2018年是机器学习模型处理文本(更准确的说是自然语言处理,NLP)的转折点。我们对于如何以最佳方式表达单词和句子的概念理解正在迅速发展,这种理解能够更好的捕捉句子的潜在含义和关系。此外,NLP社区已经提出了非常强大的组件,您可以免费下载它们并且应用在您自己的模型和管道上。(它被称为NLP领域的imageNet,参考多年前ImageNet是如何加入计算机视觉的发展的)。
最近的里程碑式发展是BERT(不存在的网址)的发布,该事件被描述为NLP新时代的开始。BERT模型在多个基于语言处理的任务中都打破了记录。在论文发布后不久,团队还开放了源代码,并提供了模型的权重文件,这些版本已经在大量的数据集上进行了 预训练。这是一个重大的发展,因为它使任何人都可以构建一个包含语言处理的机器学习模型,并将其作为一个现成组件使用——节省了从零开始训练语言模型所需的实践和精力以及资源。
最近很多的聪明的idea在NLP社区上出现,他们都使用了BERT——包括但不限于半监督序列学习、EMLo、ULMFiT、OpenAI transformer和Transformer。
要正确理解BERT是什么,我们需要了解很多概念。我们先来看看如何正确的使用BERT,然后我们再来看看模型本身涉及的概念。
例子:句子的分类
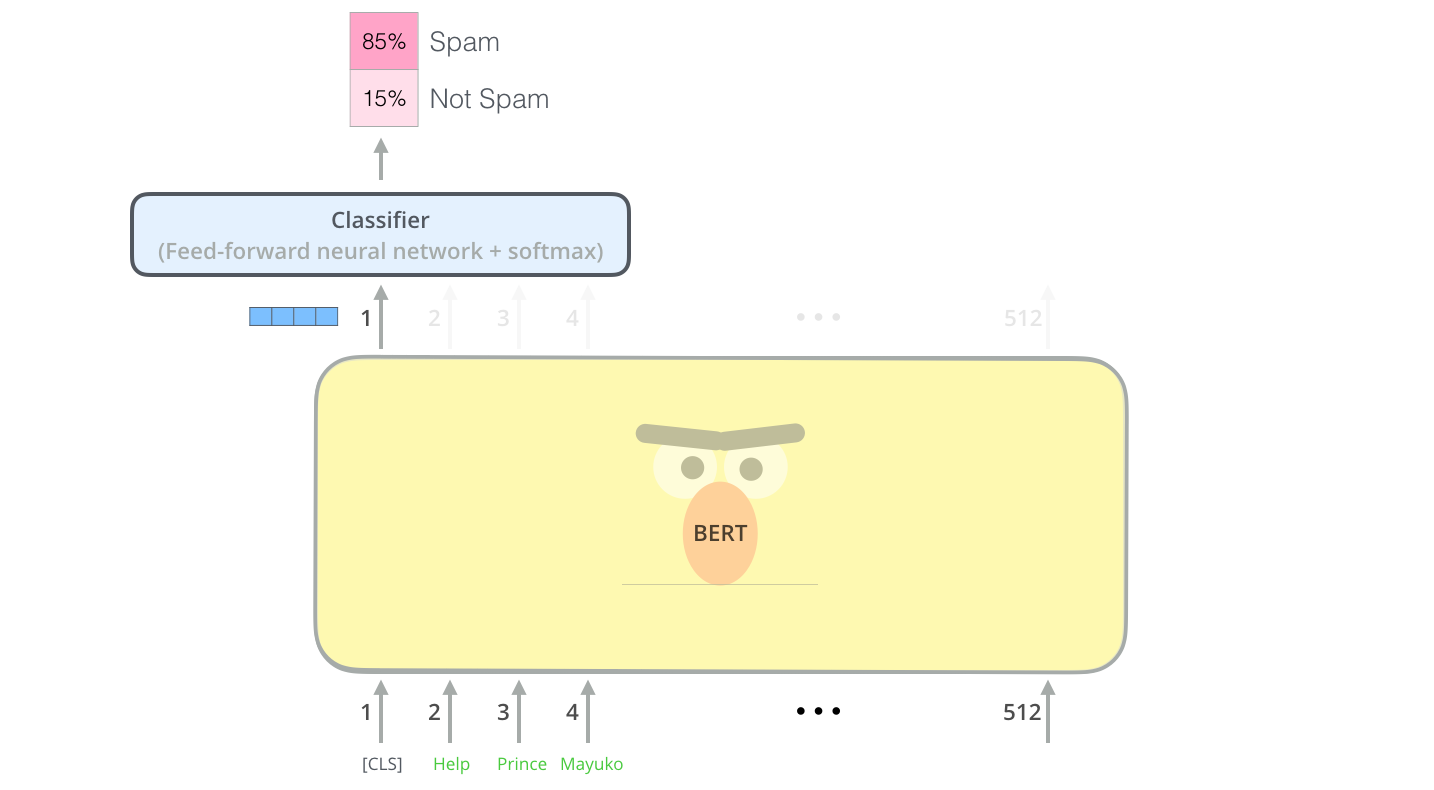
使用BERT的最直接的方法就是使用它对一段文本进行分类。这个模型是这样的:
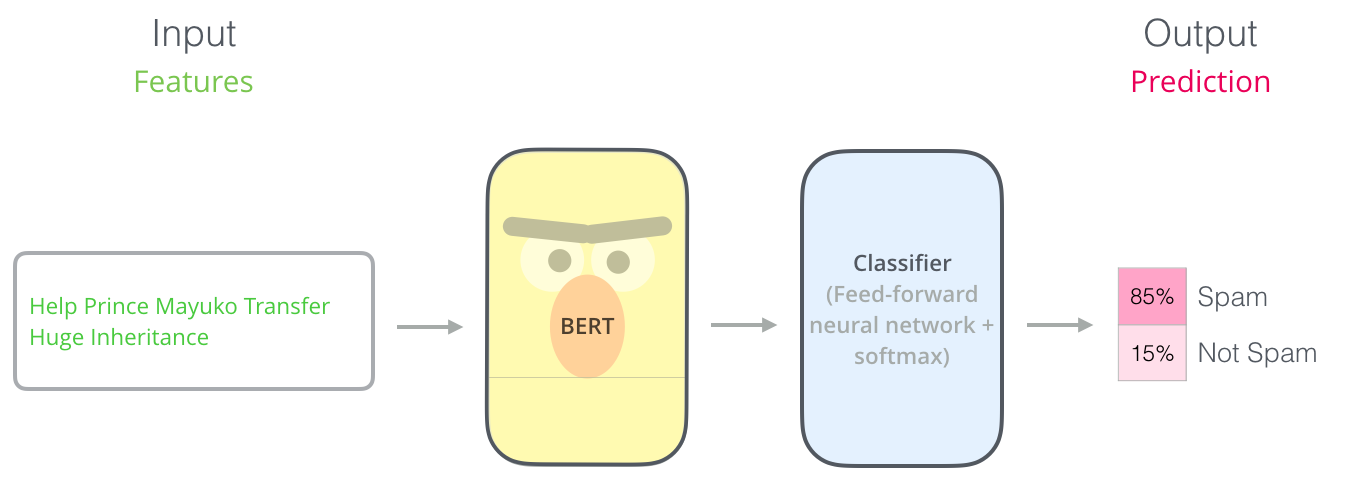
为了要训练一个这种的模型,你必须在训练阶段对BERT模型做最小的更改的情况下训练一个分类器。这个训练的过程被叫做微调(Fine-Tuning),其根源在于半监督序列学习和ULMFiT。
