吴恩达Machine-Learning 第九周:推荐系统(Recommender system)
推荐系统即通过用户对一些用户的打分而计算出用户可能感兴趣的其他东西。
我们使用两个变量,分别代表用户的喜好向量和电影的特征向量

我们使用这两个向量,就可以计算出用户对某一电影可能的评分,从而进行推荐。
那么我们怎么得到用户的参数向量和特征向量呢?我们使用协同过滤,在计算出theta和x向量:
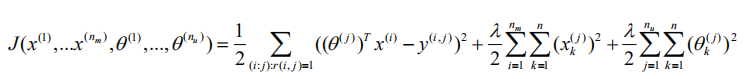
并计算导函数用来进行梯度下降:
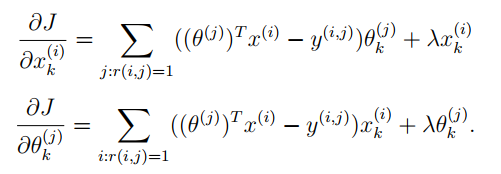
那么如果新增一个用户,我们为他推荐电影呢?
那我们就先计算一个已打分的平均值,再将数据都减去这个平均值,这样,我们将计算出来预测的分加上平均分作为预测的分,这样对于新用户,我们就可以为其推荐平均分最高的电影了。
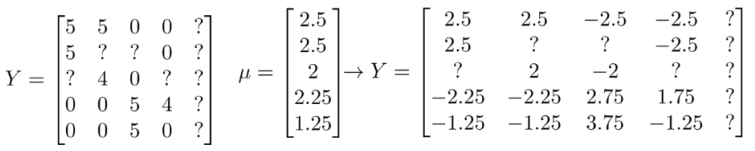
下面是代码:
首先导包:
import numpy as np
from scipy.io import loadmat
import matplotlib.pyplot as plt
import scipy.optimize as opt
导入和查看数据:
mat = loadmat('./data/ex8_movies.mat')
# dict_keys(['__header__', '__version__', '__globals__', 'Y', 'R'])
print(mat.keys())
# Y是不同电泳的不同用户评分,R代表用户i对电影j有是否有评分
Y, R = mat['Y'], mat['R']
movies_number, user_number = Y.shape
# (1682, 943) (1682, 943)
print(Y.shape, R.shape)
# # 计算一下用户0 的平均打分成绩 3.8783185840707963
print(Y[0].sum() / R[0].sum())
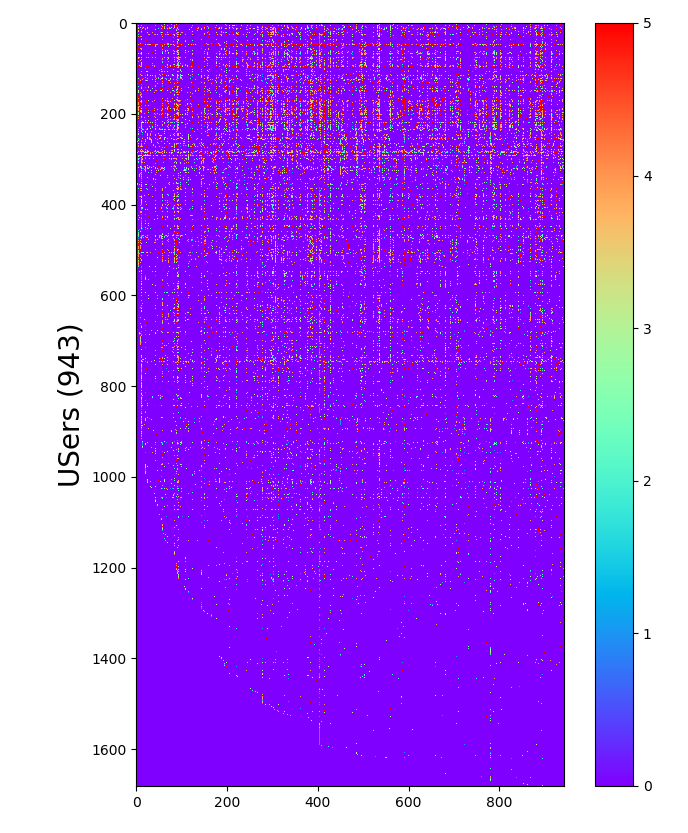
查看一下数据的样子:
# 显示一下Y矩阵的图示
fig = plt.figure(figsize=(8, 8 * (1682. / 943.)))
