
在过去的几年,在语言处理方向的机器学习模型取得了飞快的进步,这些成果已经不再仅仅是停留在实验室阶段,而是开始为一些领先的数字产品提供动力。一个很好的栗子就是最近公布的BERT模型如何成为谷歌搜索背后的赋能者(Understanding searches better than ever before【一个不存在的网址】)谷歌认为,这一步(既在搜索过程中应用自然语言理解)代表着“最近五年最大的飞跃,也是搜索历史上最快的飞跃( the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search )”
本文是一个简单的教程,介绍如何使用多种BERT来进行句子分类。这是一个很简单的例子,但是也足够展示到一些关键概念。
在这篇文章中,我们准备了一个notebook。
数据集:SST2
在这个例子中,我们将使用SST2数据集,它包含电影评论中的句子,每个句子都标记为正向(1)和负向(0)。
模型:句子情感分类
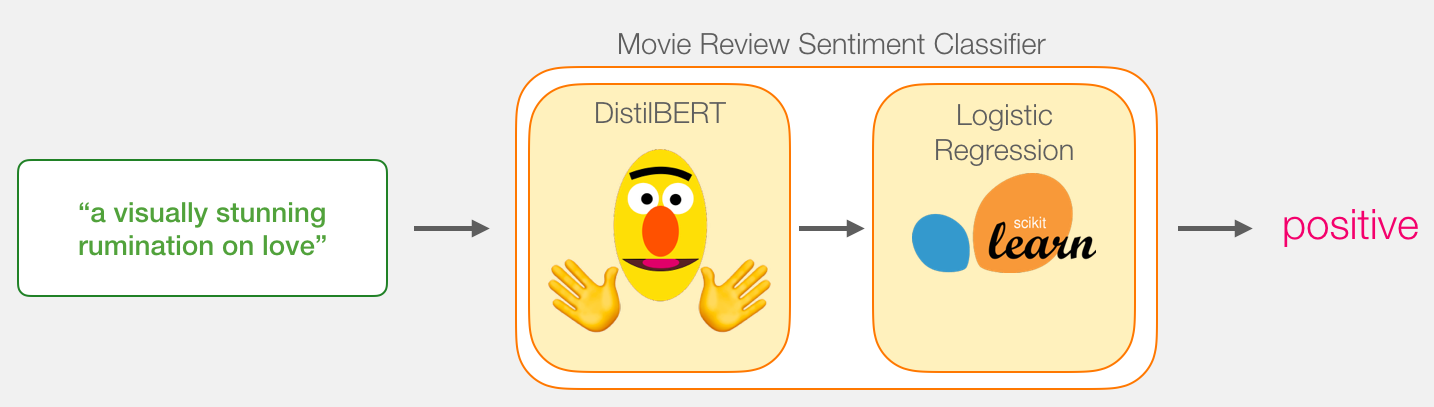
我们的目标是创建一个模型,该模型输入一个句子,然后生成1(代表这个句子具有正向的情感倾向)和0(代表这个句子具有负向的情感倾向)。我们可以把它想象成这样。

再这样的情况下,模型实际上由两个模型组成。