对于不熟悉这个话题的人,既然讨论分类器,那么我们就讨论监督的机器学习。这意味着我们需要一个标记的数据集来训练这样的模型。对于这个垃圾分类器示例,标记的数据及是将一个电子邮件消息和一个标签(spam或者not spam)。

这种的其他栗子包括:
情绪分析
输入:电影/产品评论。输出:评论是积极的还是消极的。(实例数据集SST)
真相检查(Fact-checking)
输入:句子。输出:Claim或者not Claim。
Full Fact是一个公益组织,他主要是用来自动检查事实的一个工具(谣言识别)。他们的pipeline能够识别新闻文章并将他们分类为claim或者not claim,这些标记随后将被检查(现在是人工,以后就是机器学习了)
视频,使用句嵌入来进行自动的谣言识别-Lev Konstantinovskiy (B站)。
模型结构
现在您知道了大概如何使用BERT,那么现在让我们看看它是如何工作的。

本文提出了两种大小的BERT:
- BERT BASE-和OpenAI Transformer大小差不多,目的是比较性能。
- BERT LARGE-一个巨大的模型,它达到了论文中提出的SOTA。
BART是一个经过训练的Transformer编码器。(Transformer详见前文,这里解释了什么是Transformer,它是BERT的基础,接下来我们将讨论这些概念)
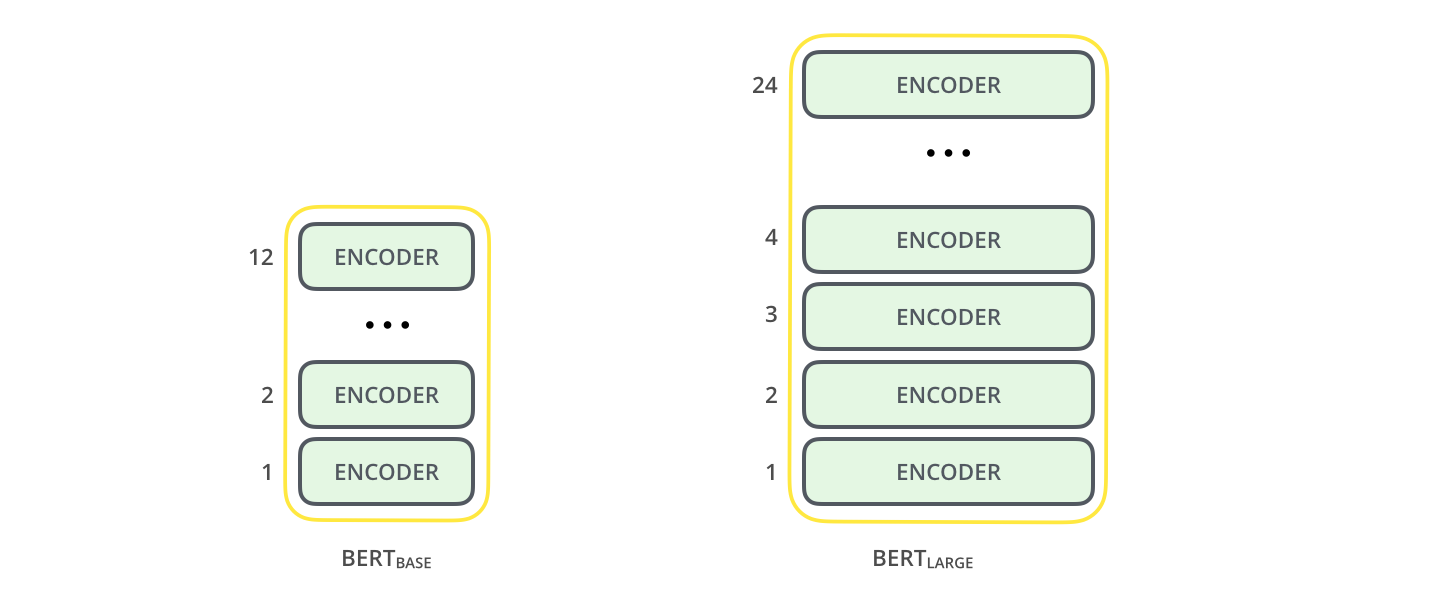
