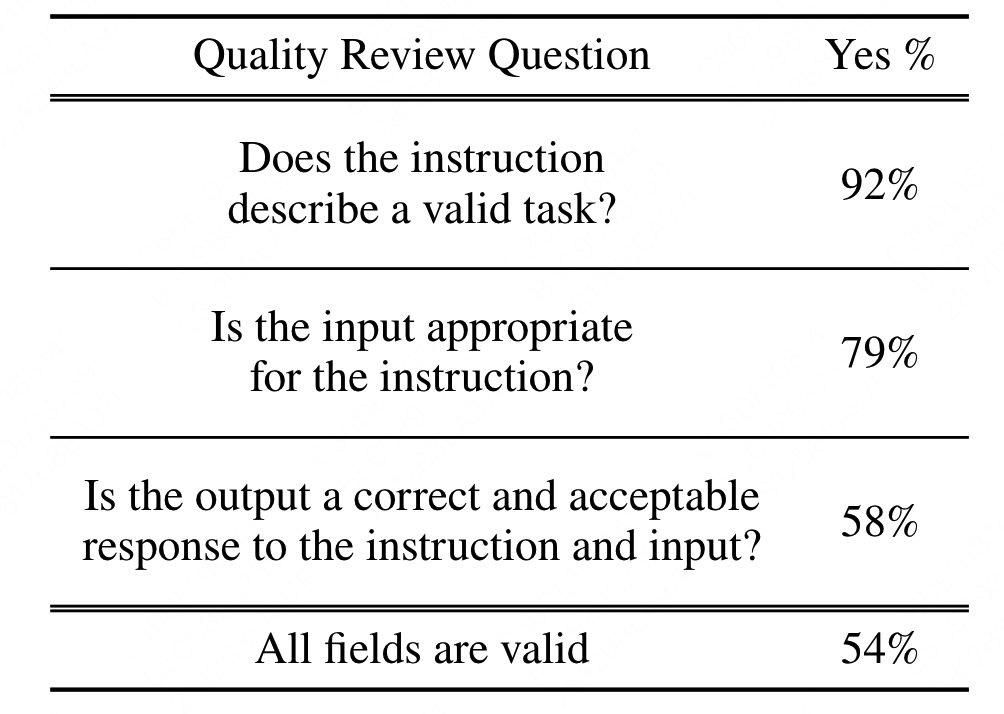
发现大部分的数据都符合要求。
4.结果分析
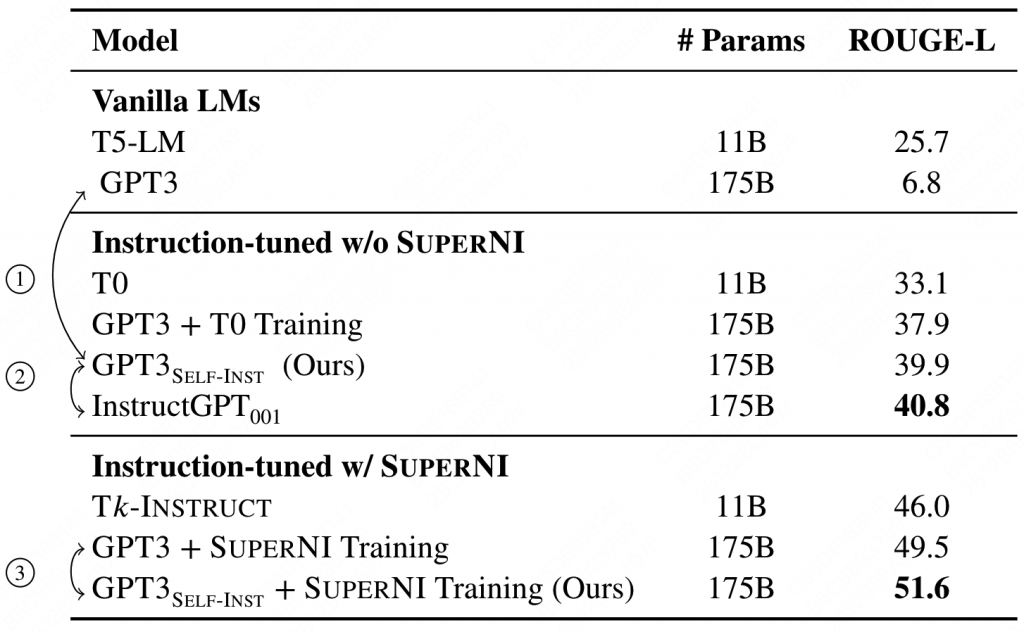
作者在T5、GPT3上 分别使用了PROMPTSOURCE[T0]、SUPERNI[Tk-INSTRUCT]进行了实验。(只取了50k个数据,但是包含了所有的instruct)
4.1 zero shot任务
在SUPERNI(一个包含119个任务,每个任务有100个sample的数据集)上进行评估:
4.2 新指令(任务)的泛化能力
由于SUPERNI更倾向于分类任务,因此人工构建了252条指令,并由人工进行打分,分为以下几个档位。
A:效果很满意,
B:response可以让人接受,但是有一点小缺陷。
C:input-output是相关的,但是内容错误。
D:完全不可用。
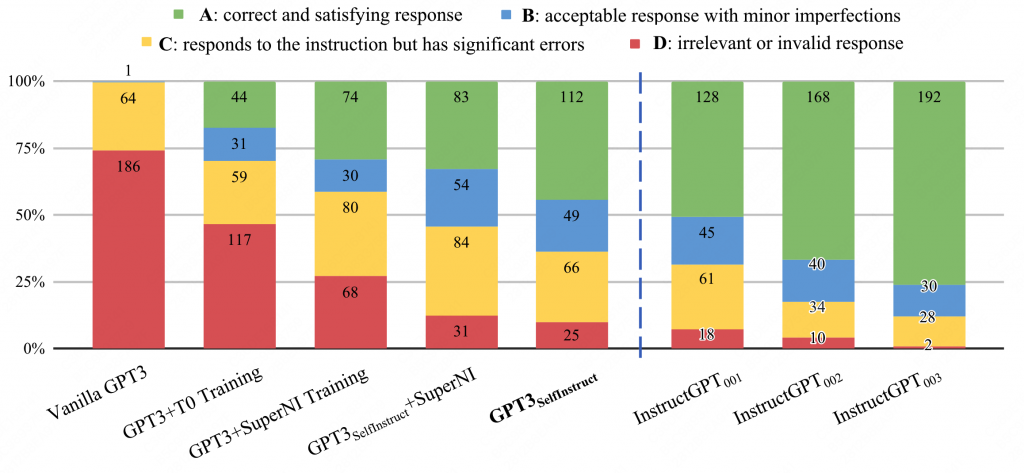
性能逼近instructGPT。
5.分析
论文中做出了两个极端的思考:
1.人工指令是不可或缺的,因为模型需要继续学习在预训练阶段没有学习到的能力。
2.人工之灵只是一个可选项。模型在预训练阶段已经具备了这个能力,只是需要某种方式的“激活”
论文中认为事实应该更偏向于2。
但是也有一些局限性。
1.语言模型本质上就只会生成头部response,低频上下文表现不好,因此self instruct更倾向于生成预训练预料中存在的任务。
2.对大预言模型的依赖。
3.跟随语言模型的偏见。
0 条评论