DistilBERT:处理句子,然后将从中提取的信息传递给下一个模型。DistillBERT是一个BERT的小版本,由HuggingFace团队开发并开源。它是BERT的一个轻量化版本,并且与性能差不太多。
下一个模型是一个基本的逻辑回归模型,它接受DistillBERT的处理结果,然后将句子分类成正向或者负向。
两个模型之间传输的数据大小是768维的向量。我们可以把这个像两个看作是我们可以用来分类的句嵌入。
如果你已经读过我的前一篇BERT,你就会知道输入向量的第一个位置是CLS。
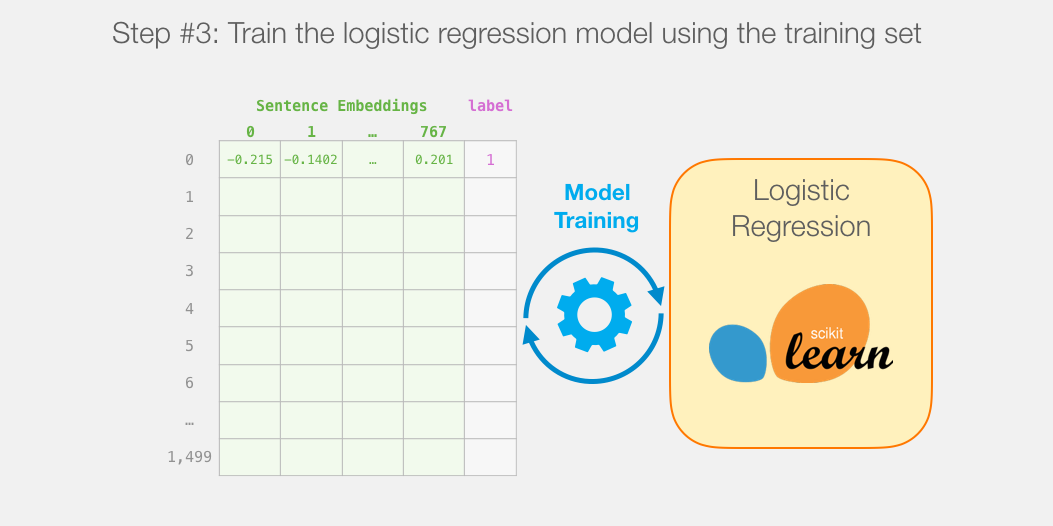
模型训练