两种BERT模型都有大量的编码层(论文中称作Transformer块)——BASE版有12层,LARGE版有24层。他们也有一个前馈神经网络(BASE有768个隐藏单元,而LARGE有1024个)和多头注意力机制(BASE有12个,LARGE有16个),而不是Transformer中默认的6个编码层、512个隐藏单元和8头。
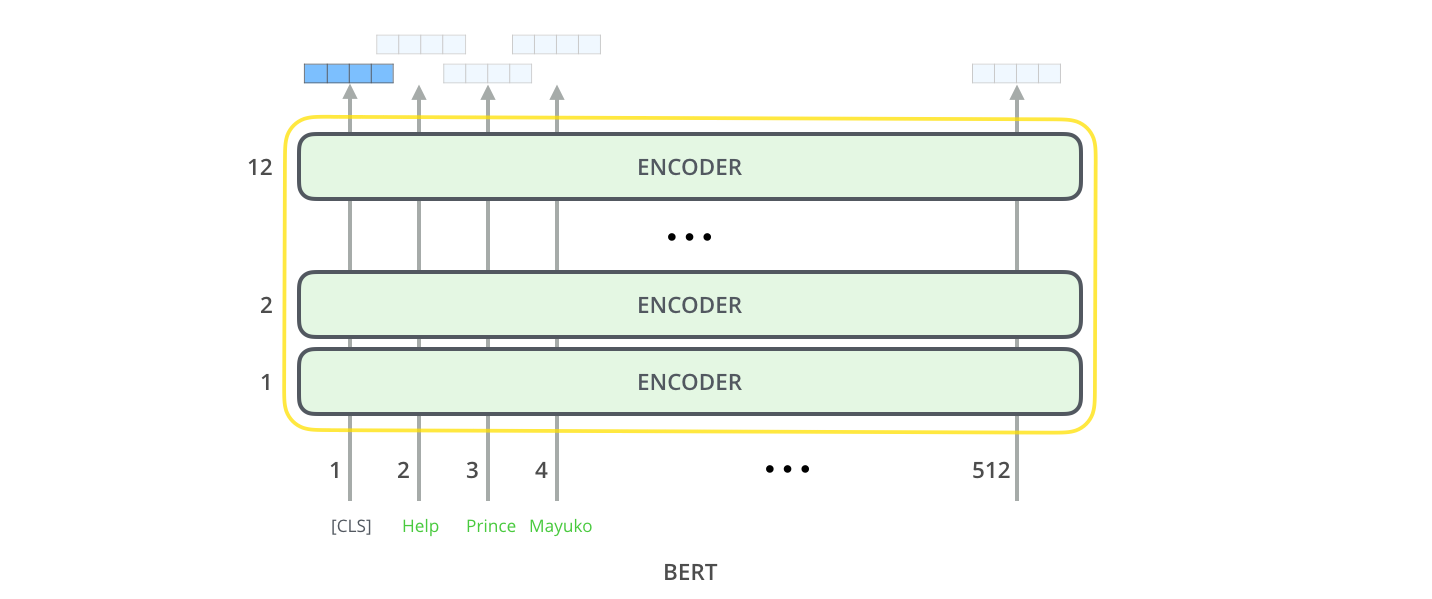
模型输入
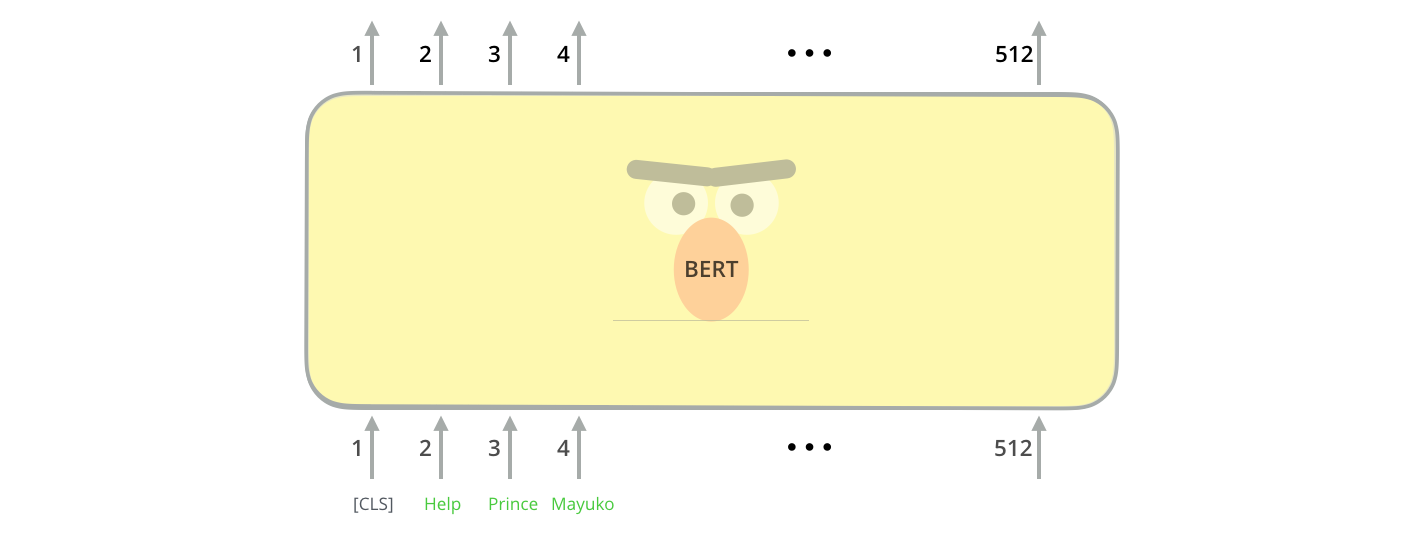
第一个输入是一个特殊的标记[CLS](输入句子以CLS开头),具体的原因将在稍后提到。CLS这里代表分类。
就像Transformer中的编码器一样,BERT将句子序列作为输入并在编码器栈中向上传播。每一层都使用了自注意力,然后将结果送入一个神经网络中,然后将他们交给下一个编码器。
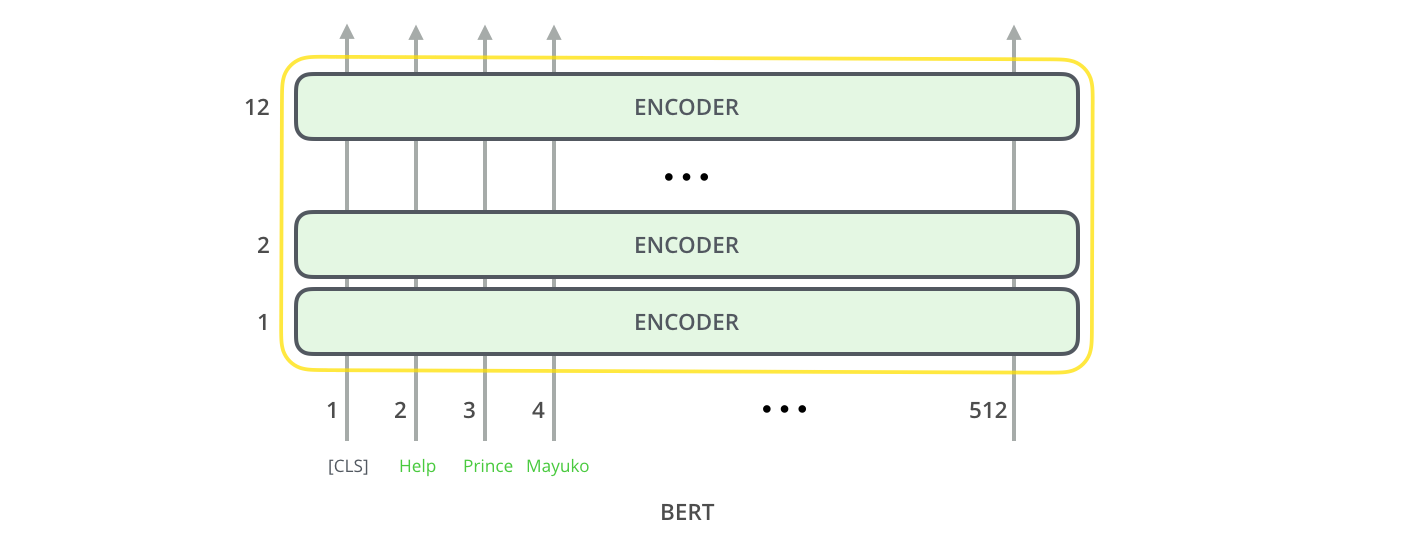
在这个结构中,这与Transformer是相同的(除了大小,这是我们能够设置的)。不一样的地方发生在输出的部分。
模型的输出
每个位置输出一个大小为hidden size的向量(BERT BASE为768)。对于上面我们提到的句子分类,我们只在遇到第一个位置时进行输出(这就是我们为什么要添加CLS标记)。
这个向量现在可以被用来进行分类,论文中采用了单层的神经网络来作为分类器,并且取得了一个比较好的效果。
如果你有更多的标签,你只需要调整神经网络分类器的输出,然后使用softmax即可。
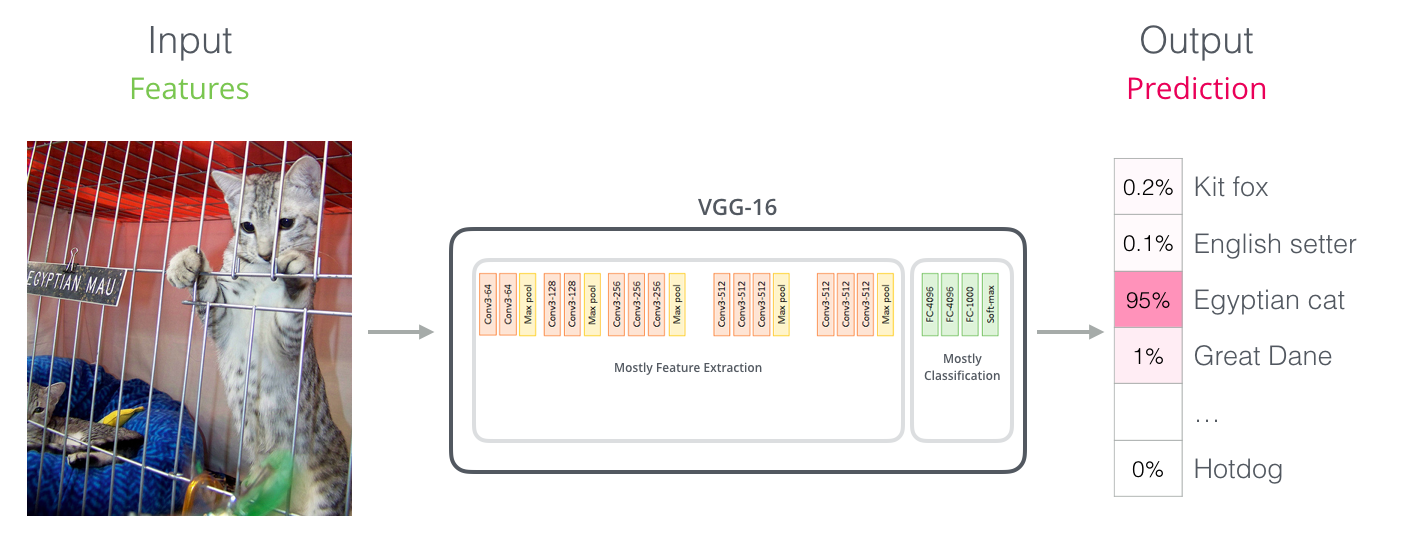
像卷积神经网络一样