plt.imshow(Y, cmap='rainbow')
plt.colorbar()
plt.ylabel('Movies (%d)' % movies_number, fontsize=20)
plt.ylabel('USers (%d)' % user_number, fontsize=20)
下面是协同过滤,我们读取已经计算好的电影参数:
mat = loadmat('./data/ex8_movieParams.mat')
# dict_keys(['__header__', '__version__', '__globals__', 'X', 'Theta', 'num_users', 'num_movies', 'num_features'])
print(mat.keys())
X = mat['X']
Theta = mat['Theta']
num_users = int(mat['num_users'])
num_movies = int(mat['num_movies'])
num_features = int(mat['num_features'])
# 943 1682 10
print(num_users, num_movies, num_features)
# (1682, 10) (943, 10)
print(X.shape, Theta.shape)
为了快速的计算,我们先降低一下数据的维度:
# 降低一下数据的大小,目的是让程序运行的更快
num_users = 4
num_movies = 5
num_features = 3
X = X[:num_movies, :num_features]
Theta = Theta[:num_users, :num_features]
Y = Y[:num_movies, :num_users]
R = R[:num_movies, :num_users]
# (5, 3) (4, 3)
print(X.shape, Theta.shape)
然后是序列化和反序列化参数,作用是将Theta和X拼接(拆开):
def serialize(X, Theta):
"""
展开参数
:param X:每个电影的打分
:param Theta: 每个用户的专有电影参数?是这么说的么
:return:
"""
#
return np.r_[X.flatten(), Theta.flatten()]
def deserialize(seq, num_movies, num_users, num_features):
"""
提取参数
:param seq:
:param num_movies: 电影数量
:param num_users: 用户数量
:param num_features: 特征数量
:return:
"""
return seq[:num_movies * num_features].reshape(num_movies, num_features), seq[num_movies * num_features:].reshape(
num_users, num_features)
然后是计算代价函数:
def cofiCostFunc(params, Y, R, num_movies, num_users, num_features, l=0.0):
"""
代价函数
:param params: 一维后的参数(X,theta)
:param Y: 评分矩阵
:param R: 有无评分矩阵
:param num_movies: 电影数量
:param num_users: 用户数量
:param num_features: 特征数量
:param l: 正则化参数
:return:
"""
X, Theta = deserialize(params, num_movies, num_users, num_features)
# 计算
error = 0.5 * np.square((X @ Theta.T - Y) * R).sum()
# 对电影评分的正则化
reg1 = 0.5 * l * np.square(Theta).sum()
# 对电影参数的正则化
reg2 = 0.5 * l * np.square(X).sum()
return error + reg1 + reg2
输出两组结果看看:
# 22.224603725685675
print(cofiCostFunc(serialize(X, Theta), Y, R, num_movies, num_users, num_features))
# 31.34405624427422
print(cofiCostFunc(serialize(X, Theta), Y, R, num_movies, num_users, num_features, 1.5))
梯度下降函数:
def cofiGradient(params, Y, R, num_movies, num_users, num_features, l=0.0):
"""
计算X和Theta的梯度,并序列化输出
:param params:
:param Y:
:param R:
:param num_movies:
:param num_users:
:param num_features:
:param l:
:return:
"""
X, Theta = deserialize(params, num_movies, num_users, num_features)
X_grad = ((X @ Theta.T - Y) * R) @ Theta + 1 * X
Theta_grad = ((X @ Theta.T - Y) * R).T @ X + 1 * Theta
return serialize(X_grad, Theta_grad)
到这里我们已经具备运行推荐系统的能力了,下面我们模拟一个新用户:
# 读取电影列表
movies = []
with open('data/movie_ids.txt', 'r') as f:
for line in f:
movies.append(''.join(line.strip().split(' ')[1:]))
# 模拟一个用户的评分
my_ratings = np.zeros((1682, 1))
my_ratings[0] = 4
my_ratings[97] = 2
my_ratings[6] = 3
my_ratings[11] = 5
my_ratings[53] = 4
my_ratings[63] = 5
my_ratings[65] = 3
my_ratings[68] = 5
my_ratings[182] = 4
my_ratings[225] = 5
my_ratings[354] = 5