虽然我们将使用两个模型,但是我们只会训练逻辑回归模型。对于DistillBERT,我们使用一个已经经过预训练并掌握英语语言的模型。然而,这个模型并没有对句子分类进行经过训练,也没有进行微调。然而,我们通过BERT的训练也获得了一些处理句子的能力。这显然是与BERT的第二种训练方式有关。这个过程似乎训练了模型进行语句级封装的能力。这里为我们提供了一个与训练的DistilBERT。
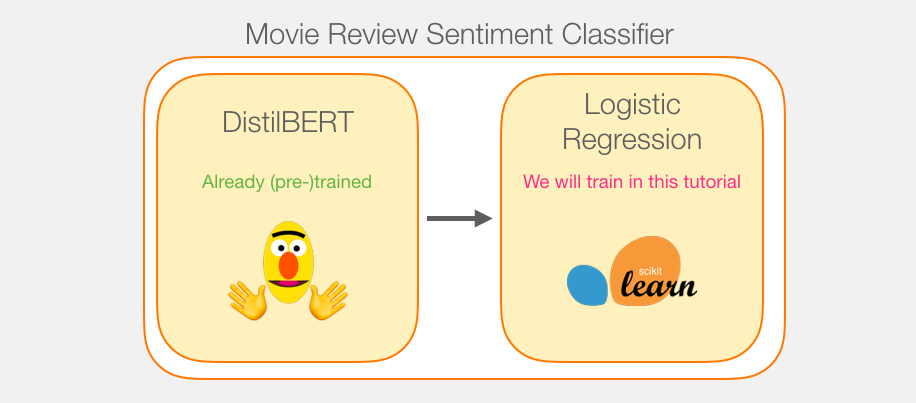
教程概述
我们首先使用训练好的distilBERT生成2000个句子的句嵌入。
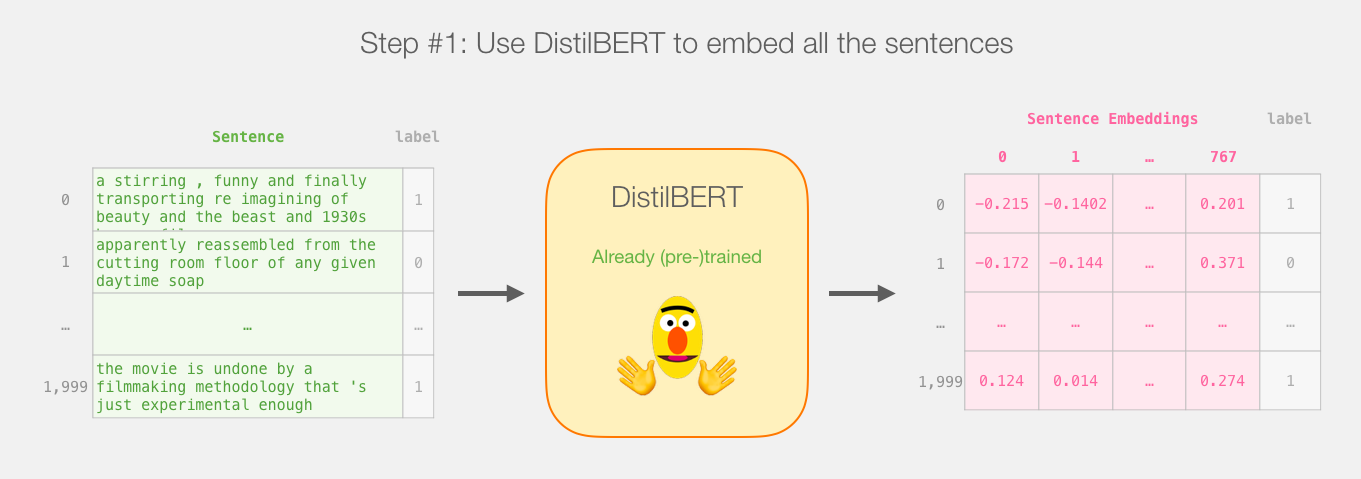
在这一步之后,我们将不再涉及distilBERT。我们在这个数据集上拆分训练/测试集。