对于那些具有计算机视觉的背景的人来说,这种向量传递应该会让他们想起VGGnet的网络的卷积部分和网络末端进行全连接然后进行分类。
一个新的嵌入时代
这个新发展带来了文字编码的一个新时代。到目前为止,词嵌入一直是NLP模型中的一个主力。像Word2Vec、Glove这些方法在很多任务中都有应用。让我们先来回顾一下这些内容。
词嵌入回顾
对于机器学习要处理的单词来说,他们需要以某种数字的形式来进行处理,以便模型能够在计算中使用。Word2Vec能够让我们使用一个向量来捕获单词的语义信息(包括语义、单词相似性、以及语法关系)。
人们很快的意识到,使用大量文本进行预训练是一个很好的办法。因此我们可以下载已经训练好的Word2Vec或者Glove词嵌入。下面是‘stick’的一个200维词嵌入。

因为比较大,下文中将使用袖珍版的向量。
ELMo:关注上下文
如果我们使用GloVe,那么stick这个单词就是上面那个词向量——无论它的上下文是什么样的。有些NLP研究者不禁说道,‘Wait a minute’,stick这个单词明明有很多意思啊,这取决于他使用的地方(上下文相关)。为什么不给他一个基于他所使用位置的上下文嵌入呢?这样既可以捕捉单词含义,还可以捕捉其他上下文信息。于是,语境化的词嵌入诞生了。

ELMo没有为每个单词分配固定的词嵌入,而是在为每个 单词分配词嵌入的时候查看完整的句子。它使用Bi-LSTM来创建这些嵌入。
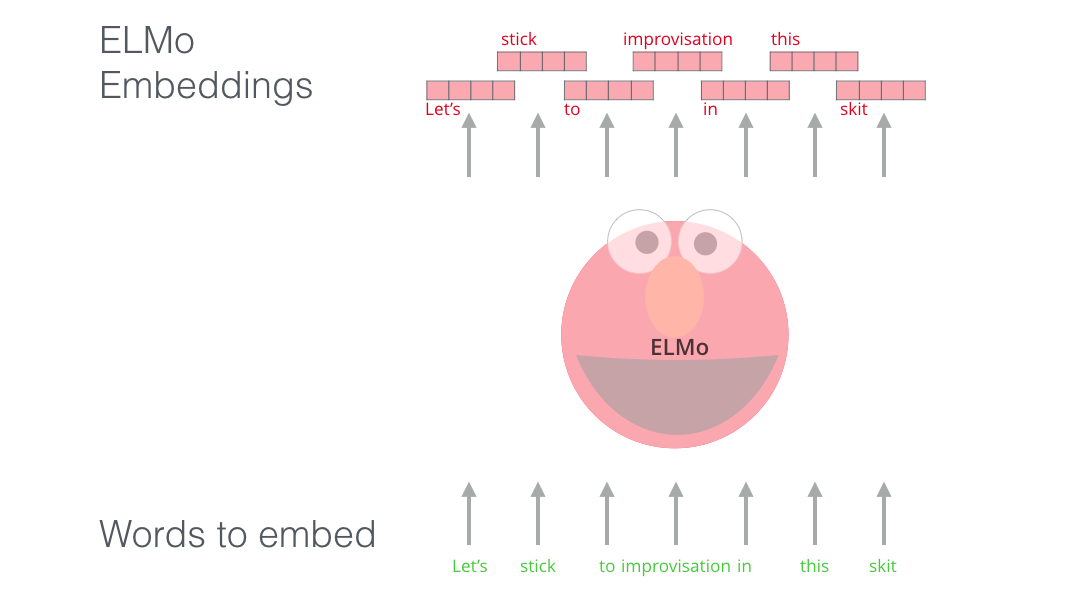
ELMo对于NLP领域的上下文预训练提供十分有意义。ELMo LSTM在大型数据集上进行预训练,然后我们可以在其他模型中将它作为其中一个组件。
ELMo的秘诀是什么?