for i in range(len(my_ratings)):
if my_ratings[i] > 0:
print(my_ratings[i], movies[i])
输出上边模拟打分的电影:
"""
[4.] ToyStory(1995)
[3.] TwelveMonkeys(1995)
[5.] UsualSuspects,The(1995)
[4.] Outbreak(1995)
[5.] ShawshankRedemption,The(1994)
[3.] WhileYouWereSleeping(1995)
[5.] ForrestGump(1994)
[2.] SilenceoftheLambs,The(1991)
[4.] Alien(1979)
[5.] DieHard2(1990)
[5.] Sphere(1998)
"""
然后我们获取之前的电影矩阵,并将我们模拟的用户数据添加到矩阵尾部:
# 读取电影打分矩阵以及用户打分矩阵
mat = loadmat('data/ex8_movies.mat')
Y, R = mat['Y'], mat['R']
# (1682, 943) (1682, 943)
print(Y.shape, R.shape)
# 将新用户的打分添加进去
Y = np.concatenate((Y, my_ratings), axis=1)
R = np.concatenate((R, my_ratings != 0), axis=1)
num_movies, num_users = Y.shape
# 1682 944
print(num_movies, num_users)
# 设定特征向量为10个
num_features = 10
求平均分的函数:
def normallizeRatings(Y, R):
"""
计算打过分的电影的平均值
:param Y:
:param R:
:return:
"""
Ymean = (Y.sum(axis=1) / R.sum(axis=1)).reshape(-1, 1)
Ynorm = (Y - Ymean) * R
return Ynorm, Ymean
初始化Theta和X的参数,并进行梯度下降:
X = np.random.random((num_movies, num_features))
Theta = np.random.random((num_users, num_features))
params = serialize(X, Theta)
l = 10
res = opt.minimize(fun=cofiCostFunc, x0=params, args=(Y, R, num_movies, num_users, num_features, l), method='TNC',
jac=cofiGradient, options={'maxiter': 100})
ret = res.x
# [0.95054705 0.35474199 0.67897876 ... 0.23782728 0.76704132 0.79748087]
print(ret)
计算预测分数并输出结果:
fit_X, fit_Theta = deserialize(ret, num_movies, num_users, num_features)
# 计算预测分数
pred_mat = fit_X @ fit_Theta.T
# 预测分值+平均值
pred = pred_mat[:, -1] + Ymean.flatten()
pred_sorted_idx = np.argsort(pred)[::-1]
print("Top recommendations for you:")
for i in range(10):
print('Predicting rating %0.1f for movie %s.' \
% (pred[pred_sorted_idx[i]], movies[pred_sorted_idx[i]]))
"""
Top recommendations for you:
Predicting rating 9.8 for movie MayaLin:AStrongClearVision(1994).
Predicting rating 9.7 for movie Schindler'sList(1993).
Predicting rating 9.6 for movie PatherPanchali(1955).
Predicting rating 9.3 for movie KasparHauser(1993).
Predicting rating 9.3 for movie Faust(1994).
Predicting rating 9.2 for movie Trainspotting(1996).
Predicting rating 9.2 for movie SomeFolksCallItaSlingBlade(1993).
Predicting rating 9.2 for movie Prefontaine(1997).
Predicting rating 9.2 for movie BeautifulThing(1996).
Predicting rating 9.1 for movie GreatDayinHarlem,A(1994).
"""
print("\nOriginal ratings provided:")
for i in range(len(my_ratings)):
if my_ratings[i] > 0:
print('Rated %d for movie %s.' % (my_ratings[i], movies[i]))
"""
Original ratings provided:
Rated 4 for movie ToyStory(1995).
Rated 3 for movie TwelveMonkeys(1995).
Rated 5 for movie UsualSuspects,The(1995).
Rated 4 for movie Outbreak(1995).
Rated 5 for movie ShawshankRedemption,The(1994).
Rated 3 for movie WhileYouWereSleeping(1995).
Rated 5 for movie ForrestGump(1994).
Rated 2 for movie SilenceoftheLambs,The(1991).
Rated 4 for movie Alien(1979).
Rated 5 for movie DieHard2(1990).
Rated 5 for movie Sphere(1998).
