transformers的TFBertForTokenClassification。
对Token进行分类,比如NER任务(虽然经过测试后发现,没有CRF即使强大如Bert也不太行)。
发现tokenizer可以对列表数据进行token,并不像encode(plus)那种,会算一句话,比如图一token为起始+hello my baby+结束。

而图二为起始+hello+结束、 起始+my+结束 、 起始+baby+结束 。

源码
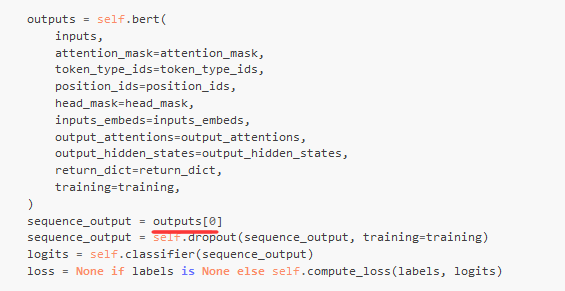
TFBertForTokenClassification 的源码依然是比较暴力的,就是在bert的token后直接接一个dense。
感觉tmrs除了TFBertModel以外的库实用性都不高。
init依然是bert、dropout、dense。

call中:
例子
使用这个类进行NER,实际测试发现,模型准确率。。和数据中O的比例基本一致,也就是基本都判断为O了,也许是没有CRF的干预模型比较嚣张?还是只有一个Dense层相对还是简单了点?
0 条评论