transformers的TFBertForNextSentencePrediction
TFBertForNextSentencePrediction
下一个句子预测。
首先查看源码
源码
init中就是bert+nsp,这也印证了之前提到过的,一定有一个bert+nsp的任务:

call:

这里没什么讲的,看一下代码:
代码
首先是token,在这里,我们更改了token的获取方式(encoder_plus一样有效,只不过是传参变了)
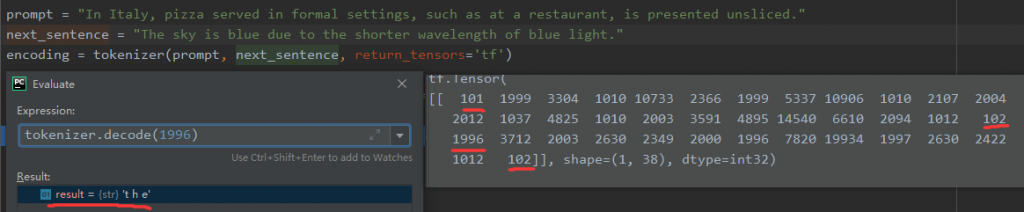
采用了<开始标记>+句子1+<结束标记>+句子2+<结束标记>的格式,这也是Bert在预训练阶段next sentence prediction任务的格式。
然后nsp会返回两个参数,这两个数分别代表不是下一句,是下一句(0,1)的概率,只不过还要进行一个softmax才是概率,一般来说,只要前一个数比后一个数小,就证明是下一句。
0 条评论