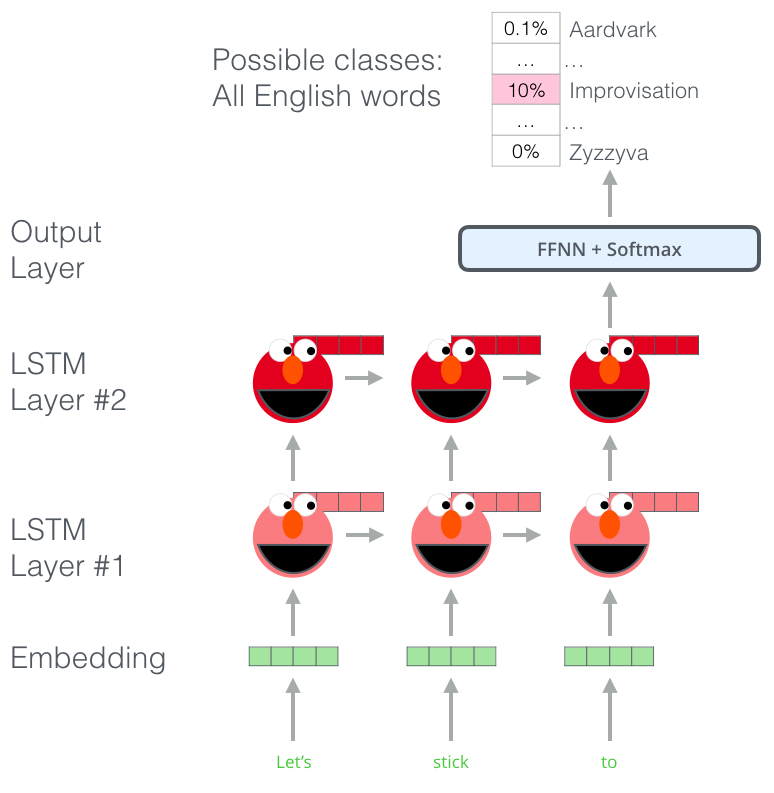
ELMo通过训练来对下一个单词进行预测从而获得语言理解能力,这项工作称为语言模型(Language Model)。我们有很多的文本数据,因此我们可以很方便的从这些数据中改进模型,并不需要使用标签。
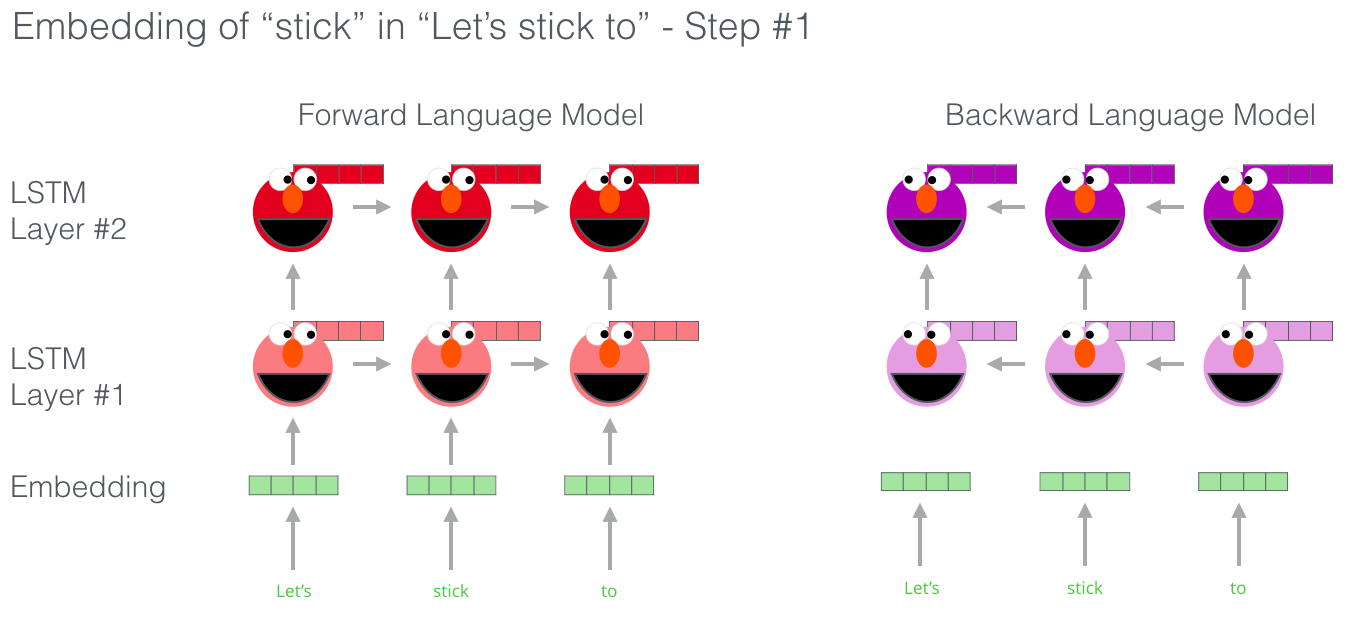
ELMo实际上更近了一步,训练了一个Bi-LSTM(双向LSTM),这样他的语言模型不仅有下一个单词的含义,还有上一个单词的含义。
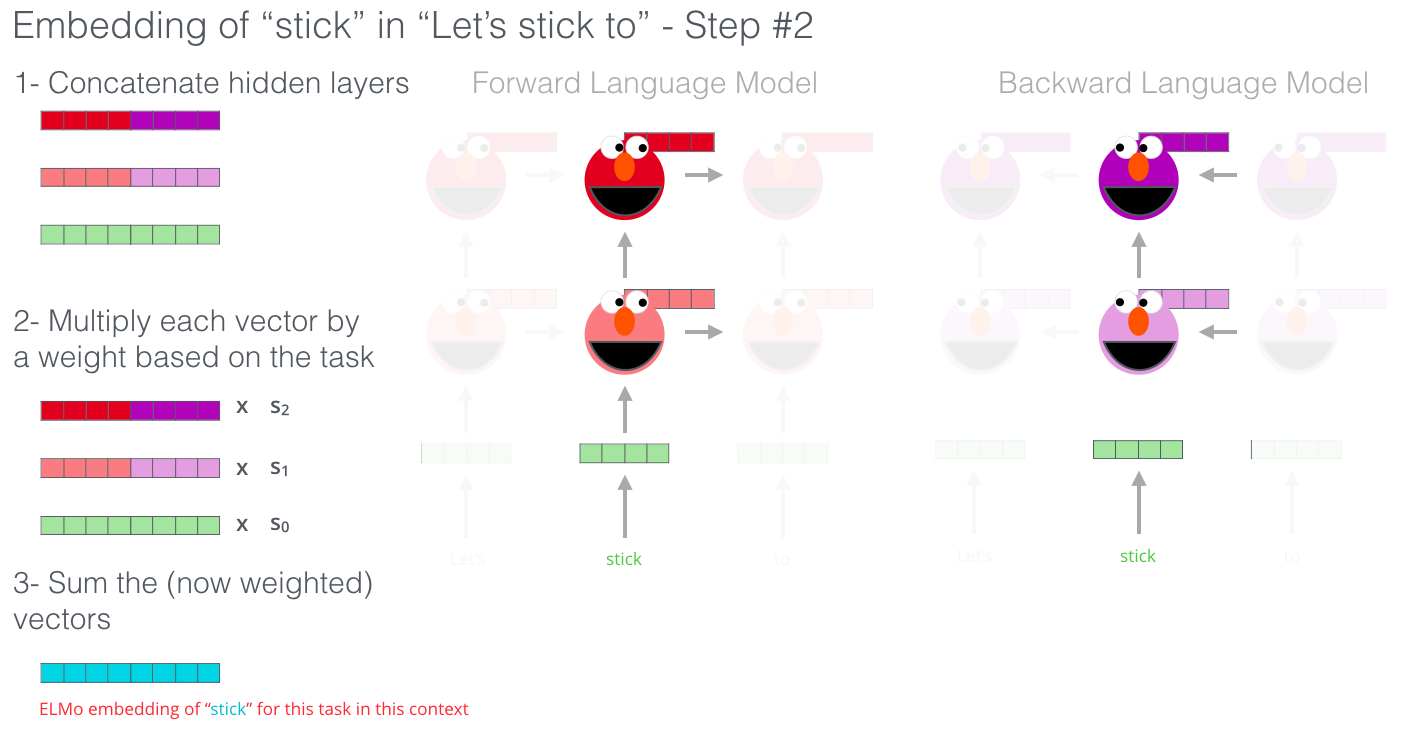
ELMo通过将隐藏状态(和初始状态)以某种方式分组(加权求和后串联),提出了上下文词嵌入。
ULM-FiT:NLP中的迁移学习
ULM-FiT是一个可以利用模型在预训练阶段学习到的知识的一种方法——不仅仅是词嵌入,也不仅仅是上下文嵌入。ULM-FiT介绍了一个语言模型和一个有效的微调过程,它可以完成多种任务。
NLP因此也获得了一个可以和计算机视觉一样的迁移训练的能力。
Transformer:超越LSTMs
Transformer的源码发布以及在机器繁育等领域上取得的成功,让很多业内人士认为它可以替代LSTMs。这是因为Transformer确实比LSTM牛逼。
