说明:本页所有链接均正确无误,如果发生404或者反应缓慢,是由于众所周知的原因,自行解决。
本章将用transformers的TFBertModel来实现文本分类。
首先介绍transformers(github),它是一个“State-of-the-art Natural Language Processing for PyTorch and TensorFlow 2.0 ”,也就是说它整合了目前自然语言处理方向的各种模型(不乏Bert、GPT、GET-2、XLNet以及各种网络衍生版本,详见这里),而且支持tf2(即使官方文档宣称支持TensorFlow 2.0以及上,但是由于文档更新的滞后,新版本的transformers需要TensorFlow 2.3及以上才可以正确运行,pytorch暂时没有做测试)和pytorch。
下面介绍TFBertModel。
TFBertModel
文档
这个类是最基本的Bert模型,先简单看看文档,稍后我们将进行源码分析。
TFBertModel 继承自TFPreTrainedModel,同时继承了tf.keras.Model。它支持多种输入,包括:
-
model(inputs_ids) -
model([input_ids, attention_mask]) -
model([input_ids, attention_mask, token_type_ids]) -
model({"input_ids": input_ids, "token_type_ids": token_type_ids}) - ……
可以看见对于输入的限制很松,其实它还支持很多字段
def call(
self,
inputs,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
):最终返回一个类似于字典的数据结构,包括Bert线性层的输出、最后一层隐藏层(Bert线性层的输入)以及所有的隐藏层状态(optional)、所有的注意力参数(optional)。
详细文档在这里。
简单看过文档后我们先看代码:
数据处理
首先是数据处理,transformers提供了tokenizer来进行text->token。
tokenizer提供了encoder_plus来编码(还有 encoder甚至构造方法来进行编码,但是只讲一个最全的)
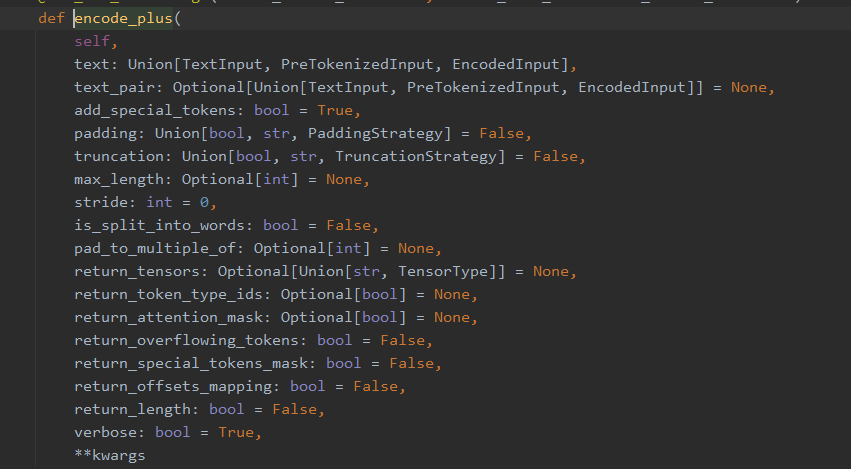
可以看到输入的参数有很多,具体参数功能详见文档。
我们使用可以直接
inputs = tokenizer.encode_plus('你好transformers', max_length=50, padding='max_length')
我们就可以发现返回了token、attention mask等参数,而这些参数可以直接输入到model.call中。
其他数据处理代码就不作讲解了,可以去查看源码,源码在后面会给出github链接。
值得一提的是,目前encode_plus好像不支持批量获取token,因此需要一次一次获取然后转换成ndarry。
如果要使用batch那么观察前面提到的model.call()的格式,并没有跟batch_size有关的参数,因此要在数据处理部分处理,将所有的三种输入(神经网络输入)分别取出。
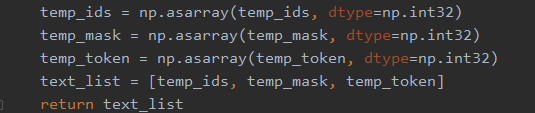
后更:找到了encode_plus_batch支持批处理,但是目前还不清楚返回数据格式需不需要处理。
模型编写
class MyTFBert(tf.keras.Model):
def __init__(self):
super(MyTFBert, self).__init__()
self.bert = TFBertModel.from_pretrained('bert-base-chinese', return_dict=True)
self.dropout = tf.keras.layers.Dropout(0.1)
self.dense = tf.keras.layers.Dense(10, activation='softmax')
self.dense2 = tf.keras.layers.Dense(768, activation='tanh')
def call(self, inputs):
idx, attn, ids = inputs
hidden = self.bert(idx, attention_mask=attn, token_type_ids=ids, training=False)
temp = hidden[1]
temp = self.dropout(temp, training=True)
out = self.dense(temp)
return out
这个就比较简单了,值得一提的就是bert的返回,上面提到,返回了三个,而我们需要的是第二个,也就是pooler_output,那么last_hidden_state是什么呢?我们观察文档:

我们可以得出,last_hidden_state 和 pooler_output 只多了一个“Linear layer and a Tanh activation function”。也就是说,将Bert的输出放入一个FC。在后面我们也会分析源码和实际操作确定这个想法。
源码
我们首先看TFBertModel的源码。
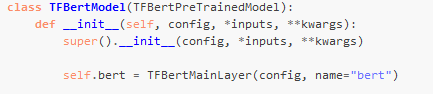

我们看到,主要有embedding、encoder、pooler几个模型。
call中:

可以看到,encoder输出后,获取last_hidden_state然后pooler(也就是Dense,继续看源码)
我们继续看encoder的源码:

我们可以看到,是多层bert的叠加。
然后pooler:
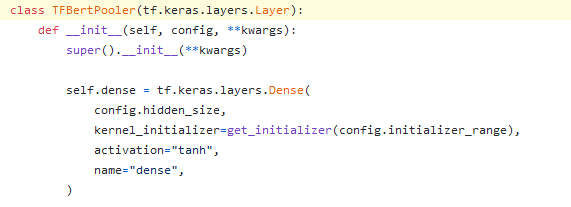
只是一个Dense层,然后我们继续看call
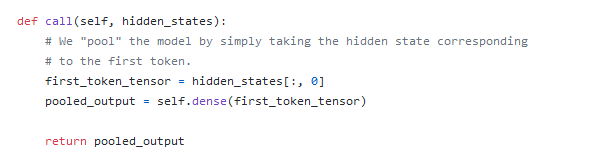
可以看到,这里使用第一个token的embedding输出然后进行dense。
到这里我们就基本缕清了transformers的TFBertModel的背后流程。
我们也可以看到,在TFBertModel种pooler返回的pooler_output作为返回的poooler_output返回,因此我们也就确定了last_hidden_state和pooler_output的关系,只是TFBertPooler的区别,就是取第一个token的embedding然后进行dense操作。
0 条评论