"""
整理后的代码:
# -*- coding:utf-8 -*-
import numpy as np
from scipy.io import loadmat
import matplotlib.pyplot as plt
import scipy.optimize as opt
def load_movies():
"""
读取电影评论
:return:
"""
mat = loadmat('./data/ex8_movies.mat')
Y, R = mat['Y'], mat['R']
num_movies, num_users = Y.shape
return Y, R, num_movies, num_users
def load_params():
"""
读取电影参数
:return:
"""
mat = loadmat('./data/ex8_movieParams.mat')
X = mat['X']
Theta = mat['Theta']
num_users = int(mat['num_users'])
num_movies = int(mat['num_movies'])
num_features = int(mat['num_features'])
return X, Theta, num_movies, num_users, num_features
def load_movies_idx():
"""
读取电影列表
:return:
"""
movies = []
with open('data/movie_ids.txt', 'r') as f:
for line in f:
movies.append(''.join(line.strip().split(' ')[1:]))
return movies
def serialize(X, Theta):
"""
序列化参数
:param X:用户参数向量
:param Theta:电影特征向量
:return:
"""
return np.concatenate((X, Theta))
def deserialize(params, num_movies, num_users, num_features):
"""
反序列化
:param params: 参数
:param num_movies: 电影数量
:param num_users: 用户数量
:param num_features: 特征数量
:return:
"""
return params[:num_movies * num_features].reshape(num_movies, num_features), params[
num_movies * num_features:].reshape(
num_users, num_features)
def cofiCostFunc(params, Y, R, num_movies, num_users, num_features, l=0.0):
"""
:param params:
:param Y:
:param R:
:param num_movies:
:param num_users:
:param num_features:
:param l:
:return:
"""
X, Theta = deserialize(params, num_movies, num_users, num_features)
error = 0.5 * np.square((X @ Theta.T * Y) * R).sum()
reg_1 = 0.5 * np.square(Theta).sum()
reg_2 = 0.5 * np.square(X).sum()
return error + reg_1 + reg_2
def cofiGradient(params, Y, R, num_movies, num_users, num_features, l=0.0):
"""
梯度下降
:param params:
:param Y:
:param R:
:param num_movies:
:param num_users:
:param num_features:
:param l:
:return:
"""
X, Theta = deserialize(params, num_movies, num_users, num_features)
X_grad = ((X @ Theta.T - Y) * R) @ Theta + 1 * X
Theta_grad = ((X @ Theta.T - Y) * R).T @ X + 1 * Theta
return serialize(X_grad, Theta_grad)
def normallizeRatings(Y, R):
"""
求均值
:param Y:
:param R:
:return:
"""
return (Y.sum(axis=1) / R.sum(axis=1)).reshape(-1, 1)
if __name__ == '__main__':
Y, R, _, _ = load_movies()
# X, Theta, _, _, _ = load_params()
movies_idx = load_movies_idx()
# 模拟用户
my_ratings = np.zeros((1682, 1))
my_ratings[0] = 4
my_ratings[97] = 2
my_ratings[6] = 3
my_ratings[11] = 5
my_ratings[53] = 4
my_ratings[63] = 5
my_ratings[65] = 3
my_ratings[68] = 5
my_ratings[182] = 4
my_ratings[225] = 5
my_ratings[354] = 5
Y = np.concatenate((Y, my_ratings), axis=1)
R = np.concatenate((R, my_ratings != 0), axis=1)
num_movies, num_users = Y.shape
num_features = 10
X = np.random.random((num_movies, num_features))
Theta = np.random.random((num_users, num_features))
params = serialize(X, Theta)
Ymean = normallizeRatings(Y, R)
l = 10
res = opt.minimize(fun=cofiCostFunc, x0=params, args=(Y, R, num_movies, num_users, num_features, l),
jac=cofiGradient, method='TNC', options={'maxiter': 100})
ret = res.x
fit_X, fit_Theta = deserialize(ret, num_movies, num_users, num_features)
pred_mat = fit_X @ fit_Theta.T
pred = pred_mat[:, -1] + Ymean.flatten()
pred_sorted_idx = np.argsort(pred)[::-1]
print("Top recommendations for you:")
for i in range(10):
print('Predicting rating %0.1f for movie %s.' \
% (pred[pred_sorted_idx[i]], movies_idx[pred_sorted_idx[i]]))
0 条评论