编码器-解码器的结构非常适合机器翻译任务。但是怎样用来做文本分类呢?你怎样微调一个训练好的语言模型来做其他的任务呢(下游任务(downstream tasks)是运用训练好的模型进行监督学习)
OpenAI Transformer:对Transformer 编码器进行预训练
事实证明,对于NLP任务,我们并不需要对整个Transformer进行微调。我们可以只对解码器进行微调。
这个模型堆叠了12个解码层。由于没有设置编码器,这些解码器并不具备encoder-decoder attention 子层。但是它仍然有自注意力层(为了对当前处理位置隐藏当前位置之后的信息)
有了这个结构,我们可以继续在同一个语言模型上训练模型:预测下一个单词(未标注数据集)。我们需要做的只是把7000本书的文本扔给它,让它学习。书籍非常适合这类任务,因为即使被分割为很多段,模型依然可以从中学习到大量的有用信息。而tweets或者文章就没有这类效果。
下游任务的微调
现在,OpenAI Transformer已经预训练好了,让我们将它使用到下游任务中去吧。我们首先看一个句子分类的例子(判断邮件是不是垃圾邮件)
OpenAI论文中对于不同的任务做了不同的输入格式定义。下面这个图就是论文中对于不同的任务的不同输入。
这真是太聪明了。