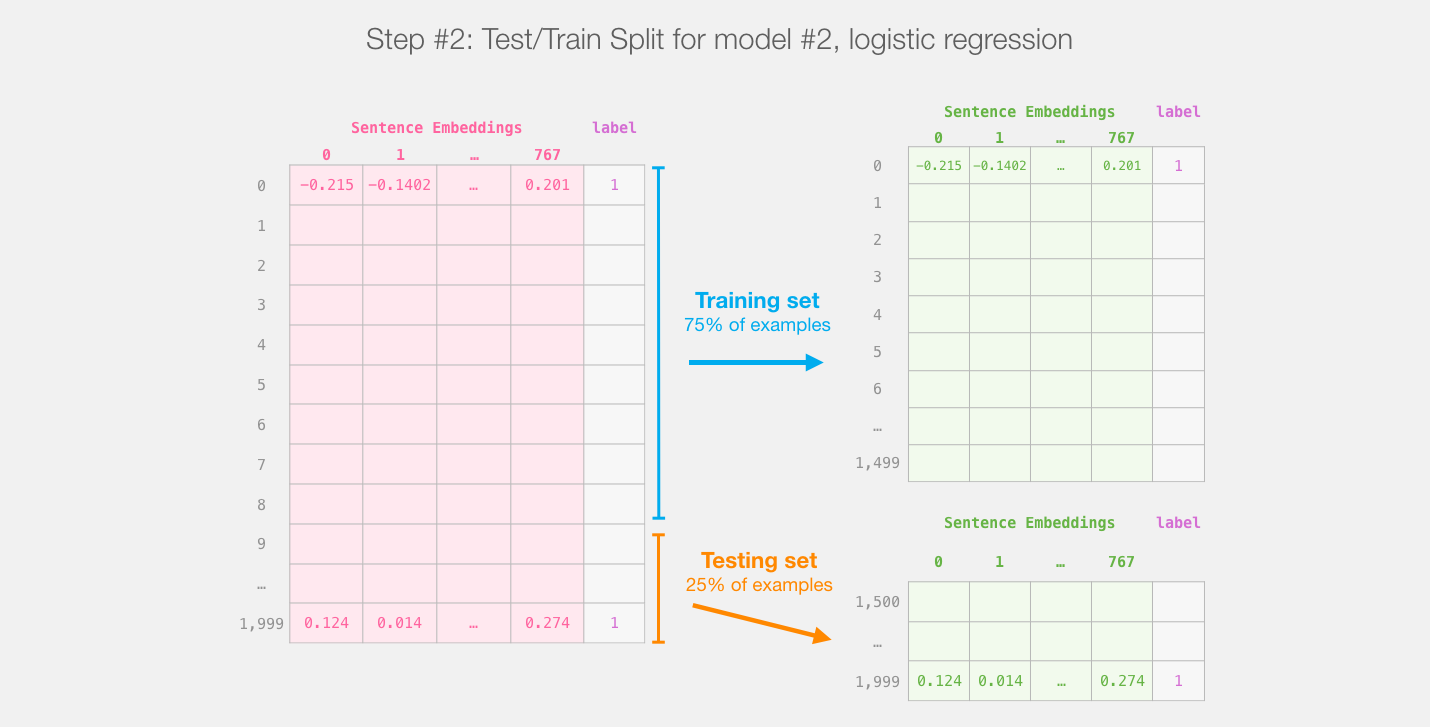
然后我们在训练集上训练逻辑回归:
如何进行预测?
在深入研究代码并解释如何训练模型之前,让我们先看看经过训练的模型如何进行预测。
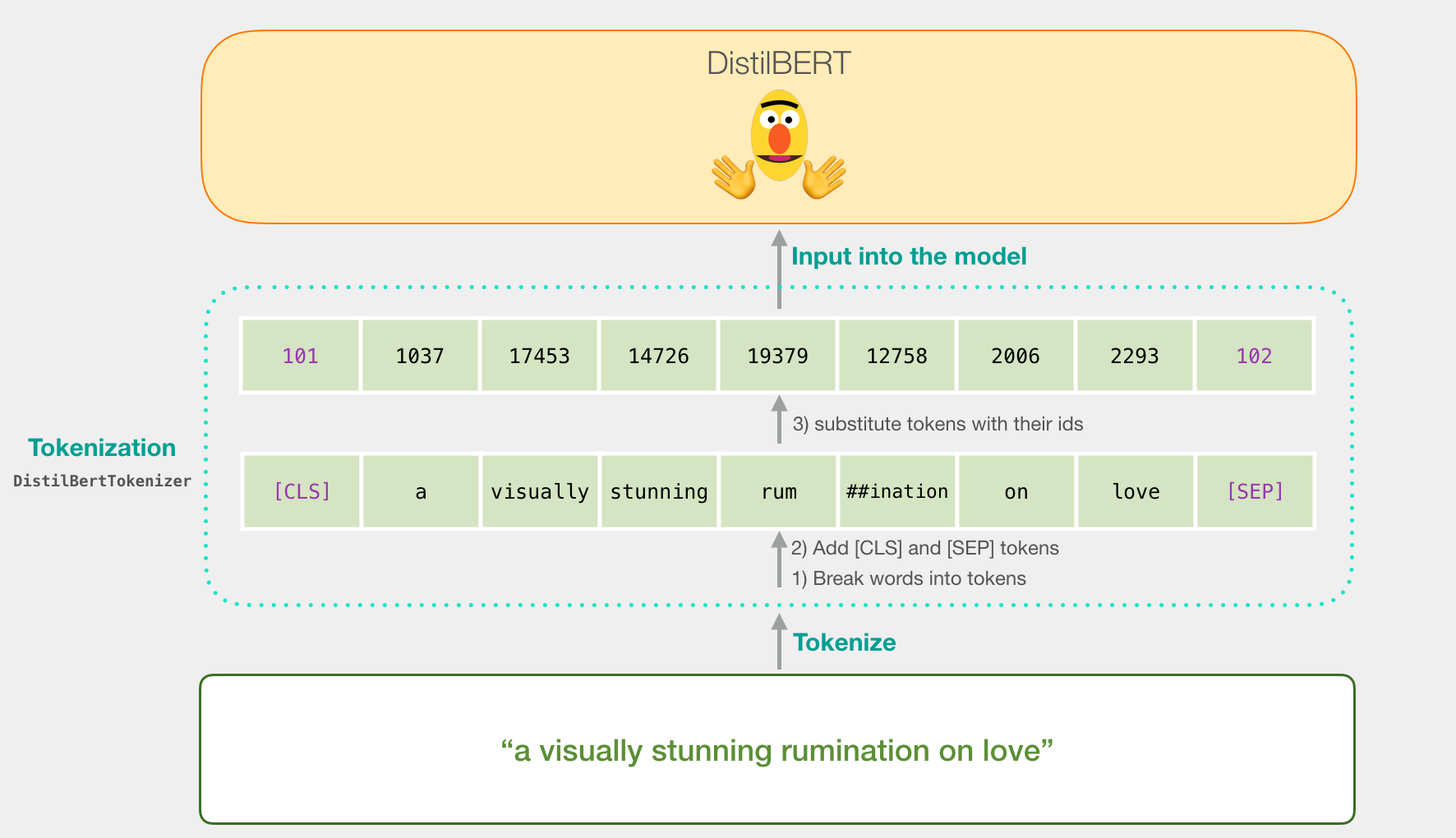
让我们试着分类一个句子‘ a visually stunning rumination on love ’。
第一步是将句子拆成token(就是把单词前后缀分离出来,统一loving 【lov,ing】loved【lov,ed】 这类单词的意思)。
然后我们在句子的开头加上CLS,结尾加上SEP。