BERT:编码器到解码器
OpenAI Transformer给我们提供了一个基于Transformer的可微调模型。但是在LSTM转换到Transformer的过程中有一些细节被遗漏了。ELMo是双向的,但是OpenAI Transformer是单向的,我们能否建立一个Transformer模型,使模型能够同时兼顾上下文。
遮蔽(Mask)语言模型
‘我们将使用Transformer 编码器’BERT说。
‘这太疯狂了’Ernie回复。‘大家都知道双向会让单词看到上下文’。
‘我们将使用遮蔽(Mask)’BERT自信地说。
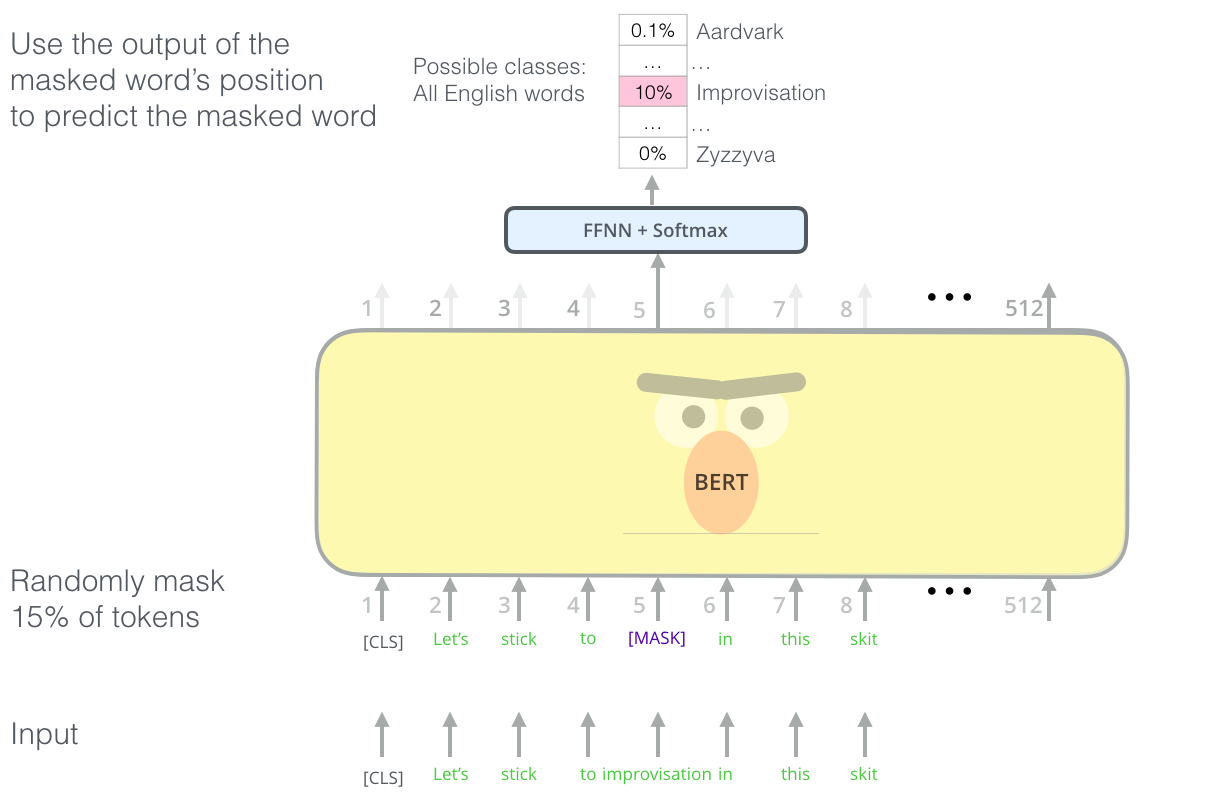
找到正确的目标来训练一个Transformer的编码器是很复杂的,BERT使用遮蔽语言模型的概念(完形填空)解决了这一问题。
除了15%的遮蔽,BERT还加入了其他的东西以改进模型微调后的性能。有时它会随机的将一个单词替换成另一个单词,并要求模型预测那个位置上正确的单词。
两句话任务
如果观察OpenAI对于多任务时不同的输入要求,你将会注意到有些任务需要模型能够对两句话进行一些智能化(比如两句话是否相似?一个句子能否作为另一个句子的回答?)
为了让BERT更好的处理多句问题,预训练过程也包括一个额外的任务:给定两个句子A和B,B是否可以是A后面的句子?

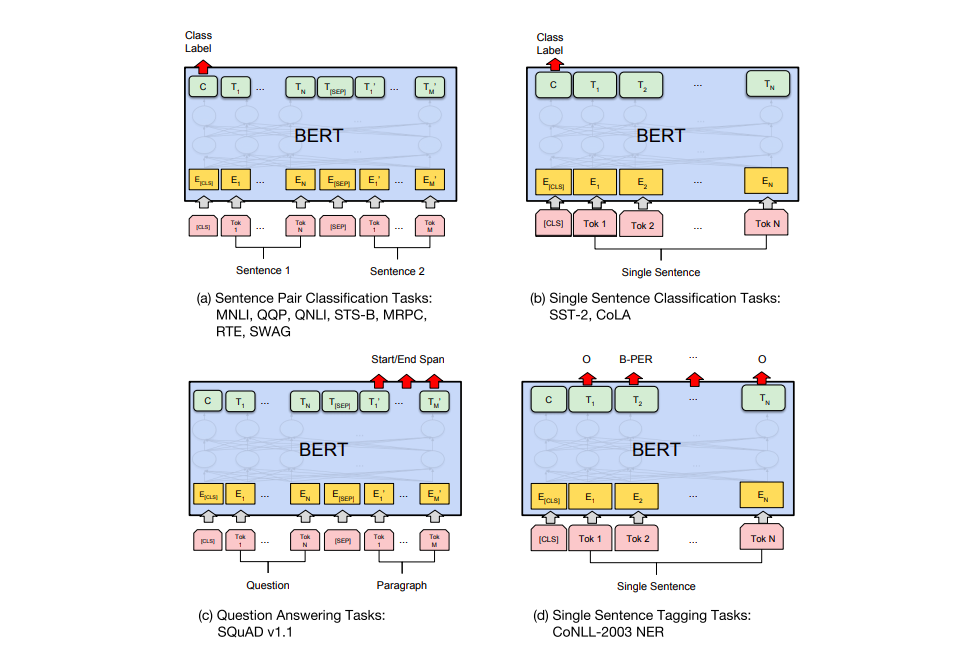
不同任务的具体模型
BERT的论文展示了在不同任务中使用BERT的几种方式
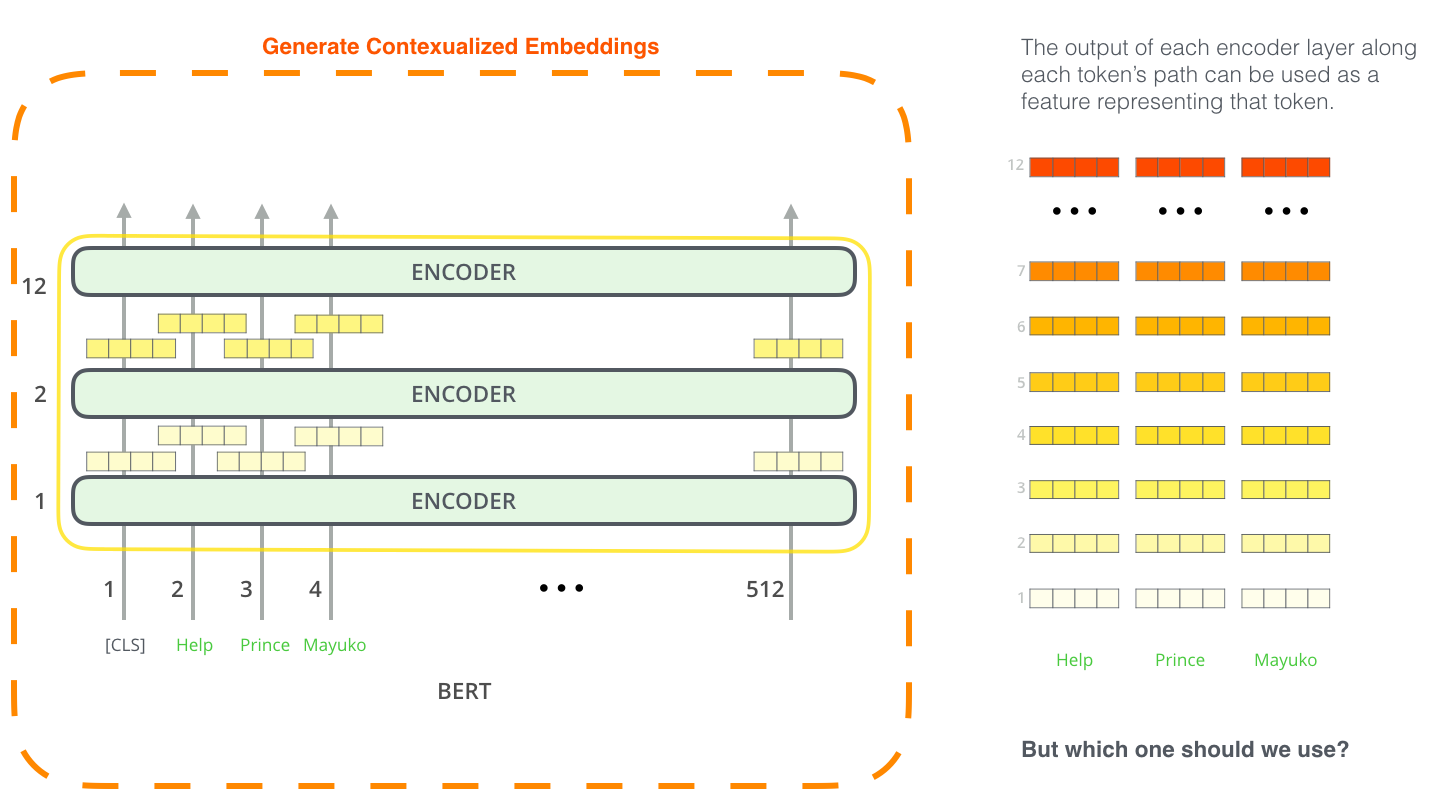
BERT用于特征提取
微调并不是使用BERT的唯一方式。就像ELMo,你可以使用预训练的BERT来获得上下文词嵌入。然后你可以将这个嵌入送入一个已经存在的模型——本文展示的任务(命名实体识别)与使用BERT微调的结果相差不大。
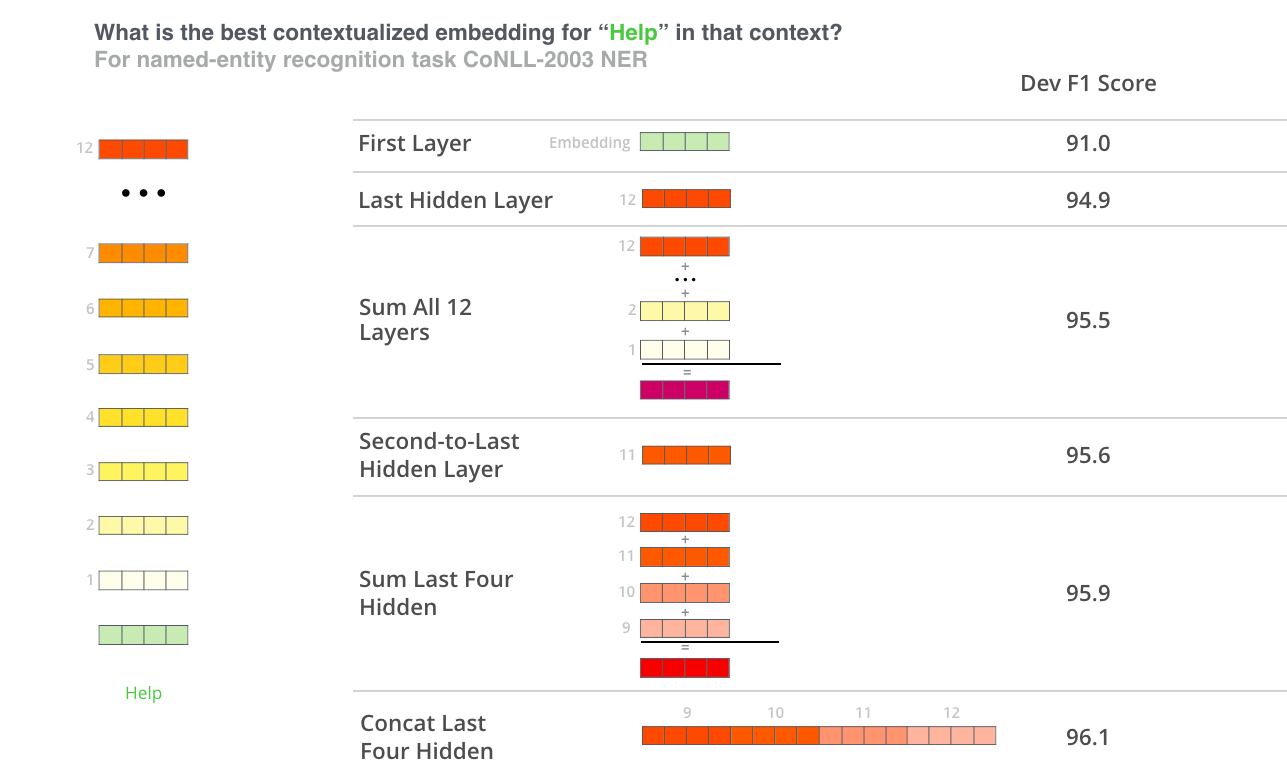
其中上下文嵌入的效果最好?我认为这取决于任务。本文考察了6个选项(与微调之后的96.4对比):
最好的方式来体验BERT是通过BERT FineTuning with Cloud TPUs(应该也是一个不存在的网站),如果你从没体验过Cloud TPUs,这也是一个很好的开始,当然,BERT也可以在GPU CPU上运行。
BERT的github库。
本文翻译整理自:The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning),Jay Alammar
0 条评论