第三步是将单词转换为词典索引。(阅读Word2Vec了解前置知识)

现在,让我们看一下代码(一行完成所有操作):
tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)
现在,我们的向量就可以直接传递给DistilBERT。
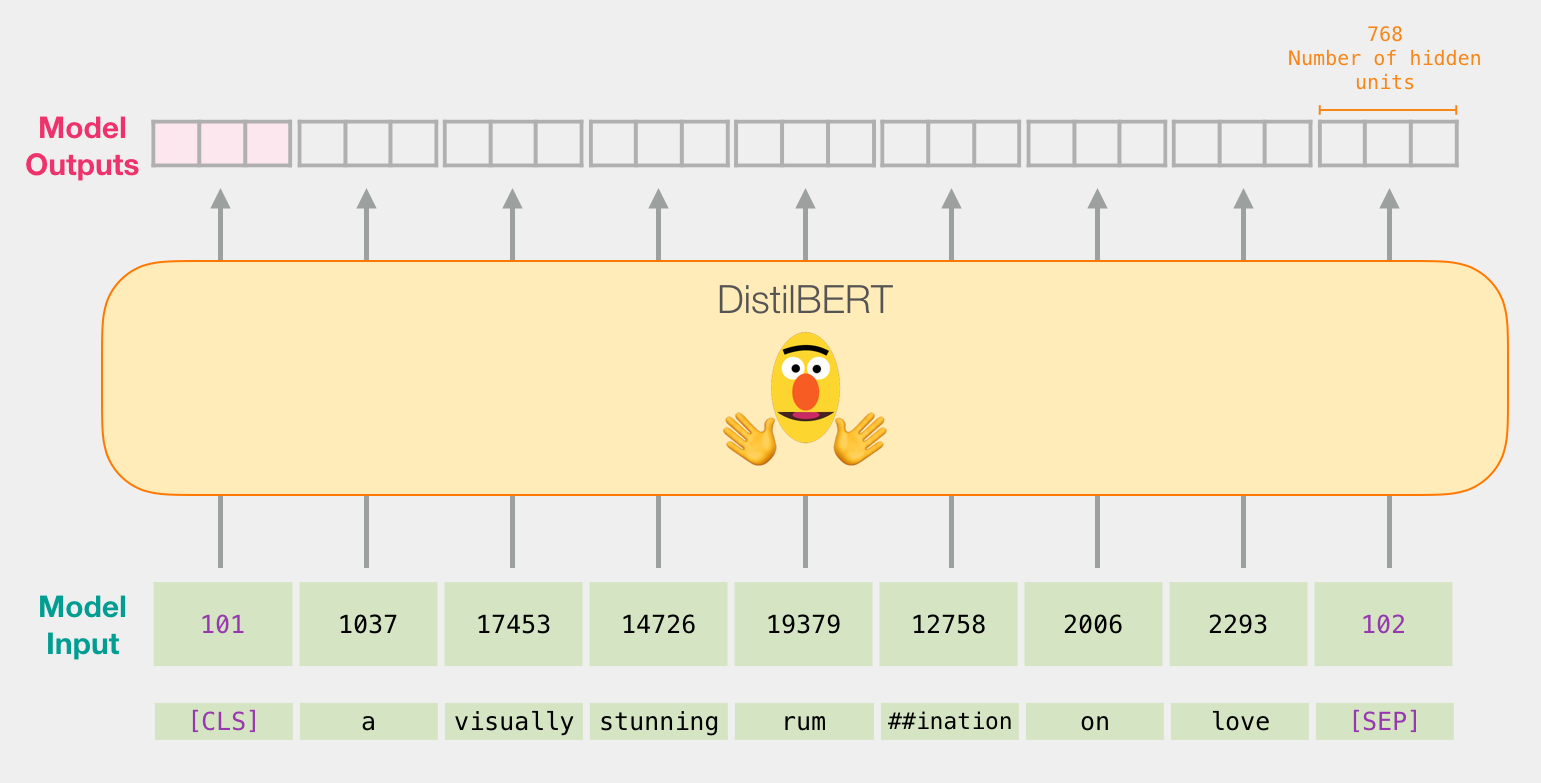
如果你读过BERT,这一步也可以用这种方法来描述:
DistilBERT
DistilBERT的结构与BERT类似。输出是一个向量,有768个浮点数组成。
因为这是一个句子 分类任务,因此可以忽略第一个向量(CLS),然后传入逻辑回归模型。
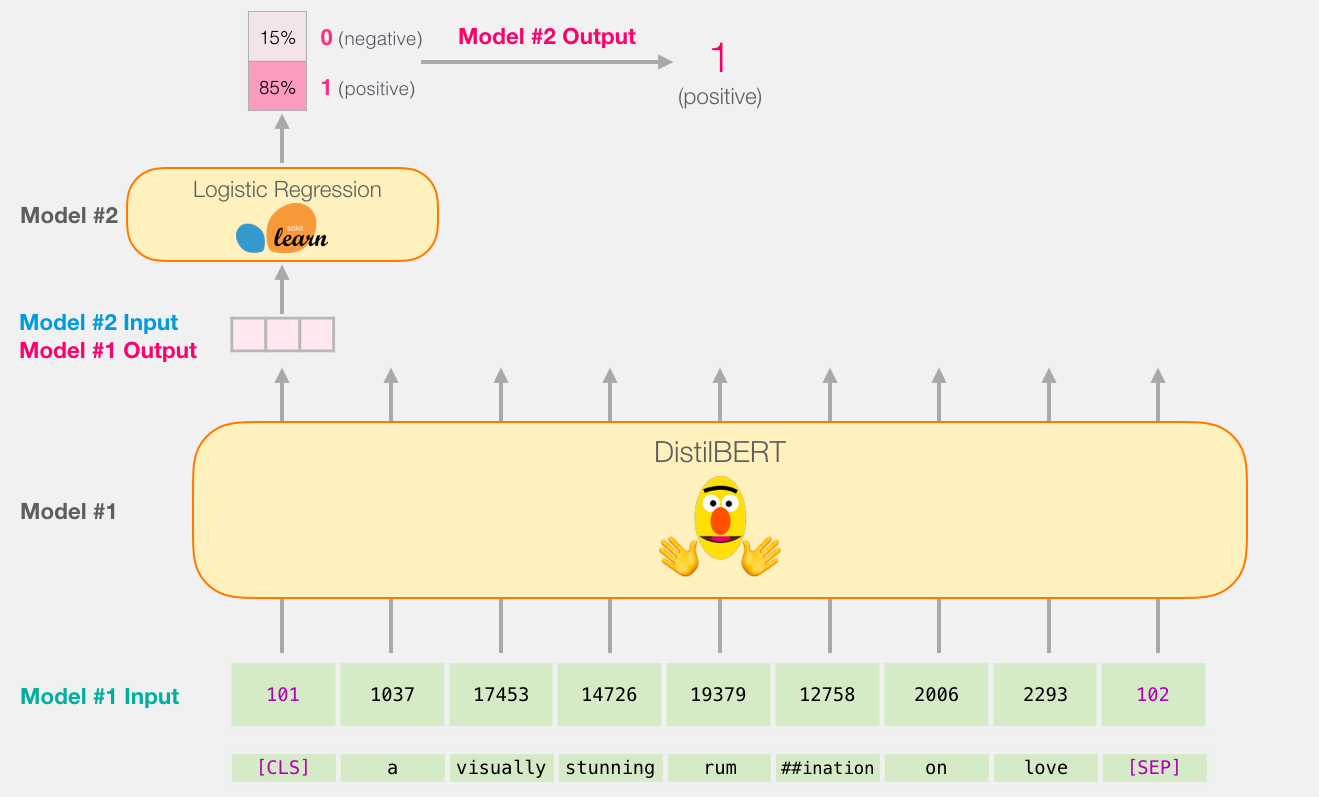
从这里开始,逻辑回归模型的工作就是根据它从训练阶段学到的知识(权重)对这个向量进行分类。我们可以把预测想象成这样:
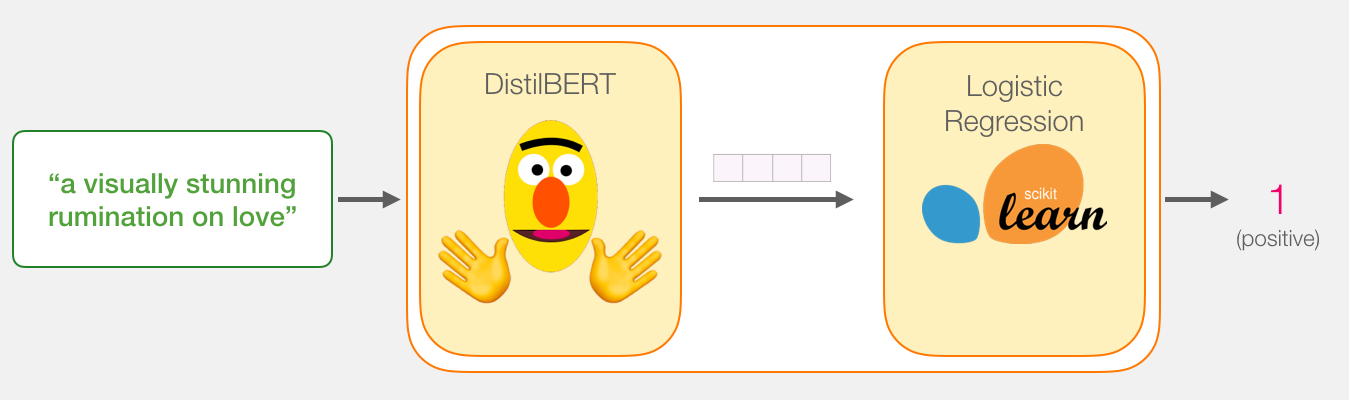
我们将在下一节中讨论整个过程的代码。
代码
他这个代码说实话不咋的,效果也不行,只有50左右的准确率。
不做搬运了,后期会出别的手写教程,这里原理懂了就得了。
翻译整理自:A Visual Guide to Using BERT for the First Time,Jay Alammar
